文章目录
-
- 一、Prometheus简介
- 二、Prometheus架构
- 三、Prometheus 相关概念
一、Prometheus简介
Prometheus受启发于Google的Brogmon监控系统(相似的Kubernetes是从Google的Brog系统演变而来),从2012年开始由前Google工程师在Soundcloud以开源软件的形式进行研发,并且于2015年早期对外发布早期版本。2016年5月继Kubernetes之后成为第二个正式加入CNCF基金会的项目,同年6月正式发布1.0版本。2017年底发布了基于全新存储层的2.0版本,能更好地与容器平台、云平台配合。
强大的数据模型
所有采集的监控数据均以指标(metric)的形式保存在内置的时间序列数据库当中(TSDB)。所有的样本除了基本的指标名称以外,还包含一组用于描述该样本特征的标签。
每一条时间序列由指标名称(Metrics Name)以及一组标签(Labels)唯一标识。每条时间序列按照时间的先后顺序存储一系列的样本值。
强大的查询语言PromQL
Prometheus内置了一个强大的数据查询语言PromQL。 通过PromQL可以实现对监控数据的查询、聚合。同时PromQL也被应用于数据可视化(如Grafana)以及告警当中。
通过PromQL可以轻松回答类似于以下问题:
- 在过去一段时间中95%应用延迟时间的分布范围li>
- 预测在4小时后,磁盘空间占用大致会是什么情况li>
- CPU占用率前5位的服务有哪些滤)
高效
对于监控系统而言,大量的监控任务必然导致有大量的数据产生。而Prometheus可以高效地处理这些数据,对于单一Prometheus Server实例而言它可以处理:
- 数以百万的监控指标
- 每秒处理数十万的数据点。
可扩展
Prometheus是如此简单,因此你可以在每个数据中心、每个团队运行独立的Prometheus Sevrer。Prometheus对于联邦集群的支持,可以让多个Prometheus实例产生一个逻辑集群,当单实例Prometheus Server处理的任务量过大时,通过使用功能分区(sharding)+联邦集群(federation)可以对其进行扩展。
同时Prometheus还支持与其他的监控系统进行集成:Graphite, Statsd, Collected, Scollector, muini, Nagios等。
Prometheus 区还提供了大量第三方实现的监控数据采集支持:JMX, CloudWatch, EC2, MySQL,PostgresSQL, Haskell, Bash, SNMP, Consul, Haproxy, Mesos, Bind, CouchDB, Django, Memcached, RabbitMQ, Redis, RethinkDB, Rsyslog等等。
可视化
通常来说当我们需要监控一个应用程序时,一般需要该应用程序提供对相应监控系统协议的支持。因此应用程序会与所选择的监控系统进行绑定。为了减少这种绑定所带来的限制。对于决策者而言要么你就直接在应用中集成该监控系统的支持,要么就在外部创建单独的服务来适配不同的监控系统。
而对于Prometheus来说,使用Prometheus的client library的输出格式不止支持Prometheus的格式化数据,也可以输出支持其它监控系统的格式化数据,比如Graphite。
因此你甚至可以在不使用Prometheus的情况下,采用Prometheus的client library来让你的应用程序支持监控数据采集。
二、Prometheus架构
- Prometheus Server ,里面包含了存储引擎和计算引擎
- Retrieval组件为取数组件,它会主动从Pushgateway或者Exporter拉取指标数据
- Service discovery,可以动态发现要监控的目标。
- TSDB,数据核心存储与查询
- HTTP server,对外提供HTTP服务
采集层:
采集层分为两类,一类是生命周期较短的作业,还有一类是生命周期较长的作业
- 短作业:直接通过API,在退出时将指标推送给pushgateway
- 长作业:Retrieval组件直接从JOB或者EXPORTER拉取数据
应用层:
应用层主要分为两种:一种是AlertManager,另一种是数据可视化
- AlertManager
对接Pagerduty,是一套付费的监控 警系统。可实现短信 警、5分钟无人ack打电话通知、任然无人ack,通知值班人员Manager
Email,发送邮件
…… - 数据可视化
Prometheus build-in WebUI
Grafana
其他基于API开发的客户端
三、Prometheus 相关概念
Prometheus时序数据库
Prometheus按2小时一个block进行存储,每个block由一个目录组成,该目录里包含:一个或者多个chunk文件(保存timeseries数据)、一个metadata文件、一个index文件(通过metric name和labels查找timeseries数据在chunk文件的位置)。
最新写入的数据保存在内存block中,达到2小时后写入磁盘。为了防止程序崩溃导致数据丢失,实现了WAL(write-ahead-log)机制,启动时会以写入日志(WAL)的方式来实现重播,从而恢复数据。
删除数据时,删除条目会记录在独立的tombstone文件中,而不是立即从chunk文件删除。
通过时间窗口的形式保存所有的样本数据,可以明显提高Prometheus的查询效率,当查询一段时间范围内的所有样本数据时,只需要简单的从落在该范围内的块中查询数据即可。
这些2小时的block会在后台压缩成更大的block,数据压缩合并成更高level的block文件后删除低level的block文件。这个和leveldb、rocksdb等LSM树的思路一致。
样本(Sample)
Prometheus会将所有采集到的样本数据以时间序列(time-series)的方式保存在内存数据库中,并且定时保存到硬盘上。time-series是按照时间戳和值的序列顺序存放的,我们称之为向量(vector). 每条time-series通过指标名称(metrics name)和一组标签集(labelset)命名。如下所示,可以将time-series理解为一个以时间为Y轴的数字矩阵:
在time-series中的每一个点称为一个样本(sample),样本由以下三部分组成:
(1)指标(metric):metric name和描述当前样本特征的labelsets;
(2)时间戳(timestamp):一个精确到毫秒的时间戳;
(3)样本值(value): 一个float64的浮点型数据表示当前样本的值。
指标(Metric)
prometheus 监控中,对于采集过来的数据,统一称为 metics数据。所有数据都将按时间序列存储为 Key/Value 对
metrics 是一种对采集数据的总称(metrics 并不代表某一种具体的数据格式,是一种对于度量单位和采集样本的抽象描述)
在形式上,所有的指标(Metric)都通过如下格式标示:
指标的名称(metric name)可以反映被监控样本的含义(比如,http_request_total – 表示当前系统接收到的HTTP请求总量)。指标名称只能由ASCII字符、数字、下划线以及冒 组成并必须符合正则表达式[a-zA-Z_:][a-zA-Z0-9_:]*。
标签(label)反映了当前样本的特征维度,通过这些维度Prometheus可以对样本数据进行过滤,聚合等。标签的名称只能由ASCII字符、数字以及下划线组成并满足正则表达式[a-zA-Z_][a-zA-Z0-9_]*。
其中以__作为前缀的标签,是系统保留的关键字,只能在系统内部使用。标签的值则可以包含任何Unicode编码的字符。在Prometheus的底层实现中指标名称实际上是以__name__=的形式保存在数据库中的,因此以下两种方式均表示的同一条time-series:
四种 Metric 类型
Prometheus 客户端库主要提供四种主要的 metric 类型:
-
Counter
Counter 表示收集的数据是按照某个趋势(增加/减少)一直变化的,我们往往用它记录服务请求总量、错误总数等。一种累加的 metric,典型的应用如:请求的个数,结束的任务数, 出现的错误数等等。
例如,查询 http_requests_total{method=“get”, job=“Prometheus”, handler=“query”} 返回 8,10 秒后,再次查询,则返回 14。
-
Gauge
Gauge 表示搜集的数据是一个瞬时的值,与时间没有关系,可以任意变高变低,往往可以用来记录内存使用率、磁盘使用率等。
例如 Prometheus server 中 go_goroutines, 表示 Prometheus 当前 goroutines 的数量。
-
Histogram
主要用于表示一段时间范围内对数据进行采样(通常是请求持续时间或响应大小),并能够对其指定区间以及总数进行统计,通常它采集的数据展示为直方图。
例如 Prometheus server 中 prometheus_local_storage_series_chunks_persisted, 表示 Prometheus 中每个时序需要存储的 chunks 数量,我们可以用它计算待持久化的数据的分位数。
-
Summary
类似于 Histogram, 典型的应用如:请求持续时间,响应大小。提供观测值的 count 和 sum 功能。提供百分位的功能,即可以按百分比划分跟踪结果。
例如 Prometheus server 中 prometheus_target_interval_length_seconds。
任务(Jobs)和实例(Instance)
在 Prometheus 术语中,一个您可以抓取的 endpoint 被称为一个 instance,通常对应到一个单独的进程。一组同样目的的 instance 的集合,进程因扩展性或可靠性而被复制的叫做一个 Job。
例如,具有四个实例的 API server job:
自动生成标签和时序
当 Prometheus 抓取一个 target 时,它会自动在抓取的时序上附加一些标签,用以识别被抓取的 target:
- job:target 所属的已配置的 job 名称。
- instance:target 被抓取的 URL 的 host:port 部分。
如果在抓取的数据中已经存在这些标签,则行为取决于 honor_labels 配置选项。参考抓取配置文档以获得更多信息。
对于每一个实例抓取,Prometheus 按照以下时序存储样本:
- up{job=””, instance=””}。如果实例健康,则值为 1,也就是可访问,如果抓取失败则值为 0。
- scrape_duration_seconds{job=””, instance=””}:抓取持续时间。
- scrape_samples_post_metric_relabeling{job=””, instance=””}: metric relabel 生效后剩余的样本数。
- scrape_samples_scraped{job=””, instance=””}: target 暴露的样本数量。
- scrape_series_added{job=””, instance=””}: 在一次抓取中新时序的大约数量。v2.10 新增。该 up 时序对于实例可用性监控很有用。
pull metrics(拉取监控指标信息)
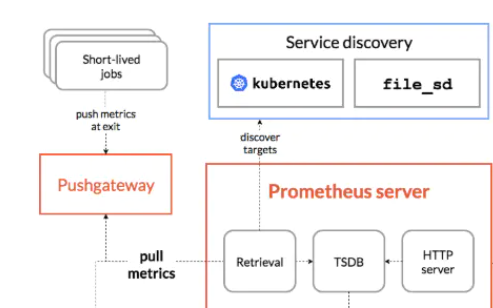

(1)pull 主动拉取形式
pull:指定是客户端(被监控的机器)先安装各类已用的 采集器 ,比如 node_exporters (linux服务器采集器),之后exporters 以守护进程的方式运行 并开始采集数据。
同时 exporter 本身也是一个 http_server,可以对 http 请求做出响应,返回数据(K/V metrics),所以服务端才能以http的方式 pull 客户端的指标信息
(2)push
其实这里就涉及到一个 pushgateway,这个东西类似于一个中转站一样。安装好之后。
客户端的相关job push数据(以K/V metrics形式)到 pushgateway(即客户端主动发送数据到pushgateway),然后 pushgateway push 数据到 prometheus 服务器中去。这是一种被动的数据模式。
PromQL
PromQL(Prometheus Query Language)是 Prometheus 内置的数据查询语言,它能实现对事件序列数据的查询、聚合、逻辑运算等。它并且被广泛应用在 Prometheus 的日常应用当中,包括对数据查询、可视化、告警处理当中。
简单地说,PromQL 广泛存在于以 Prometheus 为核心的监控体系中。所以需要用到数据筛选的地方,就会用到 PromQL。用户可以使用PromQL对时序数据进行查询和聚合。 PromQL的查询结果可以用来在PromQL的浏览器中绘图、以表格展现数据,另外,PromQL的HTTP API也可以被外部系统使用。
当 Prometheus 通过 Exporter 采集到相应的监控指标样本数据后,我们就可以通过 PromQL 对监控样本数据进行查询。
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!