Spire.Doc系列教程之根据分节符和分页符拆分 Word 文档
根据分节符拆分文档
//实例化Document对象Document document = new Document();//载入待拆分的Word文档document.LoadFromFile(@"测试文档.docx");Document newWord;for (int i = 0; i < document.Sections.Count; i++){ //每有一个section就创建一个新的文档 newWord = new Document(); //复制section内容到新文档 newWord.Sections.Add(document.Sections[i].Clone()); //保存文档 newWord.SaveToFile(String.Format(@"拆分结果分节符拆分的结果文档_{0}.docx", i)); }
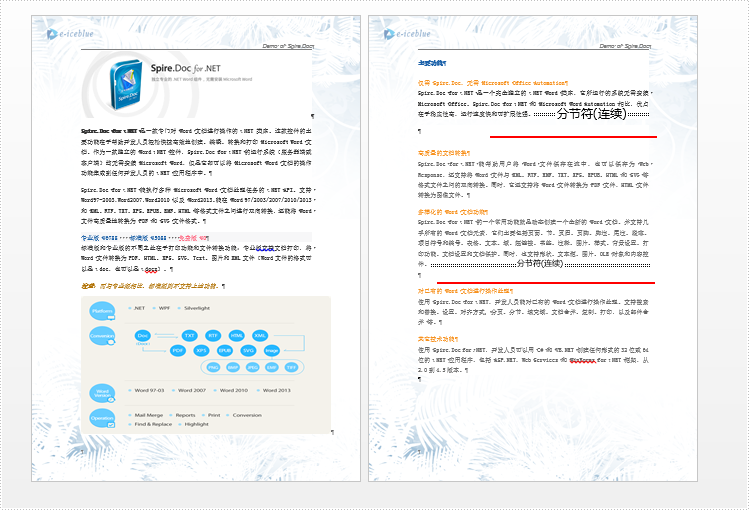
原文档如图,其中有两个分节符:

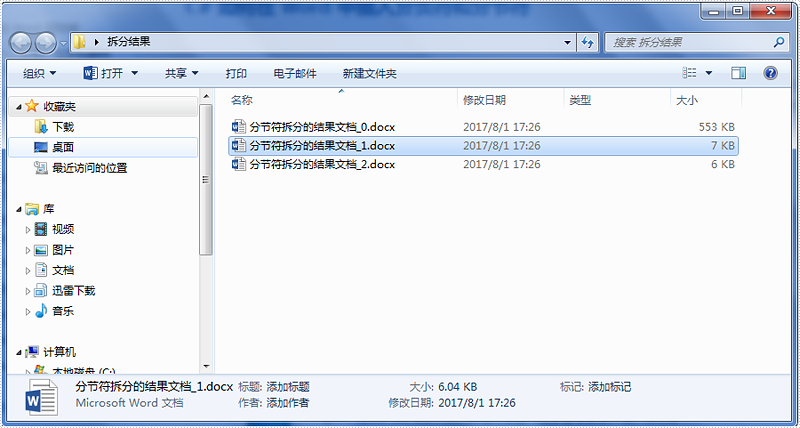
运行程序得到如下结果:
根据分页符拆分文档
//实例化Document对象Document original = new Document();//载入待拆分的Word文档original.LoadFromFile(@"C:UsersAdministratorDesktoptemplate.docx");//实例化一个新的文档并添加新章节Document newWord = new Document();Section section = newWord.AddSection();int index = 0;//根据章节,段落的层次由大到小依次遍历文档元素,复制内容到新的文档foreach (Section sec in original.Sections){ foreach (DocumentObject obj in sec.Body.ChildObjects) { if (obj is Paragraph) { Paragraph para = obj as Paragraph; section.Body.ChildObjects.Add(para.Clone()); foreach (DocumentObject parobj in para.ChildObjects) { //找到段落中的分页符,保存到新文档 if (parobj is Break && (parobj as Break).BreakType == BreakType.PageBreak) { int i = para.ChildObjects.IndexOf(parobj); section.Body.LastParagraph.ChildObjects.RemoveAt(i); newWord.SaveToFile(String.Format(@"C:UsersAdministratorDesktop拆分结果分页符拆分的结果文档_{0}.docx", index), FileFormat.Docx); index++; //一个文档完成之后新建一个文档 newWord = new Document(); section = newWord.AddSection(); //复制上一个分页符所在的段落的所有内容到新文档 section.Body.ChildObjects.Add(para.Clone()); //如果新文档第一段(也就是刚刚复制的那一段)没有子元素, //则把文档的第一个子元素删除 if (section.Paragraphs[0].ChildObjects.Count == 0) { section.Body.ChildObjects.RemoveAt(0); } else { //如果有内容则删除分页符之前的所有内容 while (i >= 0) { section.Paragraphs[0].ChildObjects.RemoveAt(i); i--; } } } } } if (obj is Table) { section.Body.ChildObjects.Add(obj.Clone()); } }}newWord.SaveToFile(String.Format(@"C:UsersAdministratorDesktop拆分结果分页符拆分的结果文档_{0}.docx", index), FileFormat.Docx);
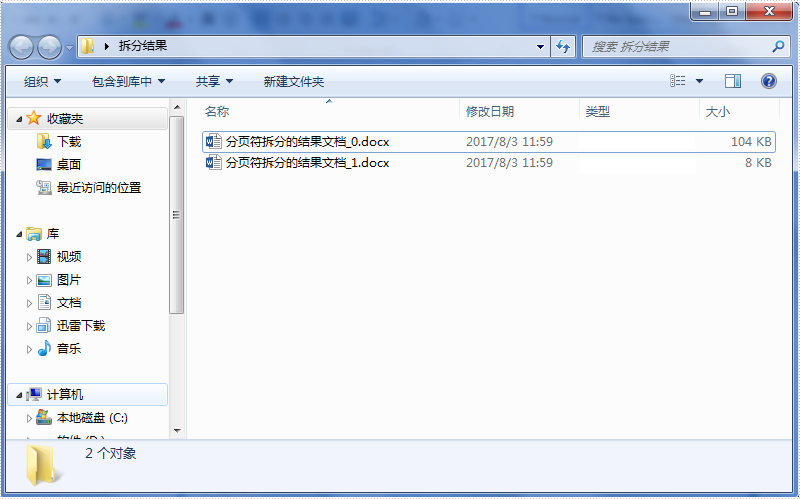
原文档如图,其中有一个分页符:

运行程序得到如下结果:
标签:文档管理Officeword文档处理工业4.0
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!