A100 Tensor Core中的新稀疏支持,可以利用DL 络中的细粒度结构稀疏性来使Tensor Core操作的吞吐量增加一倍。
与V100相比,A100中更大,更快的L1高速缓存和共享内存单元提供了每SM聚合容量的1.5倍(192 KB对比每个SM 128 KB),从而为许多HPC和AI工作负载提供了额外的加速。
几个新的SM功能提高了效率和可编程性,降低了软件复杂性。
40 GB HBM2和40 MB L2缓存
为了满足其巨大的计算吞吐量,NVIDIA A100 GPU拥有40 GB的高速HBM2内存,具有一流的1555 GB /秒的内存带宽,与Tesla V100相比增加了73%。此外,A100 GPU拥有更多的片上内存,其中包括40 MB的2级(L2)缓存-比V100大7倍-以最大化计算性能。借助新的分区交叉开关结构,A100 L2缓存提供了V100的L2缓存读取带宽的2.3倍。
为了优化容量利用率,NVIDIA Ampere体系结构提供了L2缓存驻留控件,管理要保留或从缓存中逐出的数据。A100还增加了计算数据压缩功能,使DRAM带宽和L2带宽最多增加4倍,L2容量最多增加2倍。
多实例GPU
全新的多实例GPU(MIG)功能,使A100 Tensor Core GPU可以安全地划分为多达七个用于CUDA应用程序的独立GPU实例,从而为多个用户提供独立的GPU资源以加速其应用程序。
使用MIG,每个实例的处理器都具有贯穿整个内存系统的单独且隔离的路径。片上交叉开关端口,L2缓存库,存储器控制器和DRAM地址总线,唯一地分配给单个实例。确保单个用户的工作负载,预测吞吐量和延迟运行,具有相同的二级缓存分配和DRAM带宽,即使其它任务正在破坏自己的缓存,或使DRAM接口饱和也一样。
MIG在提供定义的QoS和在不同客户端(例如VM,容器和进程)之间提供隔离的同时,提高了GPU硬件利用率。MIG对于具有多租户用例的CSP尤其有利。除了提供增强的安全性,为客户提供GPU利用率保证之外,确保一个客户端不会影响其他客户端的工作或日程安排。
第三代NVIDIA NVLink
在A100 GPU中实现的第三代NVIDIA高速NVLink互连和新的NVIDIA NVSwitch大大增强了多GPU的可扩展性,性能和可靠性。通过每个GPU和交换机的更多链接,新的NVLink提供了更高的GPU-GPU通信带宽,改善了错误检测和恢复功能。
第三代NVLink每对信 的数据速率为50 Gbit / sec,几乎是V100中25.78 Gbit / sec速率的两倍。单个A100 NVLink与V100相似,在每个方向上可提供25 GB /秒的带宽,与V100相比,每个链接仅使用一半的信 对数量。A100中的链接总数从V100中的6条增加到12条,总带宽为600 GB /秒,而V100为300 GB /秒。
支持NVIDIA Magnum IO和Mellanox互连解决方案
A100 Tensor Core GPU与NVIDIA Magnum IO和Mellanox最新的InfiniBand和以太 互连解决方案完全兼容,加速多节点连接。
Magnum IO API集成了计算, 络,文件系统和存储,可为多GPU,多节点加速系统最大化I / O性能。与CUDA-X库接口,加速从AI和数据分析到可视化的各种工作负载的I / O。
具有SR-IOV的PCIe Gen 4
A100 GPU支持PCI Express Gen 4(PCIe Gen 4),通过提供31.5 GB /秒的速度(相对于x16连接的15.75 GB /秒),使PCIe 3.0 / 3.1的带宽增加了一倍。更快的速度对于连接到支持PCIe 4.0的CPU的A100 GPU以及支持快速 络接口(例如200 Gbit / sec InfiniBand)特别有利。
A100还支持单根输入/输出虚拟化(SR-IOV),从而可以为多个进程或VM共享和虚拟化单个PCIe连接。
改进的错误和故障检测,隔离和控制
通过检测,包含并经常纠正错误和故障,而不是强制GPU重置,最大化GPU的正常运行时间和可用性至关重要。在大型多GPU群集和单GPU多租户环境(例如MIG配置)中尤其如此。A100 Tensor Core GPU包括改进错误/故障归因,隔离和控制的新技术。
异步复制
A100 GPU包含一个新的异步复制指令,可将数据直接从全局内存加载到SM共享内存中,而无需使用中间寄存器文件(RF)。异步复制减少了寄存器文件的带宽,更有效地使用了内存带宽,降低了功耗。顾名思义,异步复制可以在SM执行其它计算时在后台完成。
异步屏障
A100 GPU在共享内存中提供了硬件加速的障碍。这些屏障可使用CUDA 11以符合ISO C ++的屏障对象的形式使用。异步屏障将屏障到达和等待操作分开,可用于通过SM中的计算,将异步副本从全局内存重叠到共享内存中。可用于使用CUDA线程来实现生产者-消费者模型。屏障还提供了以不同的粒度(不仅仅是扭曲或块级别)同步CUDA线程的机制。
任务图加速
CUDA任务图为将工作提交到GPU提供了更有效的模型。任务图由依赖关系连接的一系列操作(例如内存副本和内核启动)组成。任务图启用了一次定义和重复运行的执行流程。预定义的任务图允许在一次操作中启动任意数量的内核,从而大大提高了应用程序的效率和性能。A100添加了新的硬件功能,以使任务图中的 格之间的路径显着加快。
A100 GPU硬件架构
NVIDIA GA100 GPU由多个GPU处理群集(GPC),纹理处理群集(TPC),流式多处理器(SM)和HBM2内存控制器组成。
GA100 GPU的完整实现包括以下单元:
? 每个完整GPU 8个GPC,8个TPC / GPC,2个SM / TPC,16个SM / GPC,128个SM
? 每个完整GPU 64个FP32 CUDA内核/ SM,8192个FP32 CUDA内核
? 每个完整GPU 4个第三代Tensor核心/ SM,512个第三代Tensor核心
? 6个HBM2堆栈,12个512位内存控制器
GA100 GPU的A100 Tensor Core GPU实现包括以下单元:
? 7个GPC,7个或8个TPC / GPC,2个SM / TPC,最多16个SM / GPC,108个SM
? 每个GPU 64个FP32 CUDA内核/ SM,6912个FP32 CUDA内核
? 每个GPU 4个第三代Tensor内核/ SM,432个第三代Tensor内核
? 5个HBM2堆栈,10个512位内存控制器
具有128个SM的完整GA100 GPU。A100基于GA100,具有108个SM。
A100 SM架构
新的A100 SM大大提高了性能,建立在Volta和Turing SM体系结构中引入的功能的基础上,增加了许多新功能和增强功能。
A100 SM图如图5所示。Volta和Turing每个SM具有八个Tensor核心,每个Tensor核心每个时钟执行64个FP16 / FP32混合精度融合乘加(FMA)操作。A100 SM包括新的第三代Tensor内核,每个内核每个时钟执行256个FP16 / FP32 FMA操作。A100每个SM有四个Tensor内核,每个时钟总共可提供1024个密集的FP16 / FP32 FMA操作,与Volta和Turing相比,每个SM的计算能力提高了2倍。
SM的主要功能在此处简要描述:
? 第三代Tensor核心:
o 加速所有数据类型,包括FP16,BF16,TF32,FP64,INT8,INT4和二进制。
o 新的Tensor Core稀疏功能利用深度学习 络中的细粒度结构稀疏性,使标准Tensor Core操作的性能提高了一倍。
o A100中的TF32 Tensor Core操作提供了一条简单的路径来加速DL框架和HPC中的FP32输入/输出数据,运行速度比V100 FP32 FMA操作快10倍,而具有稀疏性时则快20倍。
o FP16 / FP32混合精度Tensor Core操作为DL提供了空前的处理能力,运行速度比V100 Tensor Core操作快2.5倍,稀疏性提高到5倍。
o BF16 / FP32混合精度Tensor Core操作以与FP16 / FP32混合精度相同的速率运行。
o FP64 Tensor Core操作为HPC提供了前所未有的双精度处理能力,运行速度是V100 FP64 DFMA操作的2.5倍。
o 具有稀疏性的INT8 Tensor Core操作为DL推理提供了空前的处理能力,运行速度比V100 INT8操作快20倍。
? 192 KB的共享共享内存和L1数据高速缓存,比V100 SM大1.5倍。
? 新的异步复制指令将数据直接从全局内存加载到共享内存中,可以选择绕过L1缓存,不需要使用中间寄存器文件(RF)。
? 与新的异步复制指令一起使用的新的基于共享内存的屏障单元(异步屏障)。
? L2缓存管理和驻留控制的新说明。
? CUDA合作小组支持新的线程级减少指令。
? 许多可编程性方面的改进,以减少软件的复杂性。
图6比较了V100和A100 FP16 Tensor Core操作,还比较了V100 FP32,FP64和INT8标准操作与相应的A100 TF32,FP64和INT8 Tensor Core操作。吞吐量是每个GPU的总和,其中A100使用针对FP16,TF32和INT8的稀疏Tensor Core操作。左上方的图显示了两个V100 FP16 Tensor核心,因为一个V100 SM每个SM分区有两个Tensor核心,而A100 SM一个。
图7. TensorFloat-32(TF32)为FP32的范围提供了FP16的精度(左)。A100使用TF32加速张量数学运算,同时支持FP32输入和输出数据(右),从而可以轻松集成到DL和HPC程序中并自动加速DL框架。
用于AI训练的默认数学是FP32,没有张量核心加速。NVIDIA Ampere架构引入了对TF32的新支持,使AI训练默认情况下可以使用张量内核,无需用户方面的努力。非张量运算继续使用FP32数据路径,TF32张量内核读取FP32数据并使用与FP32相同的范围,内部精度降低,再生成标准IEEE FP32输出。TF32包含一个8位指数(与FP32相同),10位尾数(与FP16相同的精度)和1个符 位。
与Volta一样,自动混合精度(AMP)可以将FP16与混合精度一起用于AI训练,只需几行代码更改即可。使用AMP,A100的Tensor Core性能比TF32快2倍。
总而言之,用于DL训练的NVIDIA Ampere架构数学的用户选择如下:
? 默认情况下,使用TF32 Tensor Core,不调整用户脚本。与A100上的FP32相比,吞吐量高达8倍,而与V100上的FP32相比,吞吐量高达10倍。
? FP16或BF16混合精度训练应用于最大训练速度。与TF32相比,吞吐量高达2倍,与A100上的FP32相比,吞吐量高达16倍,与V100上的FP32相比,吞吐量高达20倍。
A100 Tensor核心可加速HPC
HPC应用程序的性能需求正在迅速增长。众多科学研究领域的许多应用程序都依赖于双精度(FP64)计算。
为了满足HPC计算的快速增长的计算需求,A100 GPU支持Tensor操作,加速符合IEEE的FP64计算,提供的FP64性能是NVIDIA Tesla V100 GPU的2.5倍。
A100上新的双精度矩阵乘法加法指令,替换了V100上的八条DFMA指令,减少了指令提取,调度开销,寄存器读取,数据路径功率和共享存储器读取带宽。
A100中的每个SM总共计算64个FP64 FMA操作/时钟(或128个FP64操作/时钟),这是Tesla V100吞吐量的两倍。具有108个SM的A100 Tensor Core GPU的FP64峰值吞吐量为19.5 TFLOPS,是Tesla V100的2.5倍。
借助对这些新格式的支持,A100 Tensor Core可用于加速HPC工作负载,迭代求解器和各种新的AI算法。
V100 A100 A100稀疏度1 A100加速 A100稀疏加速
A100 FP16和 V100 FP16 31.4 TFLOPS 78 TFLOPS 不适用 2.5倍 不适用
A100 FP16 TC和 V100 FP16 TC 125 TFLOPS 312 TFLOPS 624 TFLOPS 2.5倍 5倍
A100 BF16 TC和V100 FP16 TC 125 TFLOPS 312 TFLOPS 624 TFLOPS 2.5倍 5倍
A100 FP32和 V100 FP32 15.7 TFLOPS 19.5 TFLOPS 不适用 1.25倍 不适用
A100 TF32 TC和 V100 FP32 15.7 TFLOPS 156 TFLOPS 312 TFLOPS 10倍 20倍
A100 FP64和 V100 FP64 7.8 TFLOPS 9.7 TFLOPS 不适用 1.25倍 不适用
A100 FP64 TC和 V100 FP64 7.8 TFLOPS 19.5 TFLOPS 不适用 2.5倍 不适用
A100 INT8 TC与 V100 INT8 62 TOPS 624 TOPS 1248 TOPS 10倍 20倍
A100 INT4 TC 不适用 1248 TOPS 2496 TOPS 不适用 不适用
A100二进制TC 不适用 4992 TOPS 不适用 不适用 不适用
表2. A100在V100上的提速(TC = Tensor Core,GPU以各自的时钟速度)。
1)使用新的稀疏功能实现有效的TOPS / TFLOPS
A100引入了细粒度的结构化稀疏性
借助A100 GPU,NVIDIA引入了细粒度的结构稀疏性,这是一种新颖的方法,可将深度神经 络的计算吞吐量提高一倍。
深度学习中可能会出现稀疏性,各个权重的重要性会在学习过程中演变, 络训练结束时,只有权重的一个子集在确定学习的输出时获得了有意义的目的。不再需要其余的权重。
细粒度的结构化稀疏性,对允许的稀疏性模式施加了约束,使硬件更有效地执行输入操作数的必要对齐。由于深度学习 络能够在训练过程中根据训练反馈调整权重,NVIDIA工程师通常发现结构约束不会影响训练 络进行推理的准确性,可以推断出具有稀疏性的加速。
对于训练加速,需要在过程的早期引入稀疏性,提供性能优势,在不损失准确性的情况下,进行训练加速的方法是一个活跃的研究领域。
稀疏矩阵定义
通过新的2:4稀疏矩阵定义强制执行结构,在每个四项向量中允许两个非零值。A100在行上支持2:4的结构化稀疏性,如图9所示。
由于矩阵的定义明确,可以对其进行有效压缩,将内存存储量和带宽减少近2倍。
图10.CSP多用户节点(A100之前的版本)。加速的GPU实例仅在完全物理GPU粒度下,供不同组织中的用户使用,即使用户应用程序不需要完整的GPU也是如此。
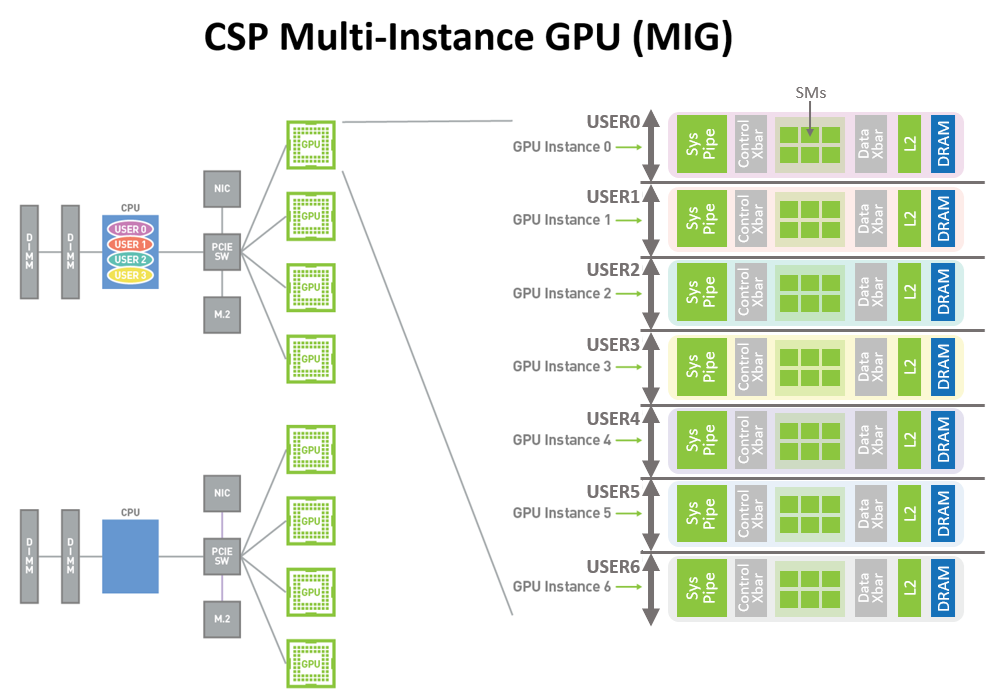

图11.具有MIG的CSP多用户图。来自同一组织或不同组织的多个独立用户,在单个物理GPU中分配专用,受保护和隔离的GPU实例。
错误和故障检测,隔离和控制
通过检测,包含并经常纠正错误和故障,不是强制GPU重置来提高GPU的正常运行时间和可用性至关重要。在大型,多GPU群集和单GPU,多租户环境(例如MIG配置)中尤其重要。
NVIDIA Ampere架构A100 GPU包括新技术,可改善错误/故障归因(归因于导致错误的应用程序),隔离(隔离有故障的应用程序,不会影响在同一GPU或GPU群集中运行的其他应用程序),限制(确保一个应用程序中的错误不会泄漏并影响其他应用程序)。这些故障处理技术对于MIG环境尤其重要,确保共享单个GPU的客户端之间的适当隔离和安全性。
连接NVLink的GPU现在具有更强大的错误检测和恢复功能。远程GPU上的页面错误会通过NVLink发送回源GPU。远程访问故障通信是大型GPU计算群集的一项关键弹性功能,有助于确保一个进程或VM中的故障,不会导致其它进程或VM停机。
A100 GPU包括其他几个新的和改进的硬件功能,可以增强应用程序性能。
CUDA 11在NVIDIA Ampere架构GPU方面的进步
在NVIDIA CUDA并行计算平台上构建了成千上万个GPU加速的应用程序。CUDA的灵活性和可编程性使其成为研究和部署新的DL和并行计算算法的首选平台。
NVIDIA Ampere架构GPU旨在提高GPU的可编程性和性能,降低软件复杂性。NVIDIA Ampere架构的GPU和CUDA编程模型的改进,加快程序执行速度,降低许多操作的延迟和开销。
CUDA 11的新功能为第三代Tensor核心,稀疏性,CUDA图形,多实例GPU,L2缓存驻留控件以及NVIDIA Ampere架构,一些新功能提供了编程和API支持。
结论
NVIDIA的使命,加速时代的达芬奇和爱因斯坦的工作。科学家,研究人员和工程师致力于使用高性能计算(HPC)和AI解决全球最重要的科学,工业和大数据挑战。
NVIDIA A100 Tensor Core GPU,在我加速数据中心平台中实现了下一个巨大飞跃,可在任何规模上提供无与伦比的加速性能,使这些创新者能够终其一生。A100支持众多应用领域,包括HPC,基因组学,5G,渲染,深度学习,数据分析,数据科学和机器人技术。
推进当今最重要的HPC和AI应用程序-个性化医学,对话式AI和深度推荐系统-要求研究人员变得更大。A100为NVIDIA数据中心平台提供动力,包括Mellanox HDR InfiniBand,NVSwitch,NVIDIA HGX A100和Magnum IO SDK,进行扩展。这个集成的技术团队,有效地扩展到成千上万个GPU,以前所未有的速度训练最复杂的AI 络。
A100 GPU的新MIG功能,将每个A100划分为多达七个GPU加速器,实现最佳利用率,有效地提高GPU资源利用率,以及GPU对更多用户和GPU加速应用程序的访问。借助A100的多功能性,基础架构管理人员,可以最大化其数据中心中每个GPU的效用,满足从最小的工作到最大的多节点工作负载的不同规模的性能需求。
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!