语法有两种主要格式:BNF(及其变体)和PEG。本章节旨在让大家了解这些不同的格式以及何时应该使用它们。
请务必首先查看第1部分、第2部分、第3部分和第4部分!
格式
语法有两种主要格式:BNF(及其变体)和PEG。许多工具都实现了这些理想格式的变体。 一些工具完全使用自定义格式。频繁的自定义格式由三部分语法组成:结合自定义代码的选项,其次是词法分析部分,最后是解析器部分。
鉴于类似BNF的格式通常是上下文无关语法的基础,您还可以看到它以CFG格式标识。
Backus-Naur Form及其变体
Backus-Naur Form(BNF)是最成功的格式,甚至是PEG的基础。但是,这个过程很简单,因此它的基本形式并不常用。我们通常使用更强大的变体。
为了说明为什么这些变体是必要的,我们来展示一个BNF的例子:一个字符的描述。
< letter > ::= "a" | "b" | "c" | "d" | "e" | "f" | "g" | "h" | "i" | "j" | "k" | "l" | "m" | "n" | "o" | "p" | "q" | "r" | "s" | "t" | "u" | "v" | "w" | "x" | "y" | "z"< digit > ::= "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9"< character > ::= < letter > | < digit >
符 < letter >可以在英文字母的任何字母中转换,尽管在我们的例子中只有小写字母是有效的。类似的过程发生在< digit >,它可以指示任何替代数字。第一个问题是你必须单独列出所有的选择;像使用正则表达式一样,不能使用字符类。这很烦人,但通常是可以管理的,除非你必须列出所有的Unicode字符。
一个更难的问题是,没有简单的方法来表示可选的元素或重复。所以,如果你想这样做,你必须依靠布尔逻辑(boolean logic)和替代(|)符 。
< text > ::= < character > | < text > < character >
该规则规定< text >可以由一个字符或一个短的< text >和一个< character >组成。这将是dog的分析树:
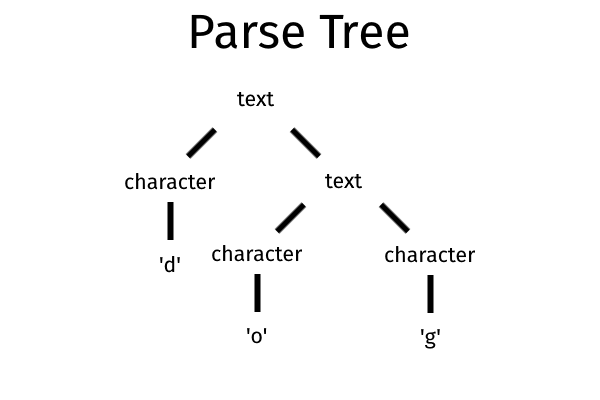

BNF还有许多其他限制:在语法中使用空字符串或格式使用的符 (即:: =)使得复杂,它有一个详细的语法(即你必须在< and >之间包含终端)等等。
Extended Backus-Naur Form
为了解决这些限制,Niklaus Wirth创建了Extended Backus-Naur Form(EBNF),其中包含了他自己的Wirth语法表示法的一些概念。
EBNF是最常用的当代解析工具,尽管工具可能偏离标准符 。EBNF有一个更清洁的符 ,并采用更多的运算符来处理连接或可选的元素。
我们来看看如何在EBNF中编写前面的例子。
letter = "a" | "b" | "c" | "d" | "e" | "f" | "g" | "h" | "i" | "j" | "k" | "l" | "m" | "n" | "o" | "p" | "q" | "r" | "s" | "t" | "u" | "v" | "w" | "x" | "y" | "z" ;digit = "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9" ;character = letter | digit ;text = character , { character } ;
文字符 在连接运算符(,)和可选符 ({..})的帮助下更容易描述。得到的分析树也会更简单。标准的EBNF仍然存在一些问题,如不熟悉的语法。为了克服这个问题,大多数解析工具都采用了受正则表达式启发的语法,并且还支持像字符类这样的附加元素。
ABNF
Augmented BNF (ABNF)是BNF的另一种变体,主要用于描述双向通信协议,并由IETF和几个文档(参见RFC 5234和更新)进行形式化。
ABNF可以和EBNF一样有效,但是有一些怪癖限制了它在互联 协议之外的采用。例如,直到最近,标准规定字符串以不区分大小写的方式进行匹配,这在许多编程语言中匹配标识符是个问题。
ABNF与EBNF有不同的语法;例如,替代运算符是斜杠(/),有时它更好。例如,不需要连接运算符。它还比标准的EBNF有更多的东西。例如,它允许您定义数字范围,如%x30-39,相当于[0-9]。 这也被设计师自己用来包含标准的字符类,比如最终用户可以使用的基本规则。这种规则的一个例子是ALPHA,相当于[a-zA-Z]。
PEG
实际上,它看起来和EBNF相似,但也直接支持广泛使用的东西,比如字符范围(字符类)——虽然它也有一些实际上并不那么实际的差异,比如使用更正式的箭头符 (←) 更常见的等 (=)。前面的例子可以用PEG来写。
letter ← [a-z]digit ← [0-9]character ← letter / digittext ← character+
正如你所看到的,这是程序员写的最明显的方式:用字符类和正则表达式运算符。唯一的异常是替代运算符(/)和箭头字符,事实上,PEG的许多实现使用“equals”字符。
实用的方法是PEG形式化的基础:创建它是为了描述更自然的编程语言。这是因为上下文无关文法起源于描述自然语言的工作。从理论上讲,CFG是一个生成语法,而PEG是一个分析语法。
第一个应该是用语法描述的语言只生成有效句子的一种配方。它不必与解析算法相关。相反,第二种类型直接定义了该语言的解析器的结构和语义。
PEG与CFG
这种理论差异的实际意义是有限的:PEG与packrat算法更密切相关,但基本上这是它。例如,一般来说,PEG(packrat)不允许左递归。虽然可以修改算法本身来支持它,但是这消除了线性时间解析属性。另外,PEG解析器通常是无扫描器的解析器。
PEG和CFG之间最重要的区别可能是PEG的选择顺序是有意义的,而CFG则不是。如果有许多可能的有效方法来解析输入,则CFG将不明确,因此将返回错误。通常错误的意思是,一些采用CFG的解析器可以处理模糊的语法;例如,向开发者提供所有可能的有效结果,并让他们把它整理出来。相反,由于第一个适用的选择将被选择,PEG完全消除了歧义。因此,PEG永远不会含糊不清。
这种方法的缺点是,在列出可能的备选方案时必须更加小心,否则可能会产生意想不到的后果。也就是说,有些选择永远无法匹配。
在下面的例子中,doge永远不会被匹配。由于dog先来,它每次都会被挑选。
dog ← 'dog' / 'doge'
PEG是否可以描述所有可以用CFG定义的语法,这是一个开放的研究领域,但是对于所有的实际目的,它们都可以。
请继续关注第6部分!
推荐阅读:
展望2018年:基于AI人工智能的移动应用程序开发将如何发展
开发一个聊天机器人(Chatbot)应用程序需要花费多少钱/h5>
PS: 更多人工智能、大数据相关视频、培训、公开课,请关注【学院】!
关于人工智能技术的最新资讯和相关开发工具推荐,请<咨询在线客服>!

标签:人工智能解析器语法解析NLP自然语言处理
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!