主要从0到1熟悉redis,之前也简单的介绍过redis,但是根本不够深入,这次深入的一起解析下这个redis。
- 总结
完全开源免费的、高性能的 key-value 数据库.支持数据持久化、支持多种数据结构存储。可能老铁都有感觉,系统比较慢,不是cpu和内存的问题,硬盘是机械的,如果换个固态效果很明显。为什么mac本那么快,新的mac本都是固态硬盘的。办公室有个机械硬盘的imac慢的一笔。
redis数据的存储:内存
mysql数据的村塾:硬盘
- 适用场景
适用场景:存储缓存、投票、会话 session、排行榜(如果是mysql,要使用order by,group by 才可以查询的到)、计数器、发布订阅等。
- Redis 单机版
在一台机器部署了redis应用。
特性
- 复制(Replication)扩展系统对于读的能力
- 哨兵(Sentinel) 为服务器提供高可用特性,减少故障停机出现
- 集群(Cluster) 扩展内存容量,增加机器,提高性能读写能力和存储以及提供高可用特性。 人多力量大,合理化的分工,分工明确,效率增加。
- 复制
Redis 的复制(replication)功能允许用户根据一个 Redis 服务器来创建任意多个该服务器的复制品,其中被复制的服务器为主服务器(master),而通过复制创建出来的服务器复制品则为从服务器(slave)。 只要主从服务器之间的 络连接正常,主从服务器两者会具有相同的数据,主服务器就会一直将发生在自己身上的数据更新同步 给从服务器,从而一直保证主从服务器的数据相同。
特点
- 保证高可用
- 监控各个节点
- 自动故障迁移
缺点:主从模式,切换需要时间丢数据没有解决 master 写的压力。
- 集群(proxy )
之前的情况都是有个proxy层,类型先过个nginx的代码。通过proxy层进行转向。负载均衡,分片来使用的。需要指定master。
特点
- 多种 hash 算法:MD5、CRC16、CRC32、CRC32a、hsieh、murmur、Jenkins。
- 支持失败节点自动删除。
- 后端 Sharding 分片逻辑对业务透明,业务方的读写方式和操作单个 Redis 一致。
缺点
- 增加了新的 proxy,需要维护其高可用。
- failover 逻辑需要自己实现,其本身不能支持故障的自动转移可扩展性差,进行扩缩容都需要手动干预。
- 集群(直连)
Redis 3.0的最重要特征是对Redis集群的支持,此外,该版本相对于2.8版本在性能、稳定性等方面都有了重大提高。类似zookeeper是通过选举来的。master自动指定的。
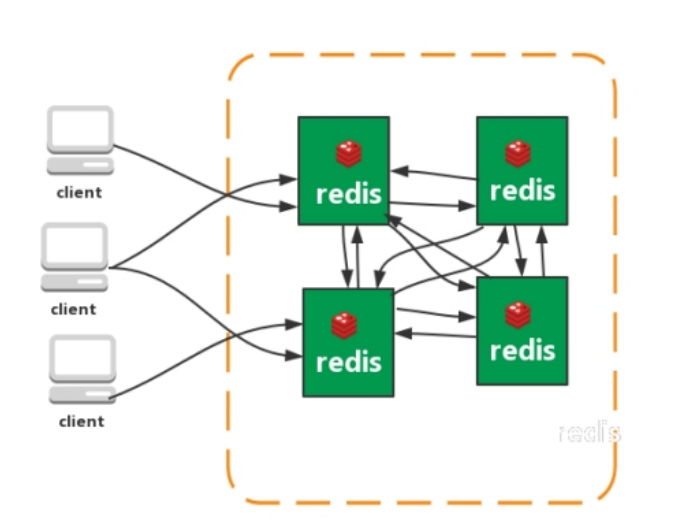

特点
- 无中心架构(不存在哪个节点影响性能瓶颈),少了 proxy 层。
- 数据按照 slot 存储分布在多个节点,节点间数据共享,可动态调整数据分布。
- 可扩展性,可线性扩展到 1000 个节点,节点可动态添加或删除。
- 高可用性,部分节点不可用时,集群仍可用。通过增加 Slave 做备份数据副本
- 实现故障自动 failover,节点之间通过 gossip 协议交换状态信息,用投票机制完成 Slave
到 Master 的角色提升。
缺点
- 资源隔离性较差,容易出现相互影响的情况,通过上边的图也是可以看到的,redis之前的关系很复杂。
- 数据通过异步复制,不保证数据的强一致性。
- 最低要求三主三从,不适合小公司。
- 自研型
国美:Gcache
京东:JimDB
PS:这次主要说说redis集群的理论,下次一起实践下。
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!