在dbForge Studio for SQL Server中借助SQL Profiler对执行计划进行分步分析,可以检测查询性能的瓶颈。
dbForge Studio for SQL Server为有效的探索、分析SQL Server数据库中的大型数据集提供全面的解决方案,并设计各种 表以帮助作出合理的决策。
dbForge Studio for SQL Server最新试用版
更多内容点击查看上一篇
让我们通过执行“比较所选结果”命令来比较结果:
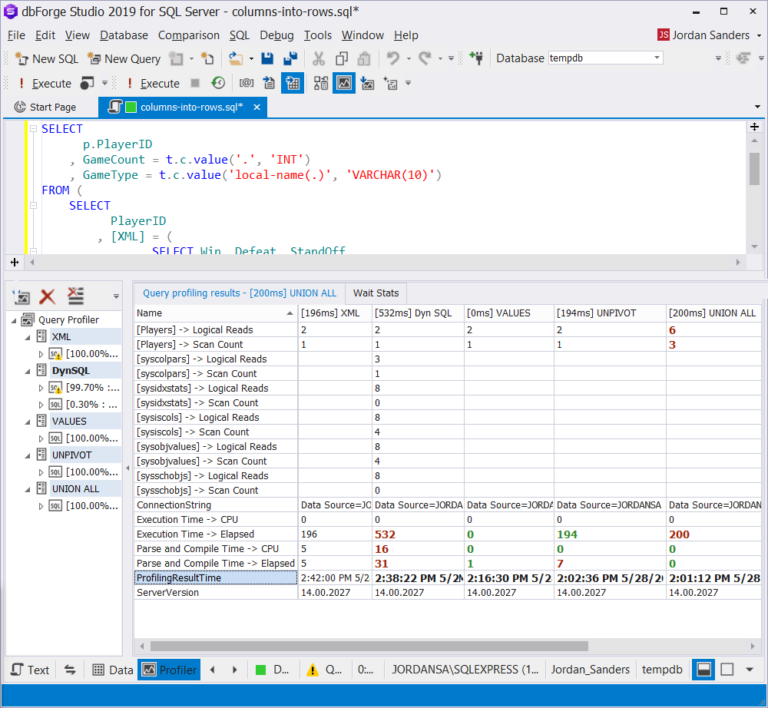

我们必须说,UNPIVOT和VALUES查询的执行速度没有明显差异。这适用于将列简单转换为行的情况。
让我们检查另一个任务,我们需要为每个玩家找到游戏中最频繁的结果。
我们将尝试在UNPIVOT声明的帮助下完成此任务:
SELECT PlayerID , GameType = ( SELECT TOP 1 GameType FROM dbo.Players UNPIVOT ( GameCount FOR GameType IN ( Win, Defeat, StandOff ) ) unpvt WHERE PlayerID = p.PlayerID ORDER BY GameCount DESC )FROM dbo.Players p
在执行计划中,它表明瓶颈是多重数据读取和排序,这对于组织数据行是必需的:
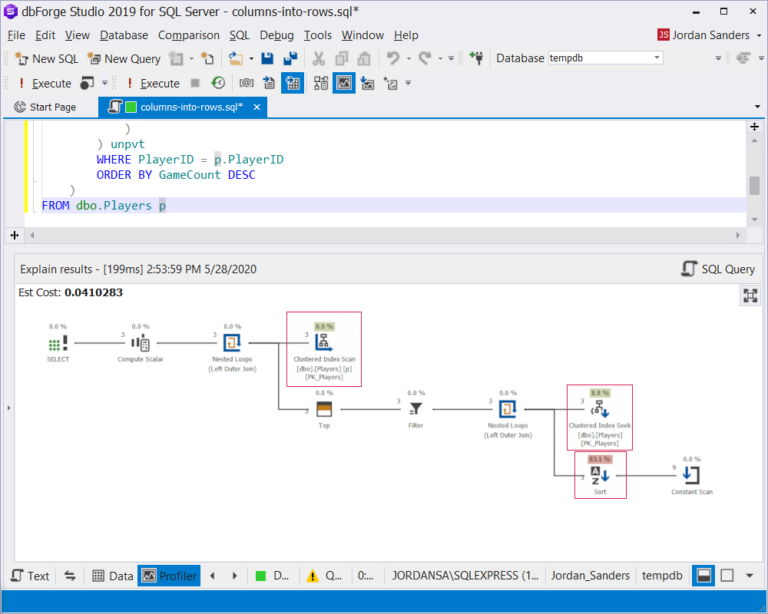
如果我们记得可以使用外部查询块中的列,则很容易摆脱多重数据读取:
SELECT p.PlayerID , GameType = ( SELECT TOP 1 GameType FROM (SELECT t = 1) t UNPIVOT ( GameCount FOR GameType IN ( Win, Defeat, StandOff ) ) unpvt ORDER BY GameCount DESC )FROM dbo.Players p
消除了多次读取数据,但是最耗资源的操作–排序仍然存在:
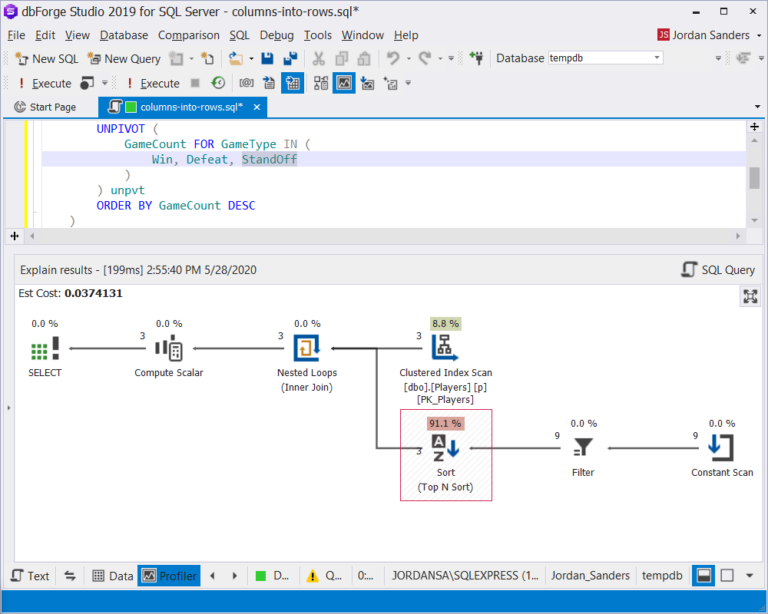
这就是VALUES语句在此任务期间的行为:
SELECT t.PlayerID , GameType = ( SELECT TOP 1 GameType FROM ( VALUES (Win, 'Win') , (Defeat, 'Defeat') , (StandOff, 'StandOff') ) t (GameCount, GameType) ORDER BY GameCount DESC )FROM dbo.Players t
正如我们期望的那样,该计划得到了简化,但是仍然存在排序:
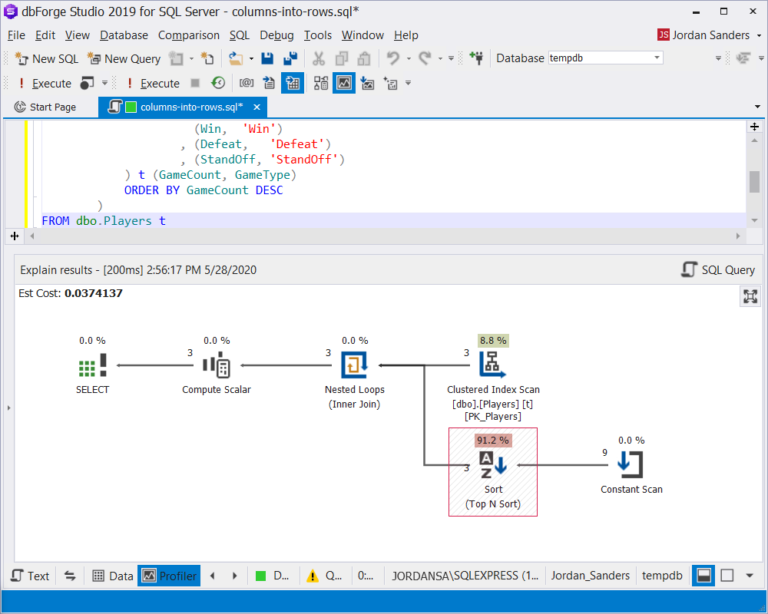
让我们尝试通过使用聚合函数来避免排序:
SELECT t.PlayerID , GameType = ( SELECT TOP 1 GameType FROM ( VALUES (Win, 'Win') , (Defeat, 'Defeat') , (StandOff, 'StandOff') ) t (GameCount, GameType) WHERE GameCount = ( SELECT MAX(Value) FROM ( VALUES (Win), (Defeat), (StandOff) ) t(Value) ) )FROM dbo.Players t
现在执行计划如下所示:
")
我们设法摆脱了排序。
结论
当需要在SQL Server中将列转换为行时,最好使用UNPIVOT或VALUES结构。
如果在转换之后,应该将接收到的数据行用于聚合或排序,那么我们最好使用VALUES结构,这在大多数情况下会导致更有效的执行计划。
对于可能出现不同结构类型且列数不受限制的表,建议使用XML,它与动态SQL不同,可以在表函数内部使用。
在dbForge Studio for SQL Server中借助SQL Profiler对执行计划进行分步分析,可以检测查询性能的瓶颈。
了解更多产品信息或想要购买产品正版授权请点击【咨询在线客服】
标签:
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!