1、图片采集
在八爪鱼中,采集图片有以下几大步
1)先采集 页图片的地址链接URL
2)通过八爪鱼提供的图片批量下载工具将URL转化为图片
2、常见应用情景
1)非瀑布流 站纯图片采集
2)瀑布流 站纯图片采集
这类瀑布流 站的采集需要按下面的步骤对采集规则进行设置:
① 点击采集规则打开 页步骤的高级选项;
② 勾选页面加载完成后下滚动;
③ 填写滚动的次数及每次滚动的间隔;
④ 滚动方式设置为:直接滚动到底部;
完成上面的规则设置后,再对页面中图片的URL进行采集
注意:滚动次数,滚动间隔应根据 页加载情况来设置。如果往下滚动,页面信息加载比较慢,建议将滚动间隔设大些。滚动次数应看滚动多少次可以将我们需要的数据加载全,建议多一两次,有备无患。滚动方式则看 页是一滚到底就全部数据都能顺利加载,还是得一屏一屏滚动才行。一般而言一屏一屏滚动,效果好但更费时。滚一屏的大小取决于你屏幕的大小,云采集则默认全屏。
3)文章图文采集
需要将文章里的文字和图片都采集下来,一般有两种方法
方法1:判断条件,设置判断条件分别采集文字和图片
方法2:先整体采集文字,再循环采集图片
3、教程目的
4、采集图片URL操作步骤
以下演示一个采集图片URL的具体操作步骤,以百度图片URL采集为例。不同的 站图片URL会遇到不同的情况,请大家灵活处理。
② 启动采集看一下采集结果,图片URL被采集下来
3)进行相关设置
② 配置完成以后,点击“开始下载”
6、图片采集及批量导出技巧
1)将不同图片,保存到不同文件夹中:在八爪鱼配置抓取模板时,预先添加一个字段,作为图片文件夹名,可设置多层文件夹。例,“D:第一层文件夹名第二层文件夹名”,其中“D:第一层文件夹名”是固定的,“第二层文件夹名”,根据图片采集时的标题/关键词变化
① 采集关键词的文本,作为“第二层文件夹名”。修改字段名称为“图片保存文件夹”。对采集到的关键词进行格式化处理,添加前缀和后缀,演示中添加的前缀为“D:百度图片采集”,后缀为“”
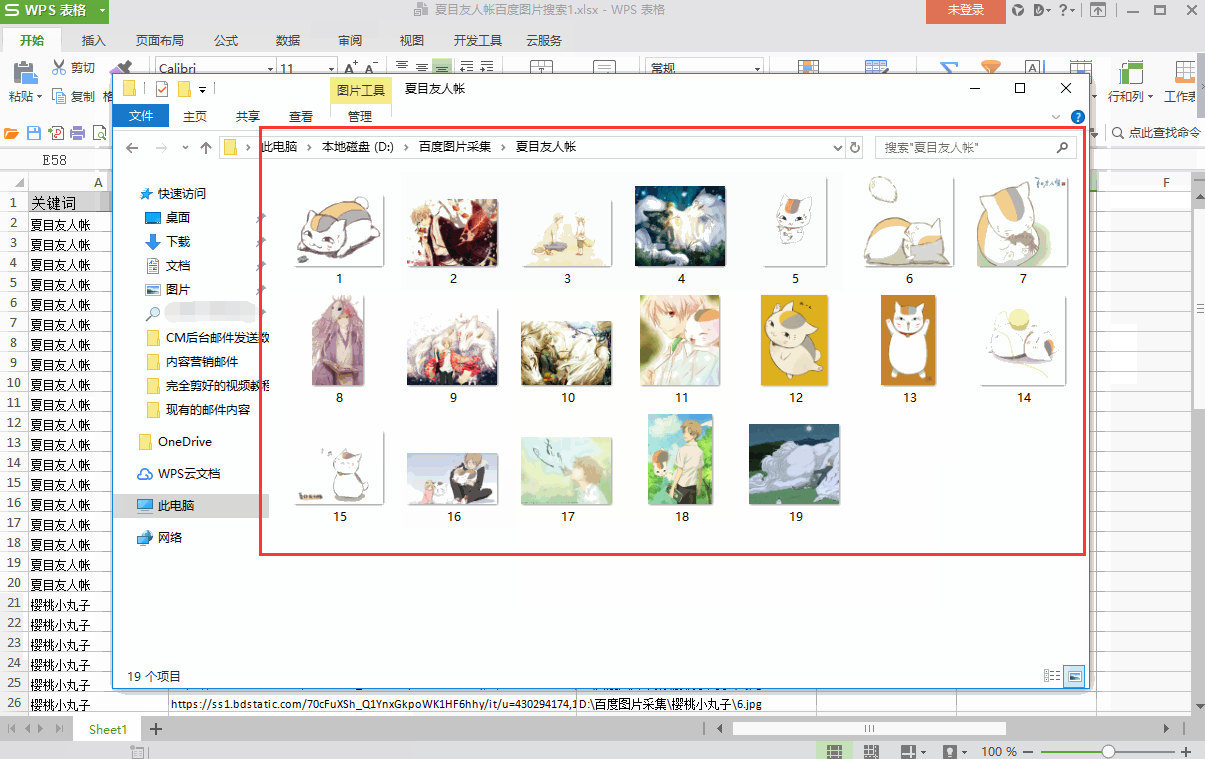
③ 经过图片导出操作后,打开D盘,找到“百度图片采集”文件夹,可以看到子文件夹以关键词命名
② 经过图片导出操作后,打开D盘,找到“百度图片采集”文件夹中的子文件夹,可以看到图片以1、2、3、4……自动命名

7、注意事项
1)支持下载的格式
① 采集下来的图片URL,以.jpg、.gif、.png等图片格式结尾时,一般情况下能批量转换为图片
② 如果采集下来的URL不是以图片格式结尾,则有可能不进行转换,可能是 站对此图片链接进行加密仅支持在线查看
2)如果图片URL采集下来是乱码或都一样的,可能是图片需要一定的加载时间,我们需要在提取数据步骤前,设置执行前等待,让图片完全加载出来;对于需在当前屏幕展示一段时间,图片才能完全加载出来的情况,还需相应的设置ajax滚动,具体请参考 ajax滚动教程 。
相关资源:…手爪、传感器功能包和一个在windows下可以接受力传感器的软件…
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!