Spire.PDF for Java 支持通过 PdfGrid 类和 PdfTable 类在 PDF 页面中绘制表格,在“Java 创建并格式并 PDF 表格”一文中介绍了如何绘制表格。本篇文章将介绍使用 PdfTableExtractor 类来提取 PDF 中的表格的方法。
安装 Spire.PDF for Java
首先,您需要在 Java 程序中添加 Spire.Pdf.jar 文件作为依赖项。您可以从这个链接下载 JAR 文件;如果您使用 Maven,则可以通过在 pom.xml 文件中添加以下代码导入 JAR 文件。
<repositories> <repository> <id>com.e-iceblue</id> <url>https://repo.e-iceblue.cn/repository/maven-public/</url> </repository></repositories><dependencies> <dependency> <groupId>e-iceblue</groupId> <artifactId>spire.pdf</artifactId> <version>4.12.1</version> </dependency></dependencies>
提取 PDF 中的表格
提取表格的主要步骤如下:
- 创建 PdfDocument 类的对象,并通过 PdfDocument.loadFromFile() 方法加载 PDF 文档。
- 实例化 StringBuilder 和 PdfTableExtractor 类的实例。
- 循环遍历 PDF 页面,获取页面中的表格,存入 PdfTable[] 数组。
- 遍历所有表格,获取表格行或列,并通过 PdfTable.GetText() 方法获取表格中的文本。
- 将获取的文本数据保存为 txt 文件。
import com.spire.pdf.*;import com.spire.pdf.utilities.PdfTable;import com.spire.pdf.utilities.PdfTableExtractor;import java.io.FileWriter;import java.io.IOException;public class ExtractTable { public static void main(String[] args)throws IOException { //实例化PdfDocument类的对象 PdfDocument pdf = new PdfDocument(); //加载PDF文档 pdf.loadFromFile("test.pdf"); //创建StringBuilder类的实例 StringBuilder builder = new StringBuilder(); //创建PdfTableExtractor类的对象 PdfTableExtractor extractor = new PdfTableExtractor(pdf); //遍历每一页 for (int page = 0; page < pdf.getPages().getCount(); page++) { //提取页面中的表格存入PdfTable[]数组 PdfTable[] tableLists = extractor.extractTable(page); if (tableLists != null && tableLists.length > 0) { //遍历表格 for (PdfTable table : tableLists) { int row = table.getRowCount();//获取表格行 int column = table.getColumnCount();//获取表格列 for (int i = 0; i < row; i++) { for (int j = 0; j < column; j++) { //获取表格中的文本内容 String text = table.getText(i, j); //将获取的text写入StringBuilder容器 builder.append(text+" "); } builder.append("rn"); } } } } //保存为txt文档 FileWriter fileWriter = new FileWriter("ExtractedTable.txt"); fileWriter.write(builder.toString()); fileWriter.flush(); fileWriter.close(); }}
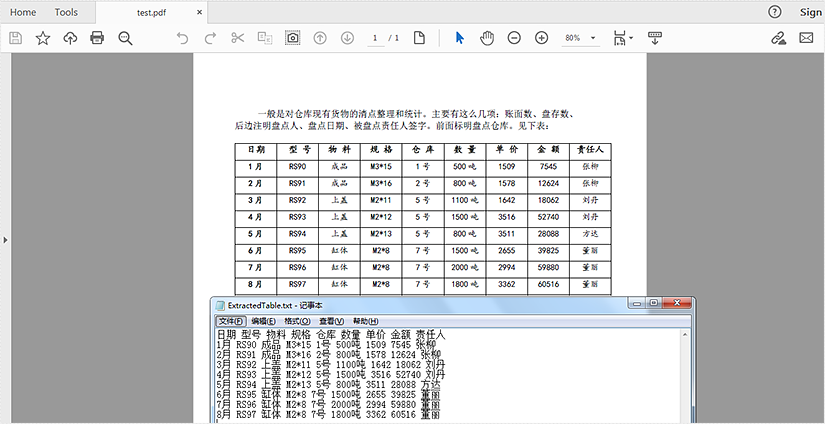
表格内容读取结果:

标签:
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!