SQL Server表变量概述
表变量是一种SQL Server数据类型,用于存储与临时表相似的临时数据。
表变量的特性如下:
- 表变量仅在当前批处理查询中可用。
- 表变量不能更改其定义。
- 不必直接删除表变量。
- 如果某些事务将更改添加到表变量,则在事务回滚期间不会回滚这些更改。
- 默认情况下,不收集表变量的统计信息。
- 以下语法描述了如何声明表变量:
DECLARE @tbl TABLE…;
为了继续,我们将举例说明如何创建一个临时表,如何用测试数据填充它,以及重新编译一个表变量。
创建一个SQL Server临时表
现在,我们将创建一个MyLocalTempTable临时表,该表具有一个ID字段的主键和两个非聚集索引–分别用于InsertUTCDate和Ind字段的ix_InsertUTCDate和ix_Ind。然后,我们用测试数据填充该表变量。
要在屏幕上输出内容,请使用以下代码片段:
DECLARE @MyLocalTempTable TABLE ( [ID] INT PRIMARY KEY, [Value] NVARCHAR(255), [Ind] INT, [InsertUTCDate] DATE DEFAULT(GETUTCDATE()), INDEX ix_InsertUTCDate NONCLUSTERED ([InsertUTCDate]), INDEX ix_Ind NONCLUSTERED ([Ind]) ); sri INSERT INTO @MyLocalTempTable ([ID], [Value], [Ind]) SELECT 1, N'177', 1 UNION ALL SELECT 2, N'355', 1 UNION ALL SELECT 3, N'777 ID', 2; SELECT * FROM @MyLocalTempTable WHERE [Ind]=1;
查询的实际执行计划如下:
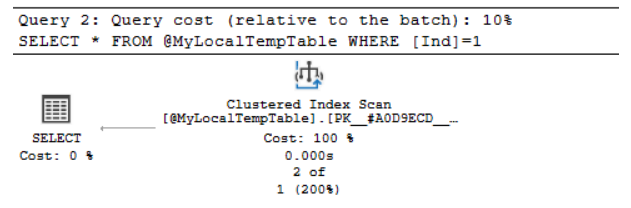

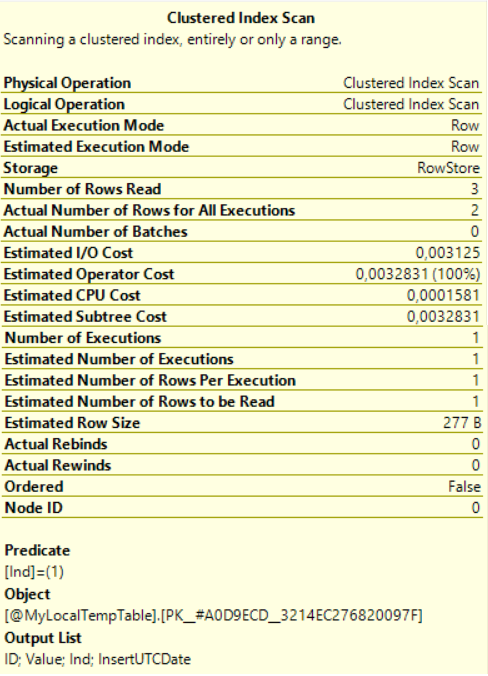
在实际的执行计划中,对聚集索引执行扫描。注意:
- 实际读取的行数和预计读取的行数值不相同。
- 行的所有执行的实际数量和行每个执行的人数估计值不匹配两种。
因此,缺少统计信息。更准确地说,在表变量中,总是只有一行。表变量的这种行为将不允许针对大量数据制定最佳执行计划。
但是,如果我们应用RECOMPILE选项,它将计算统计信息,并且实际的执行计划将变得最佳:
DECLARE @MyLocalTempTable TABLE ( [ID] INT PRIMARY KEY, [Value] NVARCHAR(255), [Ind] INT, [InsertUTCDate] DATE DEFAULT(GETUTCDATE()), INDEX ix_InsertUTCDate NONCLUSTERED ([InsertUTCDate]), INDEX ix_Ind NONCLUSTERED ([Ind]) ); INSERT INTO @MyLocalTempTable ([ID], [Value], [Ind]) SELECT 1, N'177', 1 UNION ALL SELECT 2, N'355', 1 UNION ALL SELECT 3, N'777 ID', 2; SELECT * FROM @MyLocalTempTable WHERE [Ind]=1 OPTION (RECOMPILE);
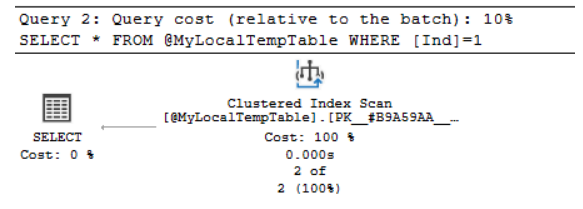
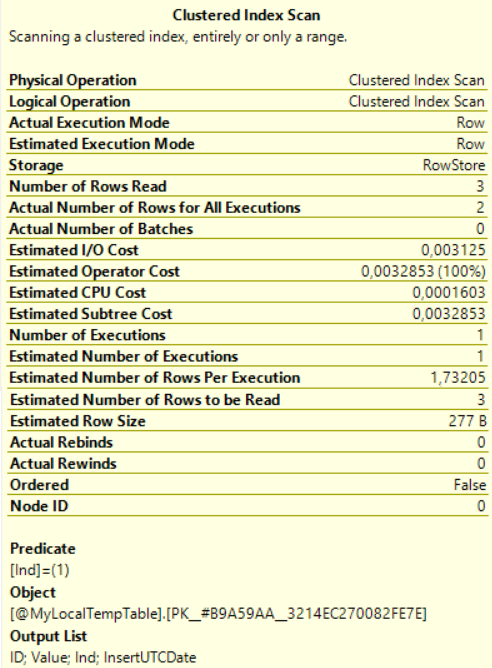
和以前一样,我们可以看到实际计划中对聚集索引的扫描。注意:
- 现在,“实际读取的行数”和“预计读取的行数”值匹配。
- 该行对所有执行的实际结果数和每页行数执行的人数估计值接近匹配。
这意味着统计数据更相关。
默认情况下,不为表变量创建统计信息。为了澄清这一点,请执行以下代码片段,并分析最新选择的实际执行计划:
DECLARE @MyLocalTempTable TABLE ( [ID] INT PRIMARY KEY, [Value] NVARCHAR(255), [Ind] INT, [InsertUTCDate] DATE DEFAULT(GETUTCDATE()), INDEX ix_InsertUTCDate NONCLUSTERED ([InsertUTCDate]), INDEX ix_Ind NONCLUSTERED ([Ind]) ); INSERT INTO @MyLocalTempTable ([ID], [Value], [Ind]) SELECT 1, N'177', 1 UNION ALL SELECT 2, N'355', 1 UNION ALL SELECT 3, N'777 ID', 2; SELECT [Ind] FROM @MyLocalTempTable WHERE [Ind]=1 OPTION (RECOMPILE);

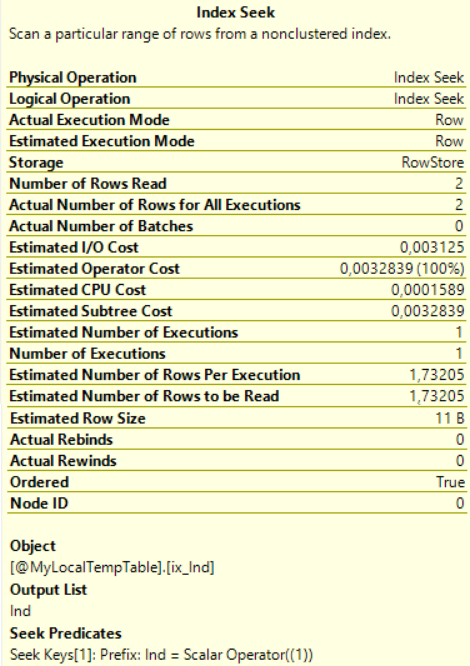
如我们所见,实际计划对Ind字段的ix_Ind非聚集索引使用Index Seek,而不是根据聚集索引进行扫描。
由于重新编译选项,该行读取的实际数量和行的估计数读值几乎一致,还有对所有执行行的实际结果数和每页行数执行的人数估计值。这表明统计数据更加相关。
但是,默认情况下,表变量统计信息是不相关的。当我们应用RECOMPILE选项时,统计信息更接近于实际值,但仍然相差很大。结果,随着表变量中数据的增加,执行计划将进一步偏离最佳计划。
让我们执行以下代码片段:
SELECT * FROM @MyLocalTempTable WHERE [Ind]=1 OPTION (RECOMPILE); BEGIN TRAN UPDATE @MyLocalTempTable SET [Value]=NULL WHERE [Ind]=1; SELECT * FROM @MyLocalTempTable WHERE [Ind]=1 OPTION (RECOMPILE); ROLLBACK TRAN SELECT * FROM @MyLocalTempTable WHERE [Ind]=1 OPTION (RECOMPILE);
输出如下:
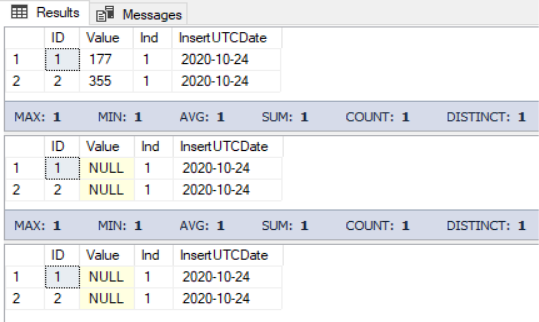
该脚本输出表变量的所有具有Ind = 1的行。然后,在事务中,所有这些行中的“值”字段都会更新。它们获得NULL值,我们再次输出它们。之后,事务将回滚,然后再次输出Ind = 1的表变量的所有行。结果表明,事务回滚不会取消对表变量所做的更改。
因此,当我们在事务的表变量中实现更改并回滚该事务时,更改将保留。这将表变量与常规表和临时表区分开。
从2019版本开始,SQL Server根据其实际执行计划存储先前进行的查询的实际参数值。如果没有RECOMPILE选项的第一个查询在执行中不是最佳选择,则将优化所有用于相同或相似查询的后续执行计划。
dbForge Studio for SQL Server中的实际查询执行计划概述
在dbForge Studio for SQL Server中,实际的查询执行计划如下所示:
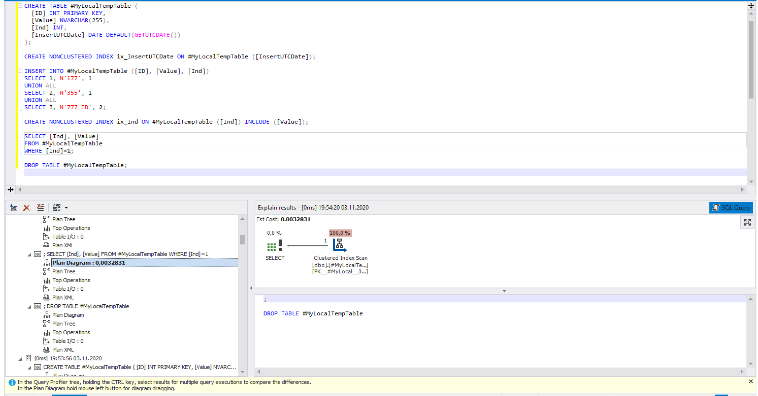
我们可以在左侧看到实际的查询执行计划。它是一个分层的树结构,每个块中包含以下元素:
- 计划图–执行计划的图形视图
- 计划树–执行计划的树状图
- 顶级操作-基于负载(包括CPU负载)的顶级操作
- 表I / O –表的输入/输出操作
- 计划XML –执行计划的XML视图
在右侧,我们将详细了解每个元素。
结论
总而言之,我们回顾了SQL Server表变量和临时表的基础知识,比较了本地临时表,全局临时表和表变量之间的差异,并以查询执行计划为例进行了举例说明。
要了解有关删除本地临时表的更多信息,请阅读我们的下一篇文章。
dbForge Studio for SQL Server,并通过30天免费试用版自行检查此功能!限时活动,现dbForge Studio SQL Sever直降3000,在线订购正版授权最低只要1710元!
标签:
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!