转自:http://blog.csdn.net/xceman1997/article/details/38423541
1. 斯坦福Richard Socher在EMNLP2014发表新作:GloVe: Global Vectors for Word Representation 粗看是融合LSA等算法的想法,利用global word co-occurrence信息提升word vector学习效果,很有意思,在word analogy task上准确率比word2vec提升了11%
http://www.socher.org/index.PHP/Main/GloveGlobalVectorsForWordRepresentation
2. 利用卷积神经 络做音乐推荐 Recommending music on Spotify with deep learning
http://benanne.github.io/2014/08/05/spotify-cnns.html
3. for deep learning fans: DEEP LEARNING An MIT Press book in preparation, by Yoshua Bengio, Ian Goodfellow and Aaron Courville
http://www.iro.umontreal.ca/~bengioy/dlbook/
4. Amund Tveit等维护了一个DeepLearning.University小项目:收集从2014年开始深度学习文献,相信可以作为深度学习的起点
http://memkite.com/deep-learning-bibliography/
https://github.com/memkite/DeepLearningBibliography
5. 深度学习、自然语言处理和表征方法
http://blog.jobbole.com/77709/
原文地址:http://article.yeeyan.org/view/22139/410514
这篇文章的确很难写,因为我希望它真正地对初学者有帮助。面前放着一张空白的纸,我坐下来问自己一个难题:面对一个对机器学习领域完全陌生的初学者,我该推荐哪些最适合的库,教程,论文及书籍帮助他们入门br>
资源的取舍很让人纠结,我不得不努力从一个机器学习的程序员和初学者的角度去思考哪些资源才是最适合他们的。
我为每种类型的资源选出了其中最佳的学习资料。如果你是一个真正的初学者,并且有兴趣开始机器学习领域的学习,我希望你能在其中找到有用的东西。我的建议是,选取其中一项资源,一本书,或者一个库,从头到尾的读一边,或者完成所有的教程。选定一个后坚持学习,等到完全掌握以后,再选取另一个资源按同样的方法学习。现在开始吧。
程序库
找一个库,先阅读其文档,然后就可以照着指南尝试做一些事情了。以下是最优秀的机器学习库开源代码。我并不认为这些库适用于你的工程项目,但是它们非常适合学习,开发及建模。
先选择一个你熟悉的语言对应的库,然后再尝试其他更功能强大的库。如果你是个很好的程序员,你应该知道你可以很容易的从一种语言切换到另一种语言。程序逻辑都是一样的,只是语法和API的区别而已。
R Project for Statistical Computing(用于统计计算的R工程):这是一个软件环境,采用类lisp脚本语言。提供了你想要的所有统计相关的东西,包括非常赞的绘图。CRAN(第三方机器学习包)的机器学习分类下有该领域专家们编写的代码,最新的接口方法和其他你能想到的功能都可以在上面找到。如果你想快速建模并开发,R工程是必学的。不过你不一定从一开始就从这个工程学起。
WEKA:数据挖掘平台,提供了API,一些命令行及整个数据挖掘生命周期的图像化用户接口。你可以准备数据,进行可视化开发,创建分类、回归、集群模型和很多内嵌及第三方组件提供的算法。如果你需要基于Hadoop平台工作,那么Mahout就是一个很好的机器学习Java框架,这个框架和和WEKA不相关。但如果你是大数据和机器学习的新手,那么还是坚持看WEKA,记得一次只学一样东西。
Scikit Learn:机器学习Python库,依赖Numpy和Scipy库。如果你是Python或者Ruby程序员,这个库比较合适。该库接口友好,功能强大,且有完善的文档支持。如果你想尝试其他东西,那么Orange将是一个不错的选择。
Octave:如果你熟悉MatLab或者你是Numpy程序员且正尝试寻找一些不一样的东西,那么可以考虑Octave。它提供了跟Matlab相似的数据计算环境,并且可以很简单的通过编程解决线性及非线性的问题,这些问题是大部分机器学习算法的基础。如果你有工程师背景,你可以从这里开始学起。
BigML:可能你不想做任何的编程,那么你可以全部使用工具,比如WEKA。你还可以更深一步并使用像BigML一样的服务,BigML提供了web版的机器学习接口,开发及创建模型可以全部在浏览器上完成。
选取其中一个平台用于机器学习的实战练习。不要只是看,要做。
视频课程
现在很流行通过观看视频来学习机器学习。我在YouTube和VideoLectures.NET上看了很多机器学习的视频,看视频的风险在于你很容易只是看而不会去实践。我建议在看视频的时候一定要做好笔记,即便之后你很快就会把笔记扔掉。同时建议你不管在学什么,一定要去动手尝试。
坦白来说,我看过的视频中,没有哪个视频是特别适合初学者的,我指真正的初学者。他们都是基于读者有最基本的线性代数和概率理论知识的假设。斯坦福大学Andrew Ng 的教程可能是最适合用于入门的了,另外,我推荐了一些一次性视频。
Stanford Machine Learning(斯坦福机器学习):通过Coursera可以获取到,Andrew Ng主讲。除了招生,你可以在任何时间看到所有的课程,并且从Stanford CS229 course(斯坦福CS229课程)上下载到所有的讲义和课堂笔记。课程包括家庭作业,测试。课程集中在线性代数上,使用Octave环境。
Caltech Learning from Data:可以在edX访问到,Yaser Abu-Mostafa主讲。所有的课程和材料在CalTech 站上都可以获取到。和斯坦福课程一样,你可以按你自己的节奏来完成家庭作业和任务。它覆盖了和斯坦福类似的课程,然后在细节上有一些深入,并且用了更多的数学方面的知识。家庭作业对初学者来说可能太难了。
Machine Learning Category on VideoLectures.Net(VideoLectures.Net上的机器学习分类):初学者很容易沉溺于海量的内容中。你可以找寻一些看起来比较有趣的视频,然后尝试看看。如果不是你现阶段能看懂的,就先放放。如果你看着合适,就记笔记。我发现我自己总是不断的找寻自己感兴趣的标签,然后最终选择了完全不同的标签。当然,看看该领域专家真正是什么样的也挺好的。
“Getting In Shape For The Sport Of Data Science” – Talk by Jeremy Howard:和一个本土R用户团队关于机器学习实践应用的对话,这个团队在机器学习竞赛中获取了很好的成绩。这个视频很有用,因为很少有人去讲将机器学习应用到一个项目中真正是什么样的,及怎么去做这个项目。我幻想着能创建一个 络真人TV秀,这样可以能直接看到选手机器学习竞赛中的表现。我是多么的向往啊。
论文概述
如果你不习惯读研究性论文,你将会发现他们的语言非常枯燥。论文像是教科书的片段,但是论文描述了实验,或者是该领域其他前沿研究。不过,如果你正要开始学习机器学,这里有一些论文可能会引起你的兴趣。
A Few Useful Things to Know about Machine Learning(一些你必须知道的关于机器学习的事):这是一篇好论文,因为它不拘泥于特定的算法,而是偏向于比如特征选取概述和模型简化这些重要的问题上。走对方向并且从一开始就想清楚,都是很好的事情。
上面我只罗列了两篇重要的论文,因为读论文会真的让你陷入困境。
机器学习初学者书籍
市面上有很多机器学习的书,但很少有针对初学者编写的。什么才是真正的初学者能是从其他领域转入机器学习的,也可能是从计算机科学,软件编程或者统计学转入的。即使这样,大部分的书籍都会认为你至少已经有了线性代数和概率论的知识背景。
然而,这里还是有一些书鼓励有兴趣的程序员从一个最小的算法开始学习,指定工具和库,这样编程人员就可以运行程序并得出结果。最著名的有Programming Collective Intelligence(中文版:《集体智慧编程》)、Machine Learning for Hackers(中文版《机器学习:实用案例解析》)和Data Mining: Practical Machine Learning Tools and Techniques(中文版《数据挖掘:实用机器学习技术》),以上三本分别基于Python,R和Java三种语言。如果有不懂的地方,可以参见这三本书。
[](http://machinelearningmastery.com /wp-content/uploads/2013/11/photo.jpg)
Programming Collective Intelligence(中文版:《集体智慧编程》):创建精巧的web 2.0应用:这本书是专门为编程人员写的,轻理论,重实战,有大量的代码示例,实际上遇到的web问题及对应的解决方案。买这本书的读者,建议边读边做练习!
Machine Learning for Hackers(中文版:《机器学习:使用案例解析》):我建议在读完Programming Collective Intelligence以后再来读这本书。该书同样提供了大量的实用性很强的案例。但是它有更多数据分析的东西并且使用R语言。我真心喜欢这本书。
Machine Learning: An Algorithmic Perspective:这本书像是Programming Collective Intelligence的升级版。这两本书的目标相同(帮助程序员入门),但是这本书包含了数学和参考文献,同时也有用Python写的示例和代码片段。我建议读者先看Programming Collective Intelligence,如果看完以后还有兴趣,再来看这本书。
Data Mining: Practical Machine Learning Tools and Techniques, Third Edition(中文版:《数据挖掘:实用机器学习技术》):实际上我是从这本书开始学起的,2000年的第一版。当时我还是个java程序员,由于WEKA库提供了很好的开发环境,我利用这本书结合WEKA库进行尝试,用自己的算法做了插件并作了大量的机器学习应用,同时延伸到数据挖掘部分。因此我强力推荐这本书和这种学习方法。
Machine Learning(中文版:《机器学习》):这本书比较老,包含了公式和很多的参考文献。虽然是本教科书,但是每个算法的实用性依然非常强。
很多人能列举出很多优秀的机器学习教科书,我也可以。这些书的确很棒,只是个人觉得对初学者来说不太好入门而已。
扩展阅读
这篇文章经过我仔细推敲,为了确保自己没有漏掉任何一点重要的东西,我同时也看了其他人列出的资源。为了使内容更全面,这里再列出一些 上其他优秀的机器学习入门资源列表。
What are some good resources for learning about machine learningWhy这个问答的第一个答案很不错,每次读我都会做笔记并打上标签。这个答案里面最有价值的部分是机器学习课程的笔记列表及Q&A页面的相关文章列表。
Overwhelmed by Machine Learning: is there an ML101 book一个StackOverflow上的帖子,上面确实列出了很多推荐的机器学习书籍列表,第一个回帖的是Jeff Moser,罗列了很多课程视频和谈话。
你是否已经看过或者用过这些资源呢觉得怎么样/span>
我不知道我是否为有兴趣学习机器学习的程序员提供了真正有用的资源,有任何问题和建议,请留下宝贵留言!
原文地址:http://licstar.NET/archives/328
Posted on 2013 年 7 月 29 日
这篇博客是我看了半年的论文后,自己对 Deep Learning 在 NLP 领域中应用的理解和总结,在此分享。其中必然有局限性,欢迎各种交流,随便拍。
Deep Learning 算法已经在图像和音频领域取得了惊人的成果,但是在 NLP 领域中尚未见到如此激动人心的结果。关于这个原因,引一条我比较赞同的微博。
@王威廉:Steve Renals算了一下icassp录取文章题目中包含deep learning的数量,发现有44篇,而naacl则有0篇。有一种说法是,语言(词、句子、篇章等)属于人类认知过程中产生的高层认知抽象实体,而语音和图像属于较为底层的原始输入信 ,所以后两者更适合做deep learning来学习特征。
2013年3月4日 14:46
第一句就先不用管了,毕竟今年的 ACL 已经被灌了好多 Deep Learning 的论文了。第二句我很认同,不过我也有信心以后一定有人能挖掘出语言这种高层次抽象中的本质。不论最后这种方法是不是 Deep Learning,就目前而言,Deep Learning 在 NLP 领域中的研究已经将高深莫测的人类语言撕开了一层神秘的面纱。
我觉得其中最有趣也是最基本的,就是“词向量”了。
将词用“词向量”的方式表示可谓是将 Deep Learning 算法引入 NLP 领域的一个核心技术。大多数宣称用了 Deep Learning 的论文,其中往往也用了词向量。
0. 词向量是什么
自然语言理解的问题要转化为机器学习的问题,第一步肯定是要找一种方法把这些符 数学化。
NLP 中最直观,也是到目前为止最常用的词表示方法是 One-hot Representation,这种方法把每个词表示为一个很长的向量。这个向量的维度是词表大小,其中绝大多数元素为 0,只有一个维度的值为 1,这个维度就代表了当前的词。
举个栗子,
“话筒”表示为 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 …]
“麦克”表示为 [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 …]
每个词都是茫茫 0 海中的一个 1。
这种 One-hot Representation 如果采用稀疏方式存储,会是非常的简洁:也就是给每个词分配一个数字 ID。比如刚才的例子中,话筒记为 3,麦克记为 8(假设从 0 开始记)。如果要编程实现的话,用 Hash 表给每个词分配一个编 就可以了。这么简洁的表示方法配合上最大熵、SVM、CRF 等等算法已经很好地完成了 NLP 领域的各种主流任务。
当然这种表示方法也存在一个重要的问题就是“词汇鸿沟”现象:任意两个词之间都是孤立的。光从这两个向量中看不出两个词是否有关系,哪怕是话筒和麦克这样的同义词也不能幸免于难。
Deep Learning 中一般用到的词向量并不是刚才提到的用 One-hot Representation 表示的那种很长很长的词向量,而是用 Distributed Representation(不知道这个应该怎么翻译,因为还存在一种叫“Distributional Representation”的表示方法,又是另一个不同的概念)表示的一种低维实数向量。这种向量一般长成这个样子:[0.792, .177, .107, 0.109, .542, …]。维度以 50 维和 100 维比较常见。这种向量的表示不是唯一的,后文会提到目前计算出这种向量的主流方法。
(个人认为)Distributed representation 最大的贡献就是让相关或者相似的词,在距离上更接近了。向量的距离可以用最传统的欧氏距离来衡量,也可以用 cos 夹角来衡量。用这种方式表示的向量,“麦克”和“话筒”的距离会远远小于“麦克”和“天气”。可能理想情况下“麦克”和“话筒”的表示应该是完全一样的,但是由于有些人会把英文名“迈克”也写成“麦克”,导致“麦克”一词带上了一些人名的语义,因此不会和“话筒”完全一致。
1. 词向量的来历
Distributed representation 最早是 Hinton 在 1986 年的论文《Learning distributed representations of concepts》中提出的。虽然这篇文章没有说要将词做 Distributed representation,(甚至我很无厘头地猜想那篇文章是为了给他刚提出的 BP 络打广告,)但至少这种先进的思想在那个时候就在人们的心中埋下了火种,到 2000 年之后开始逐渐被人重视。
Distributed representation 用来表示词,通常被称为“Word Representation”或“Word Embedding”,中文俗称“词向量”。真的只能叫“俗称”,算不上翻译。半年前我本想翻译的,但是硬是想不出 Embedding 应该怎么翻译的,后来就这么叫习惯了-_-||| 如果有好的翻译欢迎提出。Embedding 一词的意义可以参考维基百科的相应页面(链接)。后文提到的所有“词向量”都是指用 Distributed Representation 表示的词向量。
如果用传统的稀疏表示法表示词,在解决某些任务的时候(比如构建语言模型)会造成维数灾难[Bengio 2003]。使用低维的词向量就没这样的问题。同时从实践上看,高维的特征如果要套用 Deep Learning,其复杂度几乎是难以接受的,因此低维的词向量在这里也饱受追捧。
同时如上一节提到的,相似词的词向量距离相近,这就让基于词向量设计的一些模型自带平滑功能,让模型看起来非常的漂亮。
2. 词向量的训练
要介绍词向量是怎么训练得到的,就不得不提到语言模型。到目前为止我了解到的所有训练方法都是在训练语言模型的同时,顺便得到词向量的。
这也比较容易理解,要从一段无标注的自然文本中学习出一些东西,无非就是统计出词频、词的共现、词的搭配之类的信息。而要从自然文本中统计并建立一个语言模型,无疑是要求最为精确的一个任务(也不排除以后有人创造出更好更有用的方法)。既然构建语言模型这一任务要求这么高,其中必然也需要对语言进行更精细的统计和分析,同时也会需要更好的模型,更大的数据来支撑。目前最好的词向量都来自于此,也就不难理解了。
这里介绍的工作均为从大量未标注的普通文本数据中无监督地学习出词向量(语言模型本来就是基于这个想法而来的),可以猜测,如果用上了有标注的语料,训练词向量的方法肯定会更多。不过视目前的语料规模,还是使用未标注语料的方法靠谱一些。
词向量的训练最经典的有 3 个工作,C&W 2008、M&H 2008、Mikolov 2010。当然在说这些工作之前,不得不介绍一下这一系列中 Bengio 的经典之作。
2.0 语言模型简介
插段广告,简单介绍一下语言模型,知道的可以无视这节。
语言模型其实就是看一句话是不是正常人说出来的。这玩意很有用,比如机器翻译、语音识别得到若干候选之后,可以利用语言模型挑一个尽量靠谱的结果。在 NLP 的其它任务里也都能用到。
语言模型形式化的描述就是给定一个字符串,看它是自然语言的概率 。 到 依次表示这句话中的各个词。有个很简单的推论是:
常用的语言模型都是在近似地求 。比如 n-gram 模型就是用 近似表示前者。
顺便提一句,由于后面要介绍的每篇论文使用的符 差异太大,本博文里尝试统一使用 Bengio 2003 的符 系统(略做简化),以便在各方法之间做对比和分析。
2.1 Bengio 的经典之作
用神经 络训练语言模型的思想最早由百度 IDL 的徐伟于 2000 提出。(感谢 @余凯_西二旗民工 博士指出。)其论文《Can Artificial Neural Networks Learn Language Models提出一种用神经 络构建二元语言模型(即 )的方法。文中的基本思路与后续的语言模型的差别已经不大了。
训练语言模型的最经典之作,要数 Bengio 等人在 2001 年发表在 NIPS 上的文章《A Neural Probabilistic Language Model》。当然现在看的话,肯定是要看他在 2003 年投到 JMLR 上的同名论文了。
Bengio 用了一个三层的神经 络来构建语言模型,同样也是 n-gram 模型。如图1。
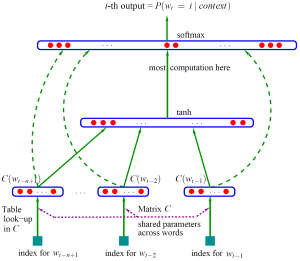

图1(点击查看大图)
图中最下方的 就是前 个词。现在需要根据这已知的 个词预测下一个词 。 表示词 所对应的词向量,整个模型中使用的是一套唯一的词向量,存在矩阵 (一个 的矩阵)中。其中 表示词表的大小(语料中的总词数), 表示词向量的维度。 到 的转化就是从矩阵中取出一行。
络的第一层(输入层)是将 这 个向量首尾相接拼起来,形成一个 维的向量,下面记为 。
络的第二层(隐藏层)就如同普通的神经 络,直接使用 计算得到。 是一个偏置项。在此之后,使用 作为激活函数。
络的第三层(输出层)一共有 个节点,每个节点 表示 下一个词为 的未归一化 log 概率。最后使用 softmax 激活函数将输出值 归一化成概率。最终, 的计算公式为:
式子中的 (一个 的矩阵)是隐藏层到输出层的参数,整个模型的多数计算集中在 和隐藏层的矩阵乘法中。后文的提到的 3 个工作,都有对这一环节的简化,提升计算的速度。
式子中还有一个矩阵 (),这个矩阵包含了从输入层到输出层的直连边。直连边就是从输入层直接到输出层的一个线性变换,好像也是神经 络中的一种常用技巧(没有仔细考察过)。如果不需要直连边的话,将 置为 0 就可以了。在最后的实验中,Bengio 发现直连边虽然不能提升模型效果,但是可以少一半的迭代次数。同时他也猜想如果没有直连边,可能可以生成更好的词向量。
现在万事俱备,用随机梯度下降法把这个模型优化出来就可以了。需要注意的是,一般神经 络的输入层只是一个输入值,而在这里,输入层 也是参数(存在 中),也是需要优化的。优化结束之后,词向量有了,语言模型也有了。
这样得到的语言模型自带平滑,无需传统 n-gram 模型中那些复杂的平滑算法。Bengio 在 APNews 数据集上做的对比实验也表明他的模型效果比精心设计平滑算法的普通 n-gram 算法要好 10% 到 20%。
在结束介绍 Bengio 大牛的经典作品之前再插一段八卦。在其 JMLR 论文中的未来工作一段,他提了一个能量函数,把输入向量和输出向量统一考虑,并以最小化能量函数为目标进行优化。后来 M&H 工作就是以此为基础展开的。
他提到一词多义有待解决,9 年之后 Huang 提出了一种解决方案。他还在论文中随口(不是在 Future Work 中写的)提到:可以使用一些方法降低参数个数,比如用循环神经 络。后来 Mikolov 就顺着这个方向发表了一大堆论文,直到博士毕业。
大牛就是大牛。
2.2 C&W 的 SENNA
Ronan Collobert 和 Jason Weston 在 2008 年的 ICML 上发表的《A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning》里面首次介绍了他们提出的词向量的计算方法。和上一篇牛文类似,如果现在要看的话,应该去看他们在 2011 年投到 JMLR 上的论文《Natural Language Processing (Almost) from Scratch》。文中总结了他们的多项工作,非常有系统性。这篇 JMLR 的论文题目也很霸气啊:从头开始搞 NLP。他们还把论文所写的系统开源了,叫做 SENNA(主页链接),3500 多行纯 C 代码也是写得非常清晰。我就是靠着这份代码才慢慢看懂这篇论文的。可惜的是,代码只有测试部分,没有训练部分。
实际上 C&W 这篇论文主要目的并不是在于生成一份好的词向量,甚至不想训练语言模型,而是要用这份词向量去完成 NLP 里面的各种任务,比如词性标注、命名实体识别、短语识别、语义角色标注等等。
由于目的的不同,C&W 的词向量训练方法在我看来也是最特别的。他们没有去近似地求 ,而是直接去尝试近似 。在实际操作中,他们并没有去求一个字符串的概率,而是求窗口连续 个词的打分 。打分 越高的说明这句话越是正常的话;打分低的说明这句话不是太合理;如果是随机把几个词堆积
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!