本篇文章介绍了UniDAC的批处理操作 。
下载UniDAC最新版本
Universal Data Access Components (UniDAC)是一款通用数据库访问组件,提供了多个数据库的直接访问,如针对Windows的Delphi, C++Builder, Lazarus (以及 Free Pascal) , Mac OS X, iOS, Android, Linux和64和32位的FreeBSD等等。我们将长期的经验集于这个小组件,提供统一的数据库连接访问(如oracle、微软SQL等等)。这意味着您可以在您的项目之间轻松地切换不同的数据库,以及创建跨数据库应用程序接口。
现代数据库处理的数据量稳步增长。在这方面,存在一个严重的问题——数据库性能。必须尽快执行插入、更新和删除操作。因此,Devart提供了几种解决方案来加速处理大量数据。因此,例如,TUniLoader支持向数据库插入大量数据。不幸的是,TUniLoader只允许插入数据——它不能用于更新和删除数据。
新版本的Devart Delphi数据访问组件引入了大数据处理的新机制-批处理操作。关键是只执行一个参数化的修改SQL查询。多个更改是由于这样一个查询的参数不是单个值,而是一个完整的值数组。这种方法极大地提高了数据操作的速度。此外,与使用TUniLoader相比,批处理操作不仅可以用于插入,还可以用于修改和删除。
让我们以包含最流行数据类型属性的BATCH_TEST表为例,更好地了解批处理操作的功能。
Batch_Test表生成脚本
For Oracle:
CREATE TABLE BATCH_TEST( ID NUMBER(9,0), F_INTEGER NUMBER(9,0), F_FLOAT NUMBER(12,7), F_STRING VARCHAR2(250), F_DATE DATE, CONSTRAINT PK_BATCH_TEST PRIMARY KEY (ID))
For MS SQL Server:
CREATE TABLE BATCH_TEST( ID INT, F_INTEGER INT, F_FLOAT FLOAT, F_STRING VARCHAR(250), F_DATE DATETIME, CONSTRAINT PK_BATCH_TEST PRIMARY KEY (ID))
For PostgreSQL:
CREATE TABLE BATCH_TEST( ID INTEGER, F_INTEGER INTEGER, F_FLOAT DOUBLE PRECISION, F_STRING VARCHAR(250), F_DATE DATE, CONSTRAINT PK_BATCH_TEST PRIMARY KEY (ID))
For InterBase:
CREATE TABLE BATCH_TEST( ID INTEGER NOT NULL PRIMARY KEY, F_INTEGER INTEGER, F_FLOAT FLOAT, F_STRING VARCHAR(250), F_DATE DATE)
For MySQL:
CREATE TABLE BATCH_TEST( ID INT, F_INTEGER INT, F_FLOAT FLOAT, F_STRING VARCHAR(250), F_DATE DATETIME, CONSTRAINT PK_BATCH_TEST PRIMARY KEY (ID))
For SQLite:
CREATE TABLE BATCH_TEST( ID INTEGER, F_INTEGER INTEGER, F_FLOAT FLOAT, F_STRING VARCHAR(250), F_DATE DATETIME, CONSTRAINT PK_BATCH_TEST PRIMARY KEY (ID))
批处理操作执行
要将记录插入到BATCH_TEST表中,我们使用以下SQL查询:
INSERT INTO BATCH_TEST VALUES (:ID, :F_INTEGER, :F_FLOAT, :F_STRING, :F_DATE)
使用简单插入操作时,查询参数值如下:


查询执行后,一条记录将插入到BATCH_TEST表中。
使用批处理操作时,查询及其参数保持不变。但是,参数值将包含在一个数组中:
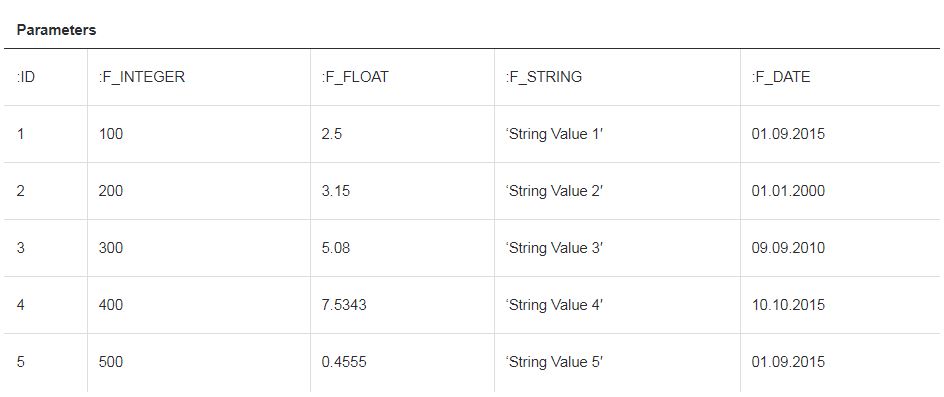
现在,在执行查询时,一次向表中插入5条记录。
如何在代码中实现批量操作/p>
批量插入操作样本
让我们尝试使用批插入操作将1000行插入到BATCH_TEST表中:
var i: Integer;begin // describe the SQL query UniQuery1.SQL.Text := 'INSERT INTO BATCH_TEST VALUES (:ID, :F_INTEGER, :F_FLOAT, :F_STRING, :F_DATE)'; // define the parameter types passed to the query : UniQuery1.Params[0].DataType := ftInteger; UniQuery1.Params[1].DataType := ftInteger; UniQuery1.Params[2].DataType := ftFloat; UniQuery1.Params[3].DataType := ftString; UniQuery1.Params[4].DataType := ftDateTime; // specify the array dimension: UniQuery1.Params.ValueCount := 1000; // populate the array with parameter values: for i := 0 to UniQuery1.Params.ValueCount - 1 do begin UniQuery1.Params[0][i].AsInteger := i + 1; UniQuery1.Params[1][i].AsInteger := i + 2000 + 1; UniQuery1.Params[2][i].AsFloat := (i + 1) / 12; UniQuery1.Params[3][i].AsString := 'Values ' + IntToStr(i + 1); UniQuery1.Params[4][i].AsDateTime := Now; end; // insert 1000 rows into the BATCH_TEST table UniQuery1.Execute(1000);end;
此命令将使用准备好的参数值数组,通过一个SQL查询向表中插入1000行。还可以将另一个参数–偏移(默认为0)–传递给方法。Offset参数指向数组元素,批处理操作从该元素开始。
我们可以通过两种方式将1000条记录插入到BATCH_TEST表中。
每次1000行:
UniQuery1.Execute(1000);
2×500行:
// insert first 500 rowsUniQuery1.Execute(500, 0);// insert next 500 rowsUniQuery1.Execute(500, 500);
500行,然后是300行,最后是200行:
// insert 500 rowsUniQuery1.Execute(500, 0);// insert next 300 rows starting from 500UniQuery1.Execute(300, 500);// insert next 200 rows starting from 800UniQuery1.Execute(200, 800);
批量更新操作示例
通过批处理操作,我们可以修改BATCH_TEST表中的所有1000行,这很简单:
var i: Integer;begin // describe the SQL query UniQuery1.SQL.Text := 'UPDATE BATCH_TEST SET F_INTEGER=:F_INTEGER, F_FLOAT=:F_FLOAT, F_STRING=:F_STRING, F_DATE=:F_DATE WHERE ID=:OLDID'; // define parameter types passed to the query: UniQuery1.Params[0].DataType := ftInteger; UniQuery1.Params[1].DataType := ftFloat; UniQuery1.Params[2].DataType := ftString; UniQuery1.Params[3].DataType := ftDateTime; UniQuery1.Params[4].DataType := ftInteger; // specify the array dimension: UniQuery1.Params.ValueCount := 1000; // populate the array with parameter values: for i := 0 to 1000 - 1 do begin UniQuery1.Params[0][i].AsInteger := i - 2000 + 1; UniQuery1.Params[1][i].AsFloat := (i + 1) / 100; UniQuery1.Params[2][i].AsString := 'New Values ' + IntToStr(i + 1); UniQuery1.Params[3][i].AsDateTime := Now; UniQuery1.Params[4][i].AsInteger := i + 1; end; // update 1000 rows in the BATCH_TEST table UniQuery1.Execute(1000);end;
批量删除操作样本
从BATCH_TEST表中删除1000行的操作如下:
var i: Integer;begin // describe the SQL query UniQuery1.SQL.Text := 'DELETE FROM BATCH_TEST WHERE ID=:ID'; // define parameter types passed to the query: UniQuery1.Params[0].DataType := ftInteger; // specify the array dimension UniQuery1.Params.ValueCount := 1000; // populate the arrays with parameter values for i := 0 to 1000 - 1 do UniQuery1.Params[0][i].AsInteger := i + 1; // delete 1000 rows from the BATCH_TEST table UniQuery1.Execute(1000);end;
性能比较
BATCH_TEST表示例允许使用数据库和批处理操作分析正常操作的执行速度:
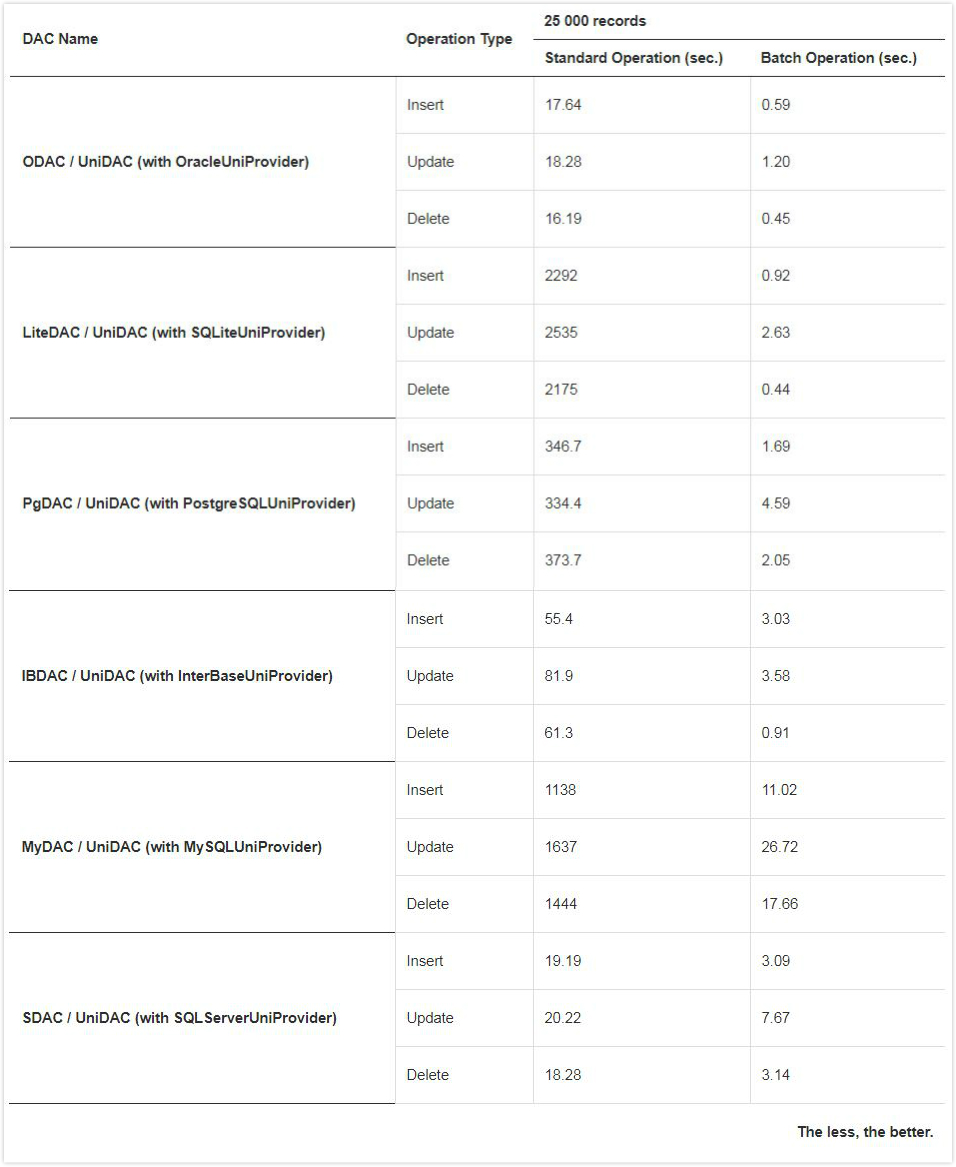
需要注意的是,在不同的数据库服务器上修改同一个表时,检索到的结果可能会有所不同。这是由于操作执行速度可能因特定服务器的设置、其当前工作负载、吞吐量、 络连接等而不同。
在批处理操作中访问参数时不应该做
在填充数组和插入记录时,我们通过索引访问查询参数。更明显的是,按名称访问参数:
for i := 0 to 9999 do begin UniQuery1.Params.ParamByName('ID')[i].AsInteger := i + 1; UniQuery1.Params.ParamByName('F_INTEGER')[i].AsInteger := i + 2000 + 1; UniQuery1.Params.ParamByName('F_FLOAT')[i].AsFloat := (i + 1) / 12; UniQuery1.Params.ParamByName('F_STRING')[i].AsString := 'Values ' + IntToStr(i + 1); UniQuery1.Params.ParamByName('F_DATE')[i].AsDateTime := Now;end;
但是,参数数组的填充速度会变慢,因为在每个循环迭代中,必须根据每个参数的名称定义其序 。如果循环执行10000次,性能损失可能会变得相当严重。
购买UniDAC正版授权,请点击“咨询在线客服”哟!

标签:数据库服务器
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!