【机器学习】《机器学习实战》读书笔记及代码 总目录
- https://blog.csdn.net/TeFuirnever/article/details/99701256
GitHub代码地址:
- https://github.com/TeFuirnever/Machine-Learning-in-Action
——————————————————————————————————————————————————————
目录
-
- 本章内容
-
- 1、k-近邻算法概述
- 2、使用k-近邻算法改进约会 站的配对效果
- 3、Sklearn构建k-近邻分类器用于手写数字识别
- 4、sklearn.neighbors.KNeighborsClassifier
- 5、总结
- 参考文章
本章内容
- k-近邻分类算法
- 使用Matplotlib创建扩散图
- 归一化数值
这一节早在【CS231n】斯坦福大学李飞飞视觉识别课程笔记中就讲过了,感兴趣的同学可以去学一学这个课程,同时还有python的相关课程【Python – 100天从新手到大师】,但是没有具体的实现代码,所以今天来搞一下。
1、k-近邻算法概述
简单地说,k-近邻算法采用测量不同特征值之间的距离方法进行分类。
k-近邻算法
优点:精度高、对异常值不敏感、无数据输入假定。
缺点:计算复杂度高、空间复杂度高。
适用数据范围:数值型和标称型。
k-近邻算法(kNN),它的工作原理是:存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
一般来说,只选择样本数据集中前k个最相似的数据,这就是 k-近邻 算法中k的出处,通常k是不大于20的整数。
书上举了一个简单但是经典的例子——电影分类,有人曾经统计过很多电影的打斗镜头和接吻镜头,图2-1显示了6部电影的打斗和接吻镜头数。
一共有6组数据,每组数据有两个已知的属性或者特征值。上面的group矩阵每行包含一个不同的数据,我们可以把它想象为某个日志文件中不同的测量点或者入口。由于人类大脑的限制,通常只能可视化处理三维以下的事务。因此为了简单地实现数据可视化,对于每个数据点通常只使用两个特征。向量labels包含了每个数据点的标签信息,labels包含的元素个数等于group矩阵行数。
- 实施kNN 算法
对未知类别属性的数据集中的每个点依次执行以下操作:
(1) 计算已知类别数据集中的点与当前点之间的距离;
(2) 按照距离递增次序排序;
(3) 选取与当前点距离最小的k个点;
(4) 确定前k个点所在类别的出现频率;
(5) 返回前k个点出现频率最高的类别作为当前点的预测分类。
根据两点距离公式(欧氏距离公式),计算两个向量点xA和xB之间的距离。
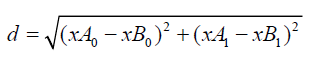

按照步骤,接下来对数据按照从小到大的次序排序。选择距离最小的前k个点,并返回分类结果。
完整代码:
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!