高阶机器学习中必不可少的TensorFlow框架的深度学习!
TensorFlow
TensorFlow 是相对高阶的机器学习库,用户可以方便地用它设计神经 络结构,而不必为了追求高效率的实现亲自写 C++或 CUDA 代码。它和 Theano 一样都支持自动求导,用户不需要再通过反向传播求解梯度。TensorFlow 是相对高阶的机器学习库,用户可以方便地用它设计神经 络结构,而不必为了追求高效率的实现亲自写 C++或 CUDA 代码。它和 Theano 一样都支持自动求导,用户不需要再通过反向传播求解梯度。其核心代码和 Caffe 一样是用 C++编写的,使用 C++简化了线上部署的复杂度,并让手机这种内存和CPU资源都紧张的设备可以运行复杂模型(Python 则会比较消耗资源,并且执行效率不高)。除了核心代码的 C++接口,TensorFlow 还有官方的 Python、Go 和 Java 接口,是通过 SWIG(Simplified Wrapper and Interface Generator)实现的,这样用户就可以在一个硬件配置较好的机器中用 Python进行实验,并在资源比较紧张的嵌入式环境或需要低延迟的环境中用 C++部署模型。SWIG 支持给 C/C++代码提供各种语言的接口,因此其他脚本语言的接口未来也可以通过 SWIG 方便地添加。不过使用 Python 时有一个影响效率的问题是,每一个 mini-batch 要从 Python 中 feed 到 络中,这个过程在 mini-batch 的数据量很小或者运算时间很短时,可能会带来影响比较大的延迟。
TensorFlow 也有内置的 TF.Learn 和 TF.Slim 等上层组件可以帮助快速地设计新 络,并且兼容 Scikit-learn estimator 接口,可以方便地实现 evaluate、grid search、cross validation 等功能。同时 TensorFlow 不只局限于神经 络,其数据流式图支持非常自由的算法表达,当然也可以轻松实现深度学习以外的机器学习算法。事实上,只要可以将计算表示成计算图的形式,就可以使用 TensorFlow 。用户可以写内层循环代码控制计算图分支的计算,TensorFlow 会自动将相关的分支转为子图并执行迭代运算。TensorFlow 也可以将计算图中的各个节点分配到不同的设备执行,充分利用硬件资源。定义新的节点只需要写一个 Python 函数,如果没有对应的底层运算核,那么可能需要写 C++或者 CUDA 代码实现运算操作。
在数据并行模式上,TensorFlow 和 Parameter Server 很像,但 TensorFlow 有独立的 Variable node,不像其他框架有一个全局统一的参数服务器,因此参数同步更自由。TensorFlow 和 Spark 的核心都是一个数据计算的流式图,Spark 面向的是大规模的数据,支持 SQL 等操作,而 TensorFlow 主要面向内存足以装载模型参数的环境,这样可以最大化计算效率。
TensorFlow 的另外一个重要特点是它灵活的移植性,可以将同一份代码几乎不经过修改就轻松地部署到有任意数量 CPU 或 GPU 的 PC、服务器或者移动设备上。相比于 Theano,TensorFlow 还有一个优势就是它极快的编译速度,在定义新 络结构时,Theano 通常需要长时间的编译,因此尝试新模型需要比较大的代价,而 TensorFlow 完全没有这个问题。TensorFlow 还有功能强大的可视化组件 TensorBoard,能可视化 络结构和训练过程,对于观察复杂的 络结构和监控长时间、大规模的训练很有帮助。TensorFlow 针对生产环境高度优化,它产品级的高质量代码和设计都可以保证在生产环境中稳定运行,同时一旦 TensorFlow 广泛地被工业界使用,将产生良性循环,成为深度学习领域的事实标准。
除了支持常见的 络结构(卷积神经 络(Convolutional Neural Network,CNN)、循环神经 络(Recurent Neural Network,RNN))外,TensorFlow 还支持深度强化学习乃至其他计算密集的科学计算(如偏微分方程求解等)。TensorFlow 此前不支持 symbolic loop,需要使用 Python 循环而无法进行图编译优化,但最近新加入的 XLA 已经开始支持 JIT 和 AOT,另外它使用 bucketing trick 也可以比较高效地实现循环神经 络。TensorFlow 的一个薄弱地方可能在于计算图必须构建为静态图,这让很多计算变得难以实现,尤其是序列预测中经常使用的 beam search。
TensorFlow 在最开始发布时只支持单机,而且只支持 CUDA 6.5 和 cuDNN v2,并且没有官方和其他深度学习框架的对比结果。在 2015 年年底,许多其他框架做了各种性能对比评测,每次 TensorFlow 都会作为较差的对照组出现。那个时期的 TensorFlow 真的不快,性能上仅和普遍认为很慢的 Theano 比肩,在各个框架中可以算是垫底。但是凭借 Google 强大的开发实力,很快支持了新版的 cuDNN (目前支持cuDNN v5.1),在单 GPU 上的性能追上了其他框架。

各深度学习框架在 AlexNet 上的性能对比
目前在单 GPU 的条件下,绝大多数深度学习框架都依赖于 cuDNN,因此只要硬件计算能力或者内存分配差异不大,最终训练速度不会相差太大。但是对于大规模深度学习来说,巨大的数据量使得单机很难在有限的时间完成训练。这时需要分布式计算使 GPU 集群乃至 TPU 集群并行计算,共同训练出一个模型,所以框架的分布式性能是至关重要的。TensorFlow 在 2016 年 4 月开源了分布式版本,使用 16 块 GPU 可达单 GPU 的 15 倍提速,在 50 块 GPU 时可达到 40 倍提速,分布式的效率很高。目前原生支持的分布式深度学习框架不多,只有 TensorFlow、CNTK、DeepLearning4J、MXNet 等。不过目前 TensorFlow 的设计对不同设备间的通信优化得不是很好,其单机的 reduction 只能用 CPU 处理,分布式的通信使用基于 socket 的 RPC,而不是速度更快的 RDMA,所以其分布式性能可能还没有达到最优。
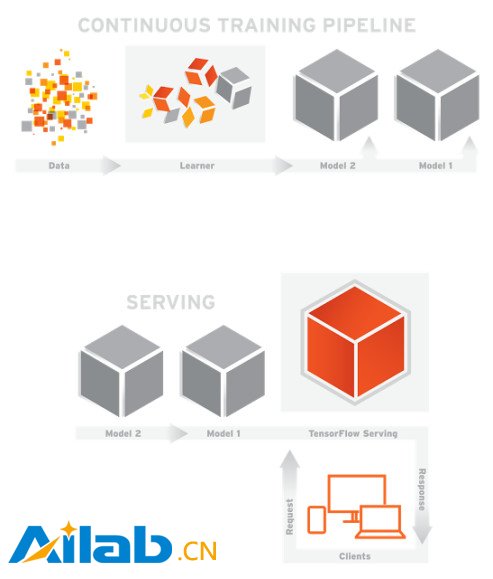
Google 在 2016 年 2 月开源了 TensorFlow Serving,这个组件可以将 TensorFlow 训练好的模型导出,并部署成可以对外提供预测服务的 RESTful 接口,如图 2-2 所示。有了这个组件,TensorFlow 就可以实现应用机器学习的全流程:从训练模型、调试参数,到打包模型,最后部署服务,名副其实是一个从研究到生产整条流水线都齐备的框架。这里引用 TensorFlow 内部开发人员的描述:“ TensorFlow Serving 是一个为生产环境而设计的高性能的机器学习服务系统。它可以同时运行多个大规模深度学习模型,支持模型生命周期管理、算法实验,并可以高效地利用 GPU 资源,让 TensorFlow 训练好的模型更快捷方便地投入到实际生产环境”。除了 TensorFlow 以外的其他框架都缺少为生产环境部署的考虑,而 Google 作为广泛在实际产品中应用深度学习的巨头可能也意识到了这个机会,因此开发了这个部署服务的平台。TensorFlow Serving 可以说是一副王牌,将会帮 TensorFlow 成为行业标准做出巨大贡献。
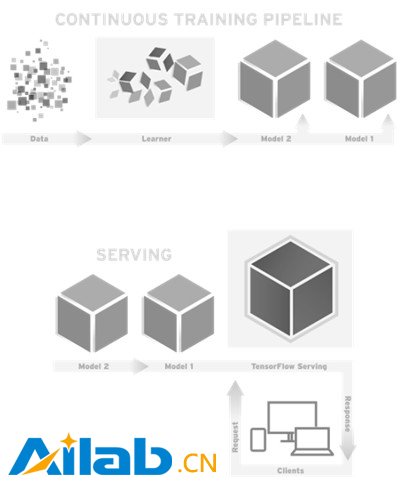
TensorFlow Serving 架构
TensorBoard 是 TensorFlow 的一组 Web 应用,用来监控 TensorFlow 运行过程,或可视化 Computation Graph。TensorBoard 目前支持五种可视化:标量(scalars)、图片(images)、音频(audio)、直方图(histograms)和计算图(Computation Graph)。TensorBoard 的 Events Dashboard 可以用来持续地监控运行时的关键指标,比如 loss、学习速率(learning rate)或是验证集上的准确率(accuracy);Image Dashboard 则可以展示训练过程中用户设定保存的图片,比如某个训练中间结果用 Matplotlib 等绘制(plot)出来的图片;Graph Explorer 则可以完全展示一个 TensorFlow 的计算图,并且支持缩放拖曳和查看节点属性。TensorBoard 的可视化效果如图所示
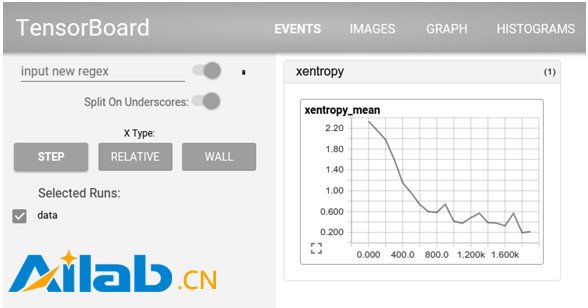
TensorBoard 的 loss 标量的可视化
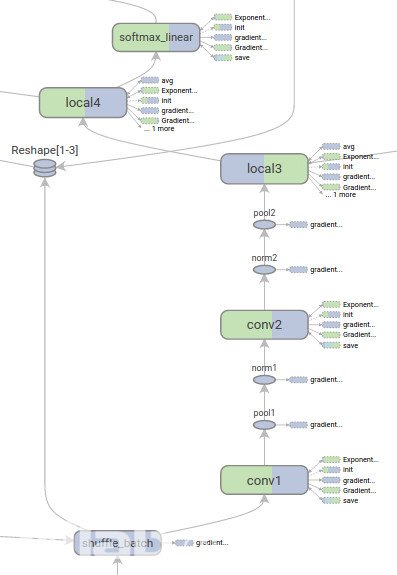
TensorBoard 的模型结构可视化
更多行业资讯,更新鲜的技术动态,尽在学院。

标签:
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!