一文学会SPSS软件
语法
变量命名:不能包含空白 不能以数字开头 不能用$ 最后一个字符不能以.或者__结束、不能以保留字为命名即for等
可以为汉语、英文名、@
测量:
度量:定量变量;
又称定居变量或者刻度变量,一般为有刻度度量的连续变量,它的取值之间可以比较大小,且可以定义距离。例如:“年龄”,“份”等
有序:等级变量;
取值直接有大小分类等级 如满意度
1:很满意
2:比较满意
3:不满意名义:分类变量
它的取值只代表观测对象的不同类别,变量的取值之间没有内在的大小可比性,例如“性别”变量
角色:
一般——输入的角色是系统默认的,输入——代表自变量,因为自变量是需要输入的。
目标角色是自变量,意思是该变量将被作为输出目标。
两者都有的选项是数据具有输出和输入两种属性,“无”是没有角色分配。
1.1选择个案
当数据量较大时,可以用于对于数据的筛选,去除没有用处的数据,也就是不可靠的数据,或者筛选出自己有价值的数据。
然后继续点击确定完成,即得到如下数据图
基于时间或个案范围
-
如下图所示操作
基于过滤变量的操作
1.2个案加权
加权个案是指对变量,特别是频数变量赋以权重,常用于计数频数表资料,加权以后的变量被说明为频数。在实验数据中处理频数数据时候往往需要用加权。
首先打开数据表,数据图如下:
加权之后进行描述统计:
数据->个案加权
可以观察到,加权之后的数据。
1.3计算新变量
类似于if语句,对一定的数据改换新的数据。用的较少不再介绍。
1.4对个案的值进行计数
通常我们在前期整理数据的过程中会遇到需要对满足某一个观测条件的值进行统计:例如在教师满意度评分中需要计算出每个教师得到“满意”等级的分数的个数,或者是统计出在某次成绩中有多少个同学的成绩在90分以上等等情况,在遇到这些情况时我们就需要用到今天要介绍的“对个案中值的计数”怎么操作,请跟我来!!
首先打开数据表,对数据表中身高大于175的人数计数。
完成操作后的数据表如图所示:
还有直方图,没有全部加进来,方便观看
通过上述选项,可以选择多种统计分析。在这里我们勾选所有的选项,按照变量列表进行排序显示,得到的数据结果如下:
再进行探索性分析:
因变量列表:进行探索性分析的变量,如本样例中的薪水
因子列表:性别
标注个案:编
通过此图可以清楚的看到男女薪资水平。
4.4连列表分析
列联表分析是通过分析多个变量在不同取值情况下的数据分布情况,从而进一步分析多个变量之间相互互相关系的一种描述性分析方法。
例如:
通过平均值检验得到数据如下:
可以看到检验的结果并不是很好,首先是置信区间差距较大。
5.3两独立样本的t检验
两独立样本t检验就是根据样本数据对两个样本来自的两独立总体的均值是否有显著差异进行推断。
进行两独立样本t检验的前提条件:
两样本应该是相互独立的。
样本来自的两个总体应该服从正态分布。
具体的操作如下:
共输出t值和P值,以及还有平均值与标准差值。
从分析角度看P值和平均值更有意义,首先看P值大小,判断两组数据是否有显著性差异,P
6.1卡方检验
在开始做分析之前,我们需要明白两件事情:卡方检验是什么用来干什么只有充分了解分析方法以后才能够正确的使用它。
卡方检验在百科中的解释是:卡方检验是用途非常广的一种假设检验方法,它在分类资料统计推断中的应用,包括:两个率或两个构成比比较的卡方检验;多个率或多个构成比比较的卡方检验以及分类资料的相关分析等。它的原理是:统计样本的实际观测值与理论推断值之间的偏离程度,实际观测值与理论推断值之间的偏离程度就决定卡方值的大小,如果卡方值越大,二者偏差程度越大;反之,二者偏差越小;若两个值完全相等时,卡方值就为0,表明理论值完全符合。
对次数和筛子点数进行卡方检验:
检验结果:
得到假设检验汇总,其中其P=0.009
6.3多独立样本的分参数检验
6.4两配对与多配对
7.2单因素方差分析
区域 土壤含水量
1 19.92
1 21.39
1 17.69
2 16.72
2 14.87
2 14.55
3 17.33
3 19.41
3 21.47
4 23.04
4 21.91
4 20.92
进行单因素方差分析:
方差齐性检验
土壤含水量
莱文统计 自由度 1 自由度 2 显著性
.443 3 8 .728
可以看到显著性为0.728>0.0.5说明方差是齐次的可以使用方差分析。
ANOVA
土壤含水量
平方和 自由度 均方 F 显著性
组间 (组合) 67.236 3 22.412 8.744 .007
线性项 对比 17.800 1 17.800 6.944 .030
偏差 49.436 2 24.718 9.643 .007
组内 20.506 8 2.563
总计 87.742 11
可以看到显著性都小于0.05,即不同土壤对含水量存在影响存在影响。
数据和多因素分析的选项:
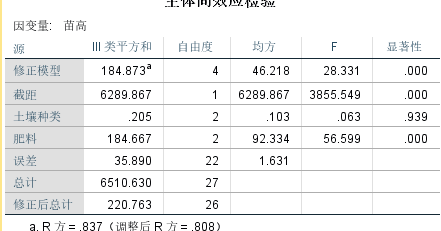

得到的数据中:可以看到肥料的显著性为0.00,土壤种类的为0.939,所以说苗高是和肥料是明显相关的。
7.4协方差分析
推荐观看
8.1两变量相关性分析
推荐观看
8.2距离分析
推荐观看
距离分析简单来说就是对几种数据的图像的走势分析,是不是基本吻合
9.1回归分析
推荐观看
我们现在需要通过回归分析来了解商品上架种类和商品销售量之间是否有关系,如果有的话又是怎么样的一种关系,并且是否可以通过目前的数据来预测一下12月份的商品销售量情况。
9.2曲线估计
推荐观看
然线性回归能够满足大部分的数据分析的要求,但是,线性回归并不是对所有的问题都适用, 因为有时候自变量和因变量是通过一个已知或未知的非线性函数关系相联系的,如果通过函数转换,将关系转换成线性关系,可能会造成数据失真或更为复杂的计算,导致结果出现偏差
9.3非线性回归
推荐观看
:原数据中自变量为时间(1900~2018),因变量为金额。下面我们就来研究,金额随着时间增加而呈现的趋势变化。
9.4二元Logistic回归案例分析
推荐观看
二元Logistic,从字面上其实就可以理解大概是什么意思,Logistic中文意思为“逻辑”但是这里,并不是逻辑的意思,而是通过logit变换来命名的,二元一般指“两种可能性”就好比逻辑中的“是”或者“否”一样,
9.5多元Logistic
推荐观看
存在因变量是多项的情况
9.6有序回归
推荐观看
等级回归分析对应的英文为“ordinal regression”,也称有序回归,以等级变量做因变量建立模型来预测危险发生的概率,因变量中各个类别要按不同程度的顺序取值。 第一步:调用界面:分析—回归—有序 选择变量做因变量、因子、协变量。 通过频数描述知,等级越高,概率即数目越多,所以选则“补充对数-对数”即complementary log-
9.7概率单位回归
推荐观看
如何理解probit概率单位回归分析呢,用一句特典型的话就可以说清楚了:研究患者给药剂量与治愈百分比之间的关系。如果我们把这句话推广到销售业务,可以是这样:研究消费者对价格与购买数量之间的关系。
9.8加权回归
推荐观看
例如在研究通货膨胀和失业率对股票价格的影响时,考虑到高市值的股票较低市值的具有更高的变异性(价格波动大),使用OLS法便不能很好地反应制定因素对变异性较大的股票的影响,这个时候就需要使用WLS方法来解决这个问题。
10.1快速聚类
推荐观看
推荐观看
它能够将一批样本数据按照他们在性质上的亲密程度在没有先验知识的情况下自动进行分类。这里所说的类就是一个具有相似性的个体的集合,不同类之间具有明显的区别。
10.2系统聚类
推荐观看
系统聚类又叫做层次聚类或分层聚类,是聚类分析的常用方法之一
10.3两步聚类
推荐观看
汽车生产厂商需要有效的方法评价当前市场情况,了解市场需要,找到受市场欢迎的,有市场竞争力的车型配置。
10.4聚类分析的不同
推荐观看
11.1一般判别分析
推荐观看
判别分析又称“分辨法”,是在分类确定的条件下,根据某一研究对象的各种特征值判别其类型归属问题的一种多变量统计分析方法。
当得到一个新的样品数据,要确定该样品属于已知类型中哪一类,这类问题属于判别分析问题。
12.1因子分析
推荐观看
因子分析模型中,假定每个原始变量由两部分组成:共同因子和唯一因子。共同因子是各个原始变量所共有的因子,解释变量之间的相关关系。唯一因子顾名思义是每个原始变量所特有的因子,表示该变量不能被共同因子解释的部分。
12.2主成分分析
属于判别分析问题。**
12.1因子分析
推荐观看
因子分析模型中,假定每个原始变量由两部分组成:共同因子和唯一因子。共同因子是各个原始变量所共有的因子,解释变量之间的相关关系。唯一因子顾名思义是每个原始变量所特有的因子,表示该变量不能被共同因子解释的部分。
12.2主成分分析
推荐观看
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!