昨天接到了忻总的一个需求,要从一个自制的 盘上逐个下载文件
先来看看正常下载的步骤:
分析:
通过开发者工具可以看到左部文件夹导航栏中文件夹的class名称为‘jstree-anchor ’,并且每次点击文件夹之后页面会动态添加响应的子文件夹,class名称同样为’ jstree-anchor ‘
动态渲染就限制了我们不能使用Xpath或Beautifulsoup直接把静态页面抓取下来后直接进行分析下载,所以我们选择Selenuim库并使用其中的WebDriver进行自动化操作
那么我们应当如何判断已经到达底层的文件夹,也就是文件夹内部没有嵌套文件夹了呢前有提到,每次点击文件夹之后,如果有子文件夹,那么 页会自动向 页中添加响应的子文件夹,我们可以通过计算页面在点击事件之前class为’ jstree-anchor ‘的对象个数和点击之后的个数进行对比,如果相同则证明已经进入最底层的文件夹,此时只要依次进行右部文件的下载即可。
那么我们就来到了最后一步,选择文件进行下载,通过观察我们可以发现我们把鼠标移动至响应的文件上时,响应对象的css会添加一个名为’hover’的class并且显示下载按钮。
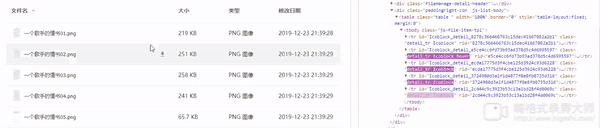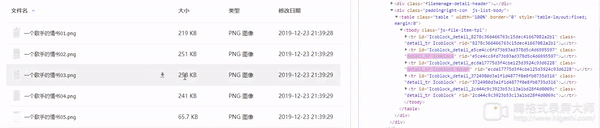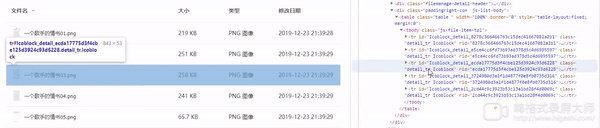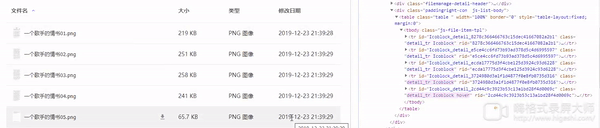

Selenuim提供的功能中似乎没有直接改变 页中对象属性的api,那么怎么办呢了execute_script方法,理论上任何未提供的功能都可以通过Javascript来实现,问题就此变的简单了,我们可以通过document.getElementById找到下载按钮,点击,即可完成下载。
实现
1.登录
2.点击文件夹,确保目前处于最底层,没有文件夹嵌套
局部的实现代码如下:
定义new和old两个变量分别对应点击事件前后的特定class对象个数,current作为计数器,统计我们现在点击到第几个文件夹
3.根据文件列表逐一下载
完整实现代码如下:
文章知识点与官方知识档案匹配,可进一步学习相关知识Python入门技能树首页概览211323 人正在系统学习中 相关资源:MinionProfitsTracker:随着市场价格波动,轻松识别最赚钱的奴才[在…
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!