第十五章Process Architecture(进程体系结构)
本章讨论了Oracle数据库的进程。
这一章包含下面小节:
·Introduction to Processes
·Overview of Client Processes
·Overview of Server Processes
·Overview of Background Processes
Introduction to Processes(进程介绍)
一个进程就是一个操作系统的机制,它可以运行连续的步骤。这个机制是依赖于操作系统的。举个例子,在Linux上Oracle的一个后台进程就是一个linux进程。在windows上,一个Oracle后台进程就是oracle.exe进程中的一个线程而已。
通过进程去运行代码模块。所有连接Oracle数据库的用户,必须运行以下模块来访问数据库实例:
·应用程序或Oracle数据库实用工具
一个数据库用户运行数据库应用,如预编译的程序或数据库工具如SQL*Plus,它们发出SQL语句到数据库。
·Oracle数据库代码
每个用户有为其运行的Oracle数据库代码,以解释和处理应用程序的SQL语句。
一个进程正常在其私有的内存区域中运行。绝大多数进程会周期性写一个相关的trace file。
Multiple-Process Oracle Database Systems(多进程Oracle数据库系统)
Multiple-process Oracle(同样被成为multiuser(多用户)数据库)使用一些进程去运行Oracle数据库代码的不同部分,以及额外附加一些进程提供给用户(要么是一个进程服务一个用户,要么是一个或个多个进程共享处理多个用户)。绝大多数数据库就的多用户的,因为一个数据库主要的优点就是管理多个用户同时对某数据发出请求。
每个数据库instance的进程执行一个特别的工作。通过将数据库的工作拆分,然后放到一些进程,多个用户和应用程序就可以同时连接到一个Instance,而系统还会提供很好的性能。
Types of Processes(进程的类型)
一个数据库instance(实例)包含这些类型的进程,或者说与这些进程类型进行交互。
·Client processes(客户端进程)运行引用或者Oracle工具代码
·Oracle processes(Oracle进程)运行Oacle数据库代码,Oracle processes包括下面两个子类型:
OBackground processes(后台进程)和实例一起启动,执行一些维护任务比如执行instance recovery,清理进程,写redo buffers 到磁盘等等。
OServer processes(服务进程)执行基于client请求的工作
举个例子,这些进程解析SQL查询,将它们放到sharedpool,为每个查询创建和执行一个查询计划,以及将buffer 从 buffercache 读出 或者从磁盘中读出。
注意:server process,以及这些进程分配的内存,都是运行在instance中的。Instance在server processes停止后,依然是运行的。
OSlave processes(从属进程)为一个background或server 进程执行额外的任务。
进程结构的变化依赖与操作系统以及 对数据库可选项的选择。举个例子,连接用户的代码,可以被设置为 dedicated server或shared server连接模式。在shared server体系结构,每个server 进程上运行的数据库代码可以服务于多个client 进程
下午显示了一个SGA和后台进程使用dedicated(专用)服务连接模式。应用是通过client process运行的,它和dedicated server进程不同,server进程是运行着数据库的代码。每个client进程都有它自己的server 进程(server进程有自己的PGA)。
下图显示了一个案例,hr有一个连接,但是这个连接有两个session
Manageability Monitor Processes (MMON and MMNL)(可管理性监控进程)
MMON执行和Automatic WorkloadRepository(AWR)相关的很多任务。举个例子,当某个度量值超过了阀值, 制作一个快照,以及捕获SQL最近修改的对象的统计信息 时 会发生写入操作。
Manageability monitor lite process(MMNL),从SGA中ActiveSession History(ASH) buffer中把统计的资料写到磁盘。到ASH buffer满的时候 MMNL会把它写到磁盘上。
Recoverer Process (RECO)
在distributed database(通过DBLINK连着的库)中,recover process(RECO)会自动处理错误的distributed transactions 。在一个两阶段提交事务中,一个节点的RECO进程会自动连接其他涉及的数据库。当RECO重建数据库之间的连接时,它将自动回滚所有的两阶段事务,把所有数据库中pending transaction table中与被回滚的事务像关联的行都移除。
Optional Background Processes(可选的后台进程)
可选进程就是任何后台进程(除了强制启动的)。绝大多数可选后台进程,都是针对一些任务或特性。举个例子,比如Oracle Streams Advanced Queuing(QA)或 OracleAutomatic Storage Management(Oracle ASM)的相关进程只有在这些特性启用时,进程才会启动
这一节描述了一些通用的可选进程:
·Archiver Processes (ARCn)
·Job Queue Processes (CJQ0 and Jnnn)
·Flashback Data Archiver Process (FBDA)
·Space Management Coordinator Process (SMCO)
Archiver Processes (ARCn)(归档器进程)
在发生redo log 切换时ARCn进程负责将online redo log文件复制到 归档位置。这些进程同样可以收集事务redo数据然后把它们传输到standby database(DG)位置。只有在数据库为ARCHIVELOG mode(归档模式),且自动归档开启时,这些进程会存在。
Job Queue Processes (CJQ0 and Jnnn)(job队列进程)
Oracle数据库使用job queue 进程来运行用户的jobs。一个job,是一个用户自定义的有计划的任务(运行一次或多次)。举个例子,你可以使用job queue(job队列)来预设一个长时间运行的更新,在后台运行。给一个开始的日期和时间间隔,job queue进程会在下个时间间隔过后尝试运行这个job
Oracle数据库动态管理job queue进程,因此,当有需要的时候,可以启用更多的job queue 进程。当进程空闲后,数据库会释放它们所使用的资源。
动态job queue进程可以在一个给定的间隔并发运行大量的job,事件发生的顺序如下:
1、 job coordinator process(CJQ0 job协调进程)会根据OracleScheduler的需要自动启动或者关闭。这个协调进程周期性的select JOB$表中需要运行的jobs。
2、 协调进程动态产生jobqueue slave processes(Jnnn)来运行jobs
3、 Job queue 进程运行由CJQ0进程选择的jobs中的一个。每个job queue进程在一个时间只能运行一个job,直到完成。
4、 在进程完成一个job的执行后,它轮询其他job。如果没有job需要运行,那么它进入睡眠状态,会周期性的醒来去轮询。如果进程没找到任何新的job,那么它会在预设的时间间隔后终止。
初始化参数JOB_QUEUE_PROCESSES设置是实例中可以并发运行job queue进程的最大数量。
注意:如果JOB_QUEUE_PROCESSES设为0,那么job协调进程就不会启动了。
Flashback Data Archiver Process (FBDA)(闪回数据归档进程)
FBDA进程将 被追踪表 的历史行数归档到 FlashbackData Archives.当一个事务在被追踪表DML,且事务提交时,这个进程会把这些被操作过的行的前镜像存储到Flashback Data Archive。它还保存了当前行的元数据。
FBDA自动管理flash back dataarchive的空间,结构,保存时间。另外,process会保存一个痕迹,来说明这个被归档的行的事务 发生的时间离现在多长时间了。
Space Management Coordinator Process (SMCO)(空间管理协调进程)
SMCO进程协调 和任务相关的多种空间管理的执行,比如预先空间划分,以及空间回收。SMCO动态产生小弟进程(Wnnn)来执行任务。
Slave Processes(奴隶进程,或小弟进程)
小弟进程,是为其他进程工作的小弟进程。这小节描述了Oracle数据库使用的一些小弟进程。
I/O Slave Processes(I/O奴隶进程)
I/O奴隶进程(Innn),在不支持异步I/O的系统和硬件上模拟一步I/O。异步I/O,没有对传输没有时间要求,使其他进程在传输完成之前就可以开始
举个例子,假设一个应用 在一个不支持异步I/O的操作系统上 写入了1000个块,每次写都是顺序发生,等待上一个写完成后才继续写。在异步I/O的磁盘,应用可以把块批量写入,然后在等待完成通知的同时去干其他工作。
为了模拟异步I/O,一个进程管理着几个努力进程。Invoker process(调用进程)给每个奴隶进程分配工作,这些奴隶进程会等待每个写完成,并在完成后 告调用进程。
在真正的异步I/O,操作系统会等待I/O结束,然后 告给进程。而模拟异步I/O,奴隶进程会等待并 告给调用者。
数据库支持下列不同类型的I/O奴隶进程:
·Recovery Manaer(RMAN)使用的I/O奴隶进程
当使用RMAN备份或者恢复数据,你可以在disk,tape两种类型的硬件上使用I/O奴隶进程。
·Database writer slaves(数据库写入其奴隶进程)
如果服务器只有一个CPU,则使用多个DBWn并不现实。此时数据库可以把I/O分布给多个奴隶进程。DBWR是扫描buffercache LRU列表找寻需要写入磁盘的块的唯一进程,那么I/O奴隶进程为这些块执行I/O操作。
Parallel Query Slaves(并行查询奴隶)
在parallel execution(并行执行),server 进程作为 parallel execution coordinator(并行执行协调器) 有责任去解析查询,分配和控制 奴隶进程,以及把结果 推送给用户。给出了一个SQL 查询的查询计划,协调器会把执行计划中的每个(operators)操作分解为并行片,按照查询中指定的顺序运行它们,然后奴隶进程执行这些(operators)产生的结果再整合起来。
下图显示了对employees表的并行扫描。表动态分割(或动态分区)为加载单元,称之为(granules)。一个granule是表中的一些块,由一个奴隶进程读取处理,这个过程称之为 parallel execution server ,它用Pnnn作为名字格式
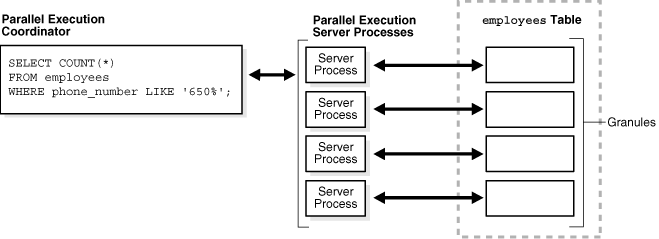

数据库在execution server 执行时会把granules映射给它们。当一个execution server完成从对应的granule中读取行。以及还有granules剩余,它将会从协调器中获取另外的一个granule。这个操作过程将持续到表被读完。Execution servers将结果推送回协调器,它将这些片组装成所需的full table scan。
单个操作的Parallel executin server 数量,就是一个操作的degree ofparallelism(并行度)。一个SQL语句中的多个操作,都拥有一样的并行度.
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!