Hive是基于Hadoop构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop分布式文件系统中的数据:可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能;可以将SQL语句转换为MapReduce任务运行,通过自己的SQL查询分析需要的内容,这套SQL简称Hive SQL,使不熟悉mapreduce的用户可以很方便地利用SQL语言查询、汇总和分析数据。
Hive功能
Hive是基于Hadoop构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop分布式文件系统中的数据:可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能;可以将SQL语句转换为MapReduce任务运行,通过自己的SQL查询分析需要的内容,这套SQL简称Hive SQL,使不熟悉mapreduce的用户可以很方便地利用SQL语言查询、汇总和分析数据。而mapreduce开发人员可以把自己写的mapper和reducer作为插件来支持Hive做更复杂的数据分析。它与关系型数据库的SQL略有不同,但支持了绝大多数的语句如DDL、DML以及常见的聚合函数、连接查询、条件查询。它还提供了一系列的1:具进行数据提取转化加载,用来存储、查询和分析存储在Hadoop中的大规模数据集,并支持UDF(User-Defined Function)、UDAF(User-Defnes AggregateFunction)和UDTF(User-Defined Table-Generating Function),也可以实现对map和reduce函数的定制,为数据操作提供了良好的伸缩性和可扩展性。

Hive不适合用于联机(online)上事务处理,也不提供实时查询功能。它最适合应用在基于大量不可变数据的批处理作业。Hive的特点包括:可伸缩(在Hadoop的集群上动态添加设备)、可扩展、容错、输入格式的松散耦合。
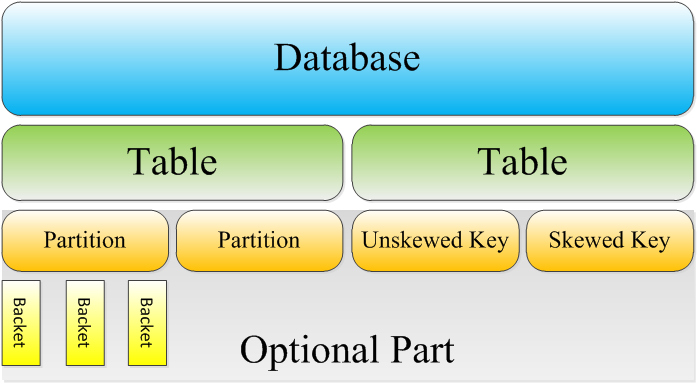
内部表
Hive的内部表与数据库中的Table在概念上是类似。每一个Table在Hive中都有一个相应的目录存储数据。删除表时,元数据与数据都会被删除。
内部表示例:
创建数据文件:test_inner_table.txt
创建表:create table test_inner_table (key string)
加载数据:LOAD DATA LOCAL INPATH ‘filepath’ INTO TABLE test_inner_table
查看数据:select * from test_inner_table; select count(*) from test_inner_table
删除表:drop table test_inner_table
外部表
外部表指向已经在HDFS中存在的数据,可以创建Partition。外部表加载数据和创建表同时完成(CREATE EXTERNAL TABLE ……LOCATION),实际数据是存储在LOCATION后面指定的 HDFS 路径中,并不会移动到数据仓库目录中。当删除一个External Table时,仅删除该链接。
外部表示例:
创建数据文件:test_external_table.txt
创建表:create external table test_external_table (key string)
加载数据:LOAD DATA INPATH ‘filepath’ INTO TABLE test_inner_table
查看数据:select * from test_external_table; /span>select count(*) from test_external_table
删除表:drop table test_external_table
分区
Partition对应于数据库中的Partition列的密集索引。在Hive中,表中的一个Partition对应于表下的一个目录,所有的Partition的数据都存储在对应的目录中。
分区表示例:
创建数据文件:test_partition_table.txt
创建表:create table test_partition_table (key string) partitioned by (dt string)
加载数据:LOAD DATA INPATH ‘filepath’ INTO TABLE test_partition_table partition (dt=‘2006’)
查看数据:select * from test_partition_table; select count(*) from test_partition_table
删除表:drop table test_partition_table
桶
Buckets是将表的指定列通过Hash算法进一步分解成不同的文件存储。它对指定列计算hash,根据hash值切分数据,目的是为了并行,每一个Bucket对应一个文件。当需要并行执行Map任务时,桶是不错的选择。
桶的示例:
创建数据文件:test_bucket_table.txt
创建表:create table test_bucket_table (key string) clustered by (key) into 20 buckets
加载数据:LOAD DATA INPATH ‘filepath’ INTO TABLE test_bucket_table
查看数据:select * from test_bucket_table; set hive.enforce.bucketing = true;
视图
视图与传统数据库的视图类似。视图是只读的,它基于的基本表,如果改变,数据增加不会影响视图的呈现;如果删除,会出现问题。如果不指定视图的列,会根据select语句后的生成。
示例:create view test_view as select * from test
倾斜表
对大数据系统来讲,数据量大并不可怕,可怕的是数据倾斜。
数据倾斜,是并行处理的数据集中,某一部分的数据显著多于其它部分,从而使得该部分的处理速度成为整个数据集的瓶颈。
在Spark中,同一个Stage的不同Partition可以并行处理,而具有依赖关系的不同Stage之间是串行处理的。换句话说,一个Stage所耗费的时间,主要由最慢的那个Task决定。由于同一个Stage内的所有Task执行相同的计算,在排除不同计算节点计算能力差异的前提下,不同Task之间耗时的差异主要由该Task所处理的数据量决定。
倾斜表是一种特殊类型的表,其中经常出现的值(重偏差)被分割成单独的文件,其余的值将转到其他文件。通过指定偏斜值,Hive会自动将它们分解为单独的文件,并在查询期间可以跳过(或包含)整个文件,从而提高性能。
创建表语法:create table <T> (schema) skewed by (keys) on (values) [STORED as DIRECTORIES];
具体例子: create table T (c1 string, c2 string) skewed by (c1) on (‘x1’)
存储过程
存储过程是在数据库系统中为了完成特定功能的SQL 语句集,经过第一次编译后再次调用不需要再次编译,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。
CREATE PROCEDURE proc_test
BEGIN
Drop table order_base.O_ORDER_DETAIL;
create table order_base.O_ORDER_DETAIL (customernumber string, invoicenumber string, invoicedate string, ordernumberstring, itemnumberid string, ordertypeen string, ordertypesc string, salesrepid string, warehouse string, lineamount string, linecostamount string, invoicequantity string, lineno string) clustered by (ordertypeen) into 2 buckets stored as orc TBLPROPERTIES (‘transactional’=’true’);
TRUNCATE TABLE order_base.O_ORDER_DETAIL;
INSERT INTO order_base.O_ORDER_DETAIL select * from ORDER_DETAIL;
update order_base.O_ORDER_DETAIL set itemnumberid=replace(itemnumberid,’*’,”);
END;
CALL proc_test

执行存储过程
hplsql -f /home/hadoop/proc_test.sql
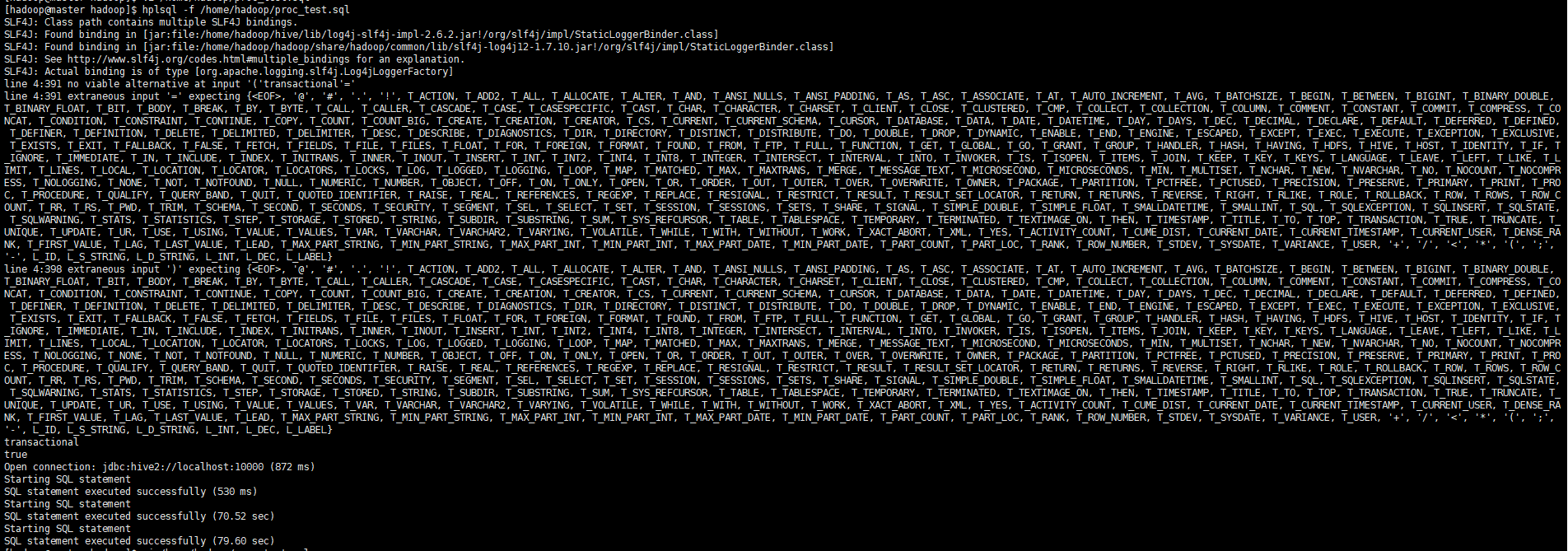
查询结果
select * from order_base.O_ORDER_DETAIL where ordernumber=8800840;

客户端接口
CLI:command line interface,命令行接口。

Thrift客户端: Hive架构的许多客户端接口是建立在thrift客户端之上,包括JDBC和ODBC接口。
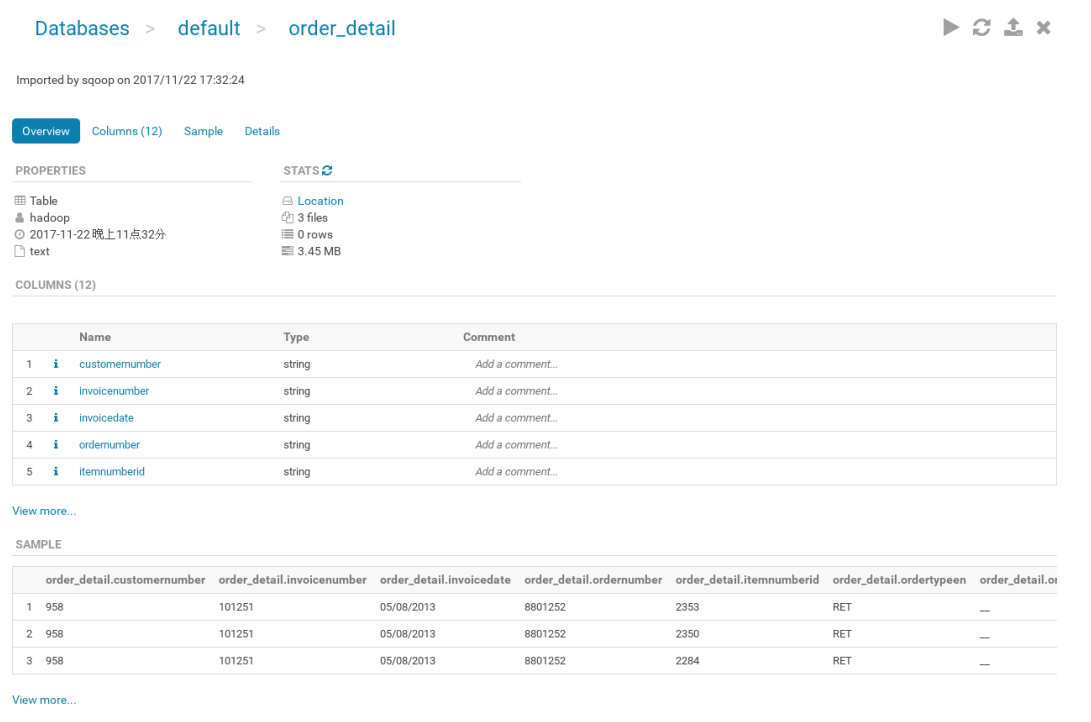
WEBGUI:Hive客户端提供了一种通过 页的方式访问Hive所提供的服务。这个接口对应Hive的HWI组件(Hive Web Interface),生产环境可用Hue组件代替,下图为Hue界面。
关于数仓建模大师
数仓建模大师能够快速、高效地帮助客户搭建数据仓库供企业决策分析之用。满足数据需求效率、数据质量、扩展性、面向主题等特点。
跨行业数据挖掘流程
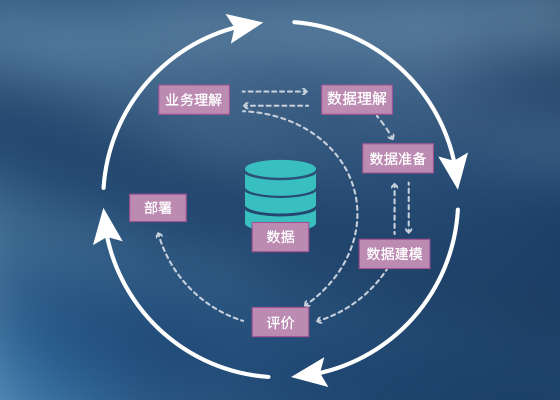
基于企业的业务目标,进行数据理解、数据准备、数据建模,最后进行评价和部署,真正实现数据驱动业务决策。更多详情,请联系我们。
标签:
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!