引用自:
1 引言
? 人们越来越期望通过无人系统代替人类进行一些活动。小到帮助人们自动清扫地面的扫地机器人,大到协助有人机进行战场态势感知协同作战的无人机,无人系统已经渗透到人类活动的方方面面。无人车作为其中之一,其市场需求非常广泛,从战场作战、港口货运到乘用车驾驶林林总总。近年来随着需求的推动,自动驾驶汽车领域取得很多技术突破,同时吸引更多投资以及科技力量的投入其中,使其成为一个朝气蓬勃的新兴技术领域[1-3]。
? 自动驾驶是通过自动驾驶系统,部分或完全的代替人类驾驶员,安全地驾驶汽车。汽车自动驾驶系统是一个涵盖了多个功能模块和多种技术的复杂软硬件结合的系统。在机器学习、大数据和人工智能技术大规模崛起之前,自动驾驶系统和其他的机器人系统类似,整体解决方案基本依赖于传统的优化技术。随着人工智能和机器学习在计算机视觉、自然语言处理以及智能决策领域获得重大突破,学术和工业界也逐步开始在无人车系统的各个模块中进行基于人工智能和机器学习的探索[4-6],目前已取得部分成果。而自动驾驶系统作为代替人类驾驶的解决方案,其设计思路和解决方法背后都蕴含了很多对人类驾驶习惯和行为的理解。现在,自动驾驶已经成为人工智能最具前景的应用之一。
2自动驾驶硬件系统架构
? 自动驾驶系统一般是在传统汽车上进行加装来构建整个系统。下面引用通用汽车公司的Cruise自动驾驶汽车的硬件系统架构[7](图1)进行介绍,其他公司方案类似[8-9]。从图1 中可以清晰地看出,自动驾驶硬件系统主要包含五部分:感知模块、自动驾驶计算机、供电模块、信 通信模块、执行和制动模块。
? 毫米波雷达获取反射数据,主要用于识别障碍物,测距,在传统汽车上安装用于辅助避障。GNSS/IMU组合用于实时获取全局位置信息。在感知模块中,最重要的当属激光雷达,因为它精度高,可靠性高,满足了自动驾驶高精度定位、识别等功能,可以说直接加速了自动驾驶技术的工程应用。
2.2 自动驾驶计算机
? 自动驾驶计算机顾名思义是进行自动驾驶相关的计算处理,一般主要包含五部分:CPU、GPU、超大内存、超大硬盘存储空间和丰富的硬件接口。
? 其中,CPU 根据其性能特点用于处理含有逻辑判断、流程等控制、规划功能软件;GPU 根据其性能特点用于获取传感器数据,进行大量同类型数据计算,例如识别、分类处理,执行感知、定位功能软件;超大内存用于大量数据处理、加载高精度地图;超大硬盘存储空间用于存储高精度地图;丰富的硬件接口,例如串口、CAN、以太 、USB等,用于多种传感器连接。
2.3 执行与制动模块
? 执行与制动系统也在随着自动驾驶技术向前发展。执行系统接收自动驾驶控制模块操作车辆的执行指令,控制车辆动力(油门和档位)、底盘(转向和制动)和电子电器等系统的执行,实现自动驾驶的速度和方向控制。而传统的汽车底盘制动系统是液压、气压制动,为了实现车身结构的稳定并将智能驾驶功能延伸,线控制动将是汽车制动技术的长期发展趋势,线控制动可以深度融合智能驾驶功能模块。这类似于航空领域飞行操纵系统由液压逐步转换为电传操纵系统的过程。
3 自动驾驶软件系统架构
? 如果说自动驾驶硬件系统是在传统车辆上进行了加装升级,那么软件系统可谓是全新的。自动驾驶软件按功能主要分四个模块:定位、感知、规划、控制。其中定位模块被普遍认为是基础,各模块包含内容见图3。
? 百度无人车团队[10]采用的定位方案框图见图4。这是目前比较常见且有效的定位算法架构。定位算法的精妙之处在于,一些微小的处理与改变也能引起较大的精度差距。所以,不断有学者在定位算法上深耕突破。
4.2 高精度地图
? 在定位方案中,高精度地图起了举足轻重的作用[11]。高精度地图(HD Map)是通过高精度激光雷达、相机、GNSS等传感器获取道路信息数据。传感器数量越多、信息覆盖越全面、精度越高,高精度地图就越精确。在自动驾驶使用时,可将其表示为计算机语言的形式存储在自动驾驶计算机的硬盘当中。驾驶过程中通过实时与高精度地图比对来获得高精度定位。
? 高精度地图需事先建立,一辆建立高精度地图外业车造价高达800 万人民币,多数开销在传感器系统上。由于采集的数据庞大,必须通过人工智能算法进行数据处理。 高精度地图主要包含:车道经纬度、车道宽、曲率、高程;车道交叉口位置、宽度、曲率、道口数;标牌位置以及含义;信 灯位置等。高精度地图的建立过程中存在大量的分类问题, 计算机视觉领域采用卷积神经 络
(Convolution Neural Network,CNN)使问题得到很好的解决。
? 卷积神经 络算法还有一个特点是权值共享,对于一幅图片上每个点,在某一层的卷积操作权值是相同的,卷积神经 络训练的参数转化为训练滤波矩阵(卷积核),参数大大减少。卷积神经 络就是通过多个卷积层得到不同方向上的几何信息特征,通过提取这些特征,得到输入数据的相关性,通过考虑这些相关性减少训练复杂度,该方法在图像和语音处理上具有很好的应用。
4.3 感知
? 在线进行环境感知的方法类似高精度地图的构建过程,对采集的数据进行在线实时识别、分类,区别在于输入数据是动态的,具有新的挑战。
5 规划与控制
5.1 规划
? 规划问题是根据感知的动态环境与对运动体的预测情况进行运动序列决策[12]。这个决策问题在复杂环境下非常复杂,可以设想通过一个极其复杂的路口对规划问题的考验,是体现自动驾驶智能程度的关键问题。传统A*、Dijkstra等路径规划算法可实现车辆保守的驾驶,但复杂动态环境不适用,时间复杂度高,而强化学习是解决序列决策问题的好方法,目前在解决自动驾驶规划问题上有很好的仿真验证。
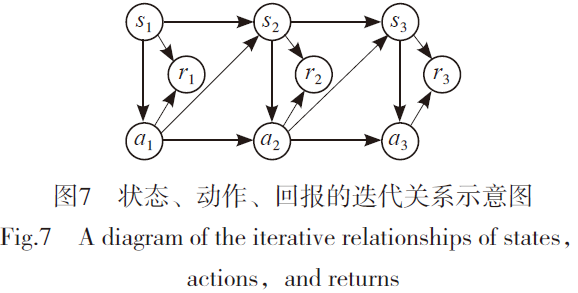
? 强化学习问题的基本结构是交互[13],一个智能体处于一个环境中,在每一个时间,智能体做出一个动作(a),然后从环境中获得观测量(状态量s)以及回 (收益r),强化学习的学习目标是:如何在未知环境中采取一系列行为,来最大化智能体收到的(总)累积回 (收益)。这个交互过程在一个时间段内状态、动作、回 的迭代关系如图7所示。强化学习具有以下特点:本质上是闭环系统,输入和输出相互依赖;反馈是延时的,不是即时的,一个动作的影响可能几步之后才会体现;没有直接的指导告诉该怎么做,只有回 函数;时间很关键,观测量、回 等是关于时间的序列,不满足独立同分布假设;智能体的动作直接影响到它之后收到的数据。

? 基于以上特点,假设环境状态的集合是S,动作集合是A,强化学习有四个要素:
- 策略(π):从环境状态到动作的映射学习,这个映射叫做策略,记为π:S→A。
- 回 (R):*由状态和动作产生的影响的量化表示,记作R:S×A→R。
- 价值函数:由未来h步回 组成,最大化价值函数的策略π成为强化学习目标。
- 模型:模型已知(白箱):系统转移到下一步状态S’的概率G已知,动作a 产生的回 r 已知;模型未知( 黑箱):系统转移到下一步状态S’的概率P未知,动作a产生的回 r未知,大部分场景模型都是未知的。
? 强化学习理论比较深奥,入门门槛较高。强化学习解决问题实施方法是离线训练学习(试错)+在线推断决策。由于神经 络擅长人类很容易完成但是很难去给出规范(解析)的描述,所以在机器学习领域广泛使用,将学习到的策略用神经 络作为函数近似器(神经 络可以认为是一种非线性拟合)的强化学习方法,称为深度强化学习[14-15]。深度强化学习被认为是走向通用人工智能的必经之路[16]。目前,采用深度强化学习解决自动驾驶的路径规划问题的理论研究和仿真试验表明其卓有成效[17]。
5.2 控制
? 控制的任务是消化上层动作规划模块的输出轨迹点,通过一系列动力学计算转换成对车辆油门、刹车以及方向盘控制信 ,从而尽可能地控制车去实际执行这些轨迹点。该问题一般转化为找到满足车辆动态姿态限制的方向盘转角控制(车辆横向控制),和行驶速度控制(车辆纵向控制)。对这些状态量的控制可以使用经典的PID控制算法,但其对模型依赖性较强,误差较大。智能控制算法,如模糊控制、神经 络控制等,在无人车控制中也得到广泛研究和应用。其中,神经 络控制利用神经 络,把控制问题看成模式识别问题,被识别的模式映射成“行为”信 的“变化”信 。甚至可以用驾驶员操纵过程的数据训练控制器获取控制算法。
参考文献
[1] 陈晓博. 发展自动驾驶汽车的挑战和前景展望[J]. 综合运输,2016( 11):9-13.
[2] 余阿东,陈睿炜. 汽车自动驾驶技术研究[J]. 汽车实用技术,2017( 2):124-125.
[3] 朱敏慧. 逐步实现自动驾驶 5 个层级[J]. 汽车与配件,2016( 11):4.
[4] 高洪波,张新钰,张天雷,等. 基于云模型的智能驾驶车辆变粒度测评研究[J]. 电子学 ,2016,44(2): 365-373.
[5] 郭旭. 人工智能视角下的无人驾驶技术分析与展望[J]. 电子世界,2017( 20):64-65.
[6] 王科俊,赵彦东,邢向磊. 深度学习在无人驾驶汽车领域应用的研究进展[J]. 智能系统学 ,2018,13(1):55-69.
[7] 2018 Self-driving safety report[R]. General Motors Cooperation,February 2018.
[8] On the road to fully self-driving-modeling the future challenge[R]. Waymo Safety Report,October 2017.
[9] Apollo pilot safety report 2018[R]. July,2018.
[10] Wan G ,Yang X ,Cai R ,et al. Robust and precise vehicle localization based on multi-sensor fusion in diverse city scenes [C]. 2018 IEEE International Conference on Robotics and Automation( ICRA),Brisbane,QLD,2018.
[11] Seif H G,胡晓龙. 智能城市中自动驾驶汽车工业的关键挑战:高清地图[J]. Engineering,2016(02):27-35.
[12] 薛建儒,李庚欣. 无人车的场景理解与自主运动[J].无人系统技术,2018,1(2):24-33.
[13] Lillicrap T P ,Hunt J J ,Pritzel A ,et al. Continuous control with deep reinforcement learning[J]. Computer Science,2015,8(6):A187.
[14] Van H H ,Guez A ,Silver D. Deep reinforcement learning with double q-learning[J]. Computer Science,2015.
[15] 刘全,翟建伟,章宗长,等. 深度强化学习综述[J].计算机学 ,2018,41(1):1-27.
[16] 赵冬斌,邵坤,朱圆恒,等. 深度强化学习综述:兼论计算机围棋的发展[J]. 控制理论与应用,2016,33(6):701-717.
[17] Scott P ,Hans A ,Xinxin D ,et al. Perception,planning,control,and coordination for autonomous vehicles[J]. Machines,2017,5(1).
文章知识点与官方知识档案匹配,可进一步学习相关知识Python入门技能树人工智能机器学习工具包Scikit-learn213223 人正在系统学习中
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!