难度:入门级
目标:
获取目标应用的新游戏预约数据
环境:
Python3.7.3、requests、mumu模拟器
目录:
1、分析请求
2、代码实现
3、总结
1、分析请求
配置完抓包软件的代理后,打开抓包软件(这里使用的是Charles),然后点开目标应用,可以看到抓包软件截获了很多请求。
很容易就可以知道这就是数据请求,右键请求获取curl
拿到代码先把header的cookie注释掉。
可以正常拿到数据。
现在需要分析一下url的变化,往下翻页拿到第二页的url,很容易就可以比对出变换的参数是index,且间隔为20。
2、代码实现
这里只获取了几页数据,当然你也可以全部获取完,自己修改一下代码就好咯。
将初步拿到的数据格式化,找到目标数据所在的位置。
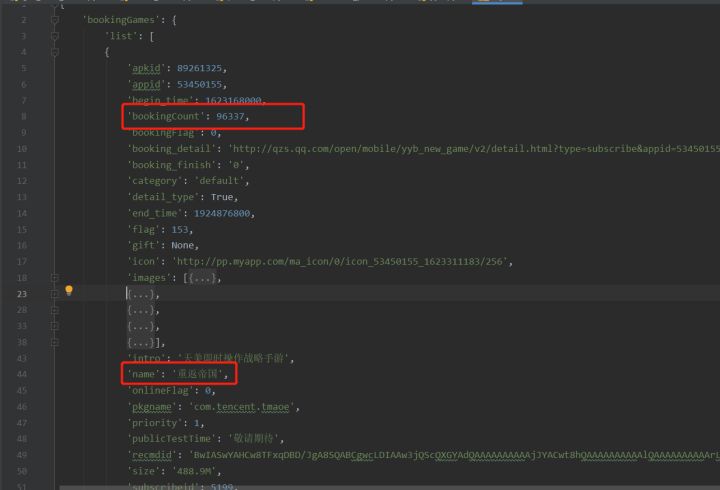

通过对比很快就可以找到数据。
代码实现:
3、总结
可以发现做app爬虫好像和 页爬虫没什么区别,只是获取请求的工具尤开发者工具换成了抓包工具。确实在做入门级难度的爬虫时很像,主要的区别是在做逆向破解参数的时候,这里就不过多赘述了,之后会讲到。
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!