最近项目原因需要我完成一个在树莓派上的离线语音识别,忙活了近一周,起初用了开源的PocketSphinx,但是不得不说,识别率低的惊人,甚至可以说有些字词根本没法识别,除非你自己制作声学模型,不然这玩意儿就是个摆设。
百度目前对像树莓派这种设备只支持在线识别,不能用。
最后,万幸,科大讯飞提供了离线版本,而且还免费,还支持树莓派!
接下来,根据我的摸索,教大家如何在树莓派上搭建语音识别模块。
首先,前往讯飞开放平台下载SDK,平台选择Linux。你需要注册相关信息,最后你所下载的SDK中会自动填入你的key。
因为科大讯飞官方在新版本SDK移除了树莓派的支持,我把以前的版本上传了,供大家使用:
http://download.csdn.net/detail/yanghuan313/9616763
解压后如图
保存退出后,继续,sudo vim Makefile,修改下面划红线的位置为如图:
接着,在Linux_voice_1.109/bin目录下会生成一个可执行文件:
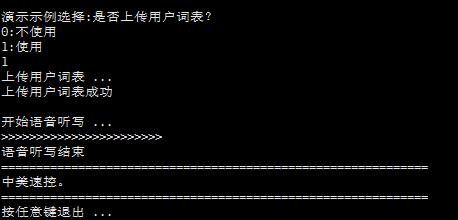
这里选0会直接识别,识别的语音为官方所给的测试语音文件,保存在当前目录的wav文件夹下,识别结果为中美数控。选1则会使用用户词表,文件为当前目录下的userwords.txt,识别结果为中美速控,原因大家自己思考。

好了,现在识别解决了,我们来解决录音的问题
我试过很多在linux下的录音软件,不是不能设置详细的参数,就是无法控制录音时间。比如sox,这个软件很好,但是我看了帮助文档发现,要停止录音必须手动Ctrl+C!
不过问题还是被我解决了:
sudo apt-get install alsa-oss
安装完以后,执行:
arecord -d 3 -r 16000 -c 1 -t wav -f S16_LE test.wav
因为科大讯飞要求单音轨,16000HZ,16bit的采样,支持wav或者pcm
录音结束后,文件保存在当前目录,将它移动到bin/wav/下,并且修改文件名替换掉以前的文件,或者你直接可以在sample/iat_sample/下修改C文件源代码。
我们再次执行bin/iat_sample,成功识别。
在这里我只是讲述了如何实现语音识别的功能,更多的改善大家可以自己解决。
有错误的地方还望大家指正。
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!