将哑变量引入回归模型,虽然使模型变得较为复杂,但可以更直观地反映出该自变量的不同属性对于因变量的影响,提高了模型的精度和准确度。
举一个例子,如职业因素,假设分为学生、农民、工人、公务员、其他共5个分类,其中以“其他职业”作为参照,此时需要设定4个哑变量X1-X4,如下所示:
X1=1,学生;X1=0,非学生;
X2=1,农民;X2=0,非农民;
X3=1,工人;X3=0,非工人;
X4=1,公务员;X4=0,非公务员;
那么对于每一种职业分类,其赋值就可以转化为以下形式:
2. 将Event选入Dependent框中,将Gender、Age、Race选入Covariates框中
在选择哑变量编码方式时,Contrast下拉选项一共提供了7种编码方式:
(1) Indicator(指示对比):用于指定某一分类为参照,指定的参照取决于Reference Category中选择Last还是First,即只能以该变量的第一类或者最后一类作为参照。Indicator为默认方法,也是我们最常用的设置参照类的方法。
(2) Simple(简单对比): Simple和Indicator两个方法虽然参数编码不同,但其实质是一样的,均为各分类分别与参照进行相比。
(3) Difference(差异对比):即该分类变量的某个分类,与前面所有分类的平均值进行比较,此法与Helmert法相反,因此也叫做反Helmert法。此选项常用于有序分类变量。
(4) Helmert(赫尔默特对比):即该分类变量的某个分类,与其后面所有分类的平均值进行比较,同样也适用于有序分类变量。
(5) Repeated(重复对比):即该分类变量的各个分类,均与前面相邻的一个分类进行比较,此时前一分类为参照。
(6) Polynomial(多项式对比):它假设各个分类间隔是等距的,只能用于数值型的变量。(注意:如果此时原始变量为字符型,例如A、B、C、D,在SPSS中使用该方法时它会提示Polynomial contrasts may not be specified for string variables。而对于其他6种方法是允许原始变量是字符型,SPSS可以将其自动转化为0或1形式的哑变量。)
(7) Deviation(偏差对比):即除参照外,其余每一个分类都与总体水平相比,此时每个分类的回归系数都是相对于总体水平而言的改变量。
4. 点击Continue回到主对话框,再点击OK完成操作。
三、结果解读
将需要转换为哑变量的Race因素选入Create Dummy Variables for中,在Root Names(One Per Selected Variable)框中输入转换后的哑变量名Race_,并点击OK完成操作。
方法二
1. Transform → Recode into Different Variables
2. 点击Old and New Values进入重新编码的对话框
在Old Value中的Value框中填写1,在New Value中的Value框中填写1,并点击Add添加,得到1->1。
上述步骤表示将原有变量Race中第1分类,在哑变量Race1中赋值为1,将其他所有分类在哑变量Race1中赋值为0。
3. Analyze → Regression → Linear
三、结果解读
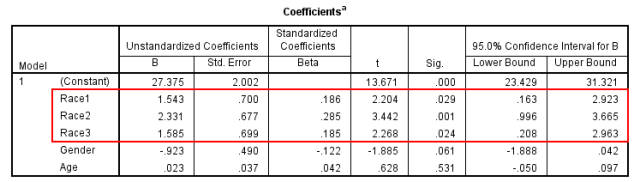

1. 我们通过重新编码将Race转化为3个哑变量,分别为Race1、2、3,代表黑人、白人和印第安人,此时参照为亚裔人。在α=0.05的检验水准下,Race1、2、3回归系数检验P值均
2. 黑人、白人和印第安人与亚裔人相比,其β值和95% CI分别为1.543(0.163, 2.923)、2.331(0.996, 3.665)、1.585(0.208, 2.963),提示黑人、白人和印第安人的BMI要显著高于亚裔人。
设置哑变量时的注意事项
1. 原则上哑变量在模型中应同进同出,也就是说在一个模型中,如果同一个分类变量的不同哑变量,出现了有些哑变量有统计学显著性,有些无统计学显著性的情况下,为了保证所有哑变量代表含义的正确性,应当在模型中纳入所有的哑变量。
因此,我们在引入哑变量进入模型时,需选择Enter强制进入法,以保证所有哑变量都能保留在最后的模型中。
2. 在如何选择哑变量的参照组时需要注意的是,被选为参照的那一类分组,应该保证有一定的样本量。如果参照组样本量太少,则将会导致其他分类与参照相比时,参数估计的标准误较大,可信区间较大,精度降低,会出现估计参数极大或极小的现象。
相关资源:…dummy:虚拟RPM,用于哑的oracle-instantclient软件包-其它代码…
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!