dbForge Studio for SQL Server为有效的探索、分析SQL Server数据库中的大型数据集提供全面的解决方案,并设计各种 表以帮助作出合理的决策。(为庆祝双节来袭现dbForge Studio for SQL Server正版授权低至 1710元!包含多种授权方式供你选择。)
dbForge Studio for SQL Server最新试用版
之前,我们讨论了为招聘服务创建SQL Server数据库的过程。
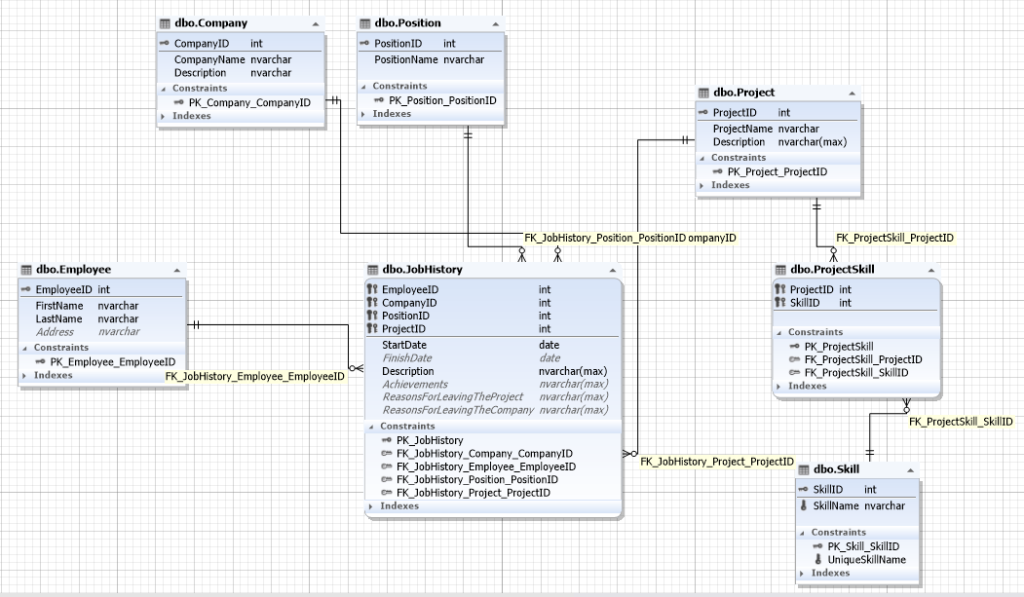

图1。招聘服务的数据库架构
如上所示,数据库包含以下实体:
- 雇员
- 公司
- 位置
- 项目
- 技能
但是,在系列文章中,我们以某种方式忽略了单元测试的关键方面。因此,现在,我建议我们仔细研究此方法,并通过为基于某些技能的员工搜索实现SearchEmployee存储过程来举例说明。为了确保数据完整性,我们应该在Skill表上添加唯一约束,如下所示:
ALTER TABLE [dbo].[Skill] ADD CONSTRAINT UniqueSkillName UNIQUE (SkillName);
但是,在执行此操作之前,请使用以下查询确保SkillName字段中的数据不包含任何重复的条目:
SELECT[SkillName]FROM [JobEmpl].[dbo].[Skill]GROUP BY [SkillName]HAVING COUNT(*) > 1;
假设您有重复的条目,则需要将所有记录标准化为SkillName字段相对于彼此的唯一值。
这一步骤中我们在技能名称中创建了唯一性约束。现在,是时候实现SearchEmployee存储过程了,如下所示:
CREATE PROCEDURE [dbo].[SearchEmployee]@SkillList NVARCHAR(MAX),@CountNotSkill INT = 1ASBEGINSET NOCOUNT ON;DECLARE @count_skills INT;SELECT[value] INTO #tbl_skill_tmpFROM STRING_SPLIT(@SkillList, N';');SELECTs.[SkillID] ,s.[SkillName] INTO #tbl_skillFROM #tbl_skill_tmp AS ttINNER JOIN [dbo].[Skill] AS sON s.[SkillName] = tt.[value];SET @count_skills = (SELECTCOUNT(*)FROM #tbl_skill);SELECTjh.* ,p.[ProjectName] ,p.[Description] AS [ProjectDescription] ,ts.* INTO #tbl_res0FROM [dbo].[JobHistory] AS jhINNER JOIN [dbo].[Project] AS pON p.[ProjectID] = jh.[ProjectID]INNER JOIN [dbo].[ProjectSkill] AS psON ps.[ProjectID] = p.[ProjectID]INNER JOIN #tbl_skill AS tsON ps.[SkillID] = ts.[SkillID];SELECT[EmployeeID] ,[SkillID] ,MIN([SkillName]) AS [SkillName] ,SUM(DATEDIFF(DAY, [StartDate], COALESCE([FinishDate], GETDATE()))) AS [Days] ,MIN([StartDate]) AS [StartDate] ,MAX(COALESCE([FinishDate], GETDATE())) AS [FinishDate] INTO #tbl_resFROM #tbl_res0GROUP BY [SkillID],[EmployeeID];SELECTemp.[EmployeeID] ,emp.[LastName] ,emp.[FirstName] ,r.[SkillID] ,r.[SkillName] ,r.[StartDate] ,r.[FinishDate] ,r.[Days] / 365 AS [Years] ,(r.[Days] - (r.[Days] / 365) * 365) / 30 AS [Months] ,r.[Days] - (r.[Days] / 365) * 365 - ((r.[Days] - (r.[Days] / 365) * 365) / 30) * 30 AS [Days] INTO #tbl_res2FROM #tbl_res AS rINNER JOIN [dbo].[Employee] AS empON emp.[EmployeeID] = r.[EmployeeID];SELECT[EmployeeID] ,[LastName] ,[FirstName] INTO #tbl_emplFROM #tbl_res2;SELECTts.[SkillID] ,te.[EmployeeID] ,ts.[SkillName] ,te.[LastName] ,te.[FirstName] INTO #tbl_skill_emplFROM #tbl_skill AS tsCROSS JOIN #tbl_empl AS te;SELECTtse.[EmployeeID] ,tse.[LastName] ,tse.[FirstName] ,tse.[SkillID] ,tse.[SkillName] ,tr2.[StartDate] ,tr2.[FinishDate] ,tr2.[Years] ,tr2.[Months] ,tr2.[Days] INTO #tbl_res3FROM #tbl_skill_empl AS tseLEFT OUTER JOIN #tbl_res2 AS tr2ON tse.[SkillID] = tr2.[SkillID]AND tse.[EmployeeID] = tr2.[EmployeeID];SELECT[EmployeeID] INTO #tbl_empl_resFROM (SELECT[EmployeeID] ,[SkillID]FROM #tbl_res3WHERE [Months] >= 6 OR [Years]>=1GROUP BY [EmployeeID],[SkillID]) AS tGROUP BY [EmployeeID]HAVING COUNT(*) >= @count_skills - @CountNotSkill;SELECTtr2.[EmployeeID],tr2.[LastName],tr2.[FirstName],tr2.[SkillID],tr2.[SkillName],tr2.[StartDate],tr2.[FinishDate],tr2.[Years],tr2.[Months],tr2.[Days]FROM #tbl_empl_res AS terINNER JOIN #tbl_res2 AS tr2ON ter.[EmployeeID] = tr2.[EmployeeID];SELECTtr2.[EmployeeID],tr2.[LastName], tr2.[FirstName], tr0.[CompanyID],(SELECT TOP(1) com.[CompanyName] FROM [dbo].[Company] AS com WHERE com.[CompanyID]=tr0.[CompanyID]) AS [CompanyName],tr0.[PositionID],(SELECT TOP(1) p.[PositionName] FROM [dbo].[Position] AS p WHERE p.[PositionID]=tr0.[PositionID]) AS [PositionName],tr0.[ProjectID],tr0.[StartDate],tr0.[FinishDate],tr0.[Description],tr0.[ProjectName],tr0.[ProjectDescription],tr0.[SkillID],tr0.[SkillName],tr0.[Achievements],tr0.[ReasonsForLeavingTheProject],tr0.[ReasonsForLeavingTheCompany]FROM #tbl_res2 AS tr2INNER JOIN #tbl_res0 AS tr0ON tr0.[EmployeeID] = tr2.[EmployeeID]INNER JOIN #tbl_skill AS tsON ts.[SkillID] = tr0.[SkillID];DROP TABLE #tbl_skill_tmp;DROP TABLE #tbl_skill;DROP TABLE #tbl_res;DROP TABLE #tbl_res2;DROP TABLE #tbl_empl;DROP TABLE #tbl_skill_empl;DROP TABLE #tbl_res3;DROP TABLE #tbl_empl_res;DROP TABLE #tbl_res0;ENDGO
为什么不更详细地检查SearchEmployee存储过程的工作/p>
对于初学者,它具有两个输入参数:
- @SkillList是技能列表,以分 分隔。
- @CountNotSkill指示可以缺少的技能数(默认为1)。
现在,让我们转到SearchEmployee存储过程的主体:
- 首先,我们定义变量@count_skills,该变量用于对数据库中发现的与输入参数@SkillList中 告的数字相对应的技能数进行计数。
- 接下来,使用内置函数STRING_SPLIT将@SkillList字符串转换为临时表#tbl_skill_tmp 。
- 然后,从“skill”表中找到所有合适的技能,并将其放置在名为#tbl_skill_tmp的新临时表中。
- 之后,@ count技能将根据参数1进行计数。
- 然后,根据设置的技能,收集有关项目(项目表)和工作历史(作业历史表)的必要信息;结果进入一个名为#tbl_skill_tmp的临时表。
- 接下来,获取在参数中获得的信息。根据技能和雇员的标识符对图5进行分组,结果进入临时表#tbl_res。
- 获得了在标准杆中获得的信息。将6与Employee表组合在一起以获取雇员的详细信息(名字和姓氏),然后结果进入临时表#tbl_res2。该查询还计算了在数年,数月和数天内每种技能的应用时间,以使后续分析更加方便。
- 此后,从参数7中的结果中检索有关雇员的信息,并将最终结果放入临时表#tbl_empl中。
- 然后,制作表#tbl_skill和#tbl_empl的笛卡尔积,并将结果放入临时表#tbl_skill_empl中。
- 接下来,创建一个名为#tbl_res3的临时表,它包含两个临时表#tbl_skill_empl和#tbl_res2的乘积,其中每个员工和技能对都具有在参数7中获得的匹配信息。
- 然后,将符合输入参数的员工标识符收集到临时表#tbl_empl_res中。在此情况下,如果该技能已使用了至少6个月,则认为该技能有效。
- 接下来,跟踪雇员及其技能的输出结果,以及使用时间(以年,月,日为单位)以及其开始和结束日期。
- 然后,您将看到有关我们感兴趣的技能的员工历史的详细摘要。
- 最后,我们删除在此存储过程中创建的所有临时表。
完成上述步骤后,我们可以提取出能够使用C#和T-SQL语言以及ASP.NET技术胜任的员工的姓名,但前提是最多只能缺少一种技能,如下所示:
EXEC [dbo].[SearchEmployee] @SkillList = N'C#;T-SQL;ASP.NET' ,@CountNotSkill = 1;
您可以在单元测试的帮助下涵盖所创建解决方案的大部分甚至全部功能。最重要的是,单元测试是DevOps基本原理的一部分,因为它们在此自动化过程中扮演着关键角色之一。本次讲解就这些,下一篇文章我们将讲解如何创建并运行存储过程 。立即下载体验吧!点击获取正版授权!
标签:
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!