python数据分析和数据可视化总结
- 数据分析
-
- 数据和信息
-
- 什么是数据分析
- 数据分析的目的
- 数据分析过程
-
- Numpy和Pandas
-
- 如何利用Pandas读取文件
- 如何利用Pandas写入数据到新文件
- 使用jieba提炼关键字词
-
- jieba分词有三种模式
- textrank算法
- 数据可视化
-
- matplotlib的使用
- 参考文献
数据分析
数据和信息
数据和信息,两个词词义很接近,但其实并不能等同。
数据是信息的载体,是对客观事物的符 表示,指能输入到计算机中并能被计算机接受处理的各种符 集合的统称。数据实际上不同于信息,至少在形式上不一样。
什么是数据分析
信息实际上是对数据集进行处理,从中提炼出可用于其他场合的结论,是对数据进行处理后的得到的结果。从原始数据中抽取信息的过程叫做数据分析。
常见的数据存储格式有:XML, JSON, XLS,CSV
数据分析常用到的统计技术有:贝叶斯方法、回归、聚类
数据分析领域最先进的工具之一是机器学习方法
数据分析的目的
抽取不易推断的信息,而一旦了解这些信息,就能够对产生数据的系统的运行机制进行研究,从而对系统可能的响应和演变做出预测。数据分析最初用于数据保护,现在已经发展为数据建模的方法论。
数据分析过程
问题定义、数据抽取、数据清洗、数据转换、数据探索、预测模型、模型评估/测试、结果可视化和阐释、解决方案部署。
运行结果如下:
D:anacondapython.exe “D:/Python workSpace/readFile.py”
[‘贵阳’, ‘呼和浩特’, ‘兰州’, ‘沈阳’, ‘包头’, ‘南京’, ‘成都’, ‘贵州省’, ‘黔东南’, ‘深圳’, ‘南宁’, ‘银川’, ‘上海’, ‘呼伦贝尔’, ‘北京’, ‘广州’, ‘甘肃省’, ‘遵义’, ‘珠海’, ‘佛山’, ‘中山’, ‘惠州’, ‘河源’, ‘江门’, ‘广东省’, ‘汕头’, ‘无锡’, ‘湛江’, ‘武汉’, ‘长沙’, ‘清远’, ‘杭州’, ‘肇庆’, ‘东莞’, ‘云浮’, ‘厦门’, ‘海口’, ‘揭阳’, ‘福州’, ‘青岛’, ‘济南’, ‘哈尔滨’, ‘淄博’, ‘漳州’, ‘山东省’, ‘长春’, ‘郑州’, ‘宁波’, ‘合肥’, ‘天津’, ‘浙江省’, ‘大连’, ‘芜湖’, ‘泉州’, ‘六安’, ‘南昌’, ‘黑龙江省’, ‘铜陵’, ‘三门峡’, ‘金华’, ‘烟台’, ‘上饶’, ‘萍乡’, ‘洛阳’, ‘马鞍山’, ‘桂林’, ‘宁德’, ‘柳州’, ‘贺州’, ‘景德镇’, ‘滁州’, ‘贵港’, ‘威海’, ‘鹰潭’, ‘潍坊’, ‘赣州’, ‘济宁’, ‘广西’, ‘三亚’, ‘昆明’, ‘枣庄’, ‘苏州’, ‘西安’, ‘湖州’, ‘南阳’, ‘台州’, ‘嘉兴’, ‘湖南省’, ‘安徽省’, ‘湘潭’, ‘龙岩’, ‘德州’, ‘岳阳’, ‘泰安’, ‘吉安’, ‘东营’, ‘廊坊’, ‘九江’, ‘淮北’, ‘宿州’, ‘临沂’, ‘莱芜’, ‘日照’, ‘徐州’, ‘抚州’, ‘常州’, ‘新余’, ‘义乌’, ‘福建省’, ‘株洲’, ‘南平’, ‘怀化’, ‘莆田’, ‘重庆’, ‘南通’, ‘襄阳’, ‘黄石’, ‘昆山’, ‘十堰’, ‘江苏省’, ‘鄂州’, ‘燕郊开发区’, ‘雄安新区’, ‘咸宁’, ‘邯郸’, ‘太仓’, ‘常熟’, ‘唐山’, ‘绵阳’, ‘湖北省’, ‘张家港’, ‘荆门’, ‘温州’, ‘淮安’, ‘石家庄’, ‘茂名’, ‘泰州’, ‘太原’, ‘梅州’, ‘宜昌’, ‘邢台’, ‘舟山’, ‘镇江’, ‘海宁’, ‘乌鲁木齐’]
145
Process finished with exit code 0
如何利用Pandas写入数据到新文件
那么,如果只是将数据整合后的结果在控制台输出,会对后续可视化操作带来不便,最好是可以将这新数据整合到一个新文件中。那么怎么写入数据到新的excel文件呢面我们统计一下各个地区(市)及出现的频数,并将其数据整合到新的表格文件testClassifyArea.xls中。
运行结果如下:
D:anacondapython.exe “D:/Python workSpace/classifyArea.py”
[‘福州’, ‘济南’, ‘长春’, ‘哈尔滨’, ‘青岛’, ‘武汉’, ‘烟台’, ‘南京’, ‘潍坊’, ‘沈阳’, ‘北京’, ‘上海’, ‘泉州’, ‘威海’, ‘赣州’, ‘宁波’, ‘厦门’, ‘日照’, ‘天津’, ‘辽阳’, ‘重庆’, ‘三明’, ‘无锡’, ‘大连’, ‘海口’, ‘广州’, ‘东莞’, ‘德州’, ‘莆田’, ‘珠海’, ‘龙岩’, ‘郑州’, ‘合肥’, ‘长沙’, ‘昆明’, ‘苏州’, ‘菏泽’, ‘义乌’, ‘深圳’, ‘广西’, ‘南宁’, ‘南昌’, ‘铜陵’, ‘邵阳’, ‘三门峡’, ‘柳州’, ‘淄博’, ‘芜湖’, ‘佛山’, ‘西安’, ‘漳州’, ‘滁州’, ‘杭州’, ‘池州’, ‘石家庄’, ‘株洲’, ‘临沂’, ‘上饶’, ‘绍兴’, ‘白城’, ‘松原’, ‘六安’, ‘开封’, ‘洛阳’, ‘襄阳’, ‘荆州’, ‘宣城’, ‘南通’, ‘廊坊’, ‘桂林’, ‘抚州’, ‘保定’, ‘潜江’, ‘贵港’, ‘宁德’, ‘宜春’, ‘滨州’, ‘梧州’, ‘北海’, ‘济宁’, ‘东营’, ‘马鞍山’, ‘泰安’, ‘唐山’, ‘宜昌’, ‘台州’, ‘荆门’, ‘黄冈’, ‘九江’, ‘成都’, ‘温州’, ‘贺州’, ‘海宁’, ‘乐山’, ‘郴州’, ‘南阳’, ‘邯郸’, ‘秦皇岛’, ‘孝感’, ‘安阳’, ‘宝鸡’, ‘南充’, ‘靖江’, ‘常德’, ‘鹰潭’, ‘玉林’, ‘邢台’, ‘常州’, ‘丽水’, ‘商丘’, ‘吉安’, ‘景德镇’, ‘昆山’, ‘嘉兴’, ‘贵阳’, ‘衡阳’, ‘益阳’, ‘十堰’, ‘绵阳’, ‘徐州’, ‘银川’, ‘丹阳’, ‘许昌’, ‘张家口’, ‘燕郊开发区’, ‘舟山’, ‘新乡’, ‘阜阳’, ‘驻马店’, ‘黄石’, ‘呼和浩特’, ‘汉中’, ‘泰州’, ‘永州’, ‘蚌埠’, ‘湘潭’, ‘淮南’, ‘聊城’, ‘新余’, ‘安庆’, ‘沧州’, ‘怀化’, ‘信阳’, ‘湘西’, ‘咸宁’, ‘乌鲁木齐’, ‘衡水’, ‘淮北’, ‘周口’, ‘盐城’, ‘亳州’, ‘萍乡’, ‘枣庄’, ‘泸州’, ‘湖州’, ‘咸阳’, ‘焦作’, ‘三亚’, ‘济源’, ‘鄂州’, ‘濮阳’, ‘随州’, ‘张家港’, ‘镇江’, ‘鄂尔多斯’, ‘杨凌’, ‘连云港’, ‘拉萨’, ‘雄安新区’, ‘钦州’, ‘岳阳’, ‘莱芜’, ‘西宁’, ‘黄山’, ‘广元’, ‘鞍山’, ‘张家界’, ‘承德’, ‘平顶山’, ‘兰州’, ‘临汾’, ‘宿迁’, ‘攀枝花’, ‘眉山’, ‘遵义’, ‘金华’, ‘阳泉’]
187
[3005, 2352, 500, 379, 2064, 3556, 54, 3759, 39, 18, 266, 288, 83, 53, 36, 740, 580, 32, 730, 2, 1275, 11, 22, 53, 29, 95, 11, 12, 22, 4, 17, 1657, 2448, 3617, 57, 39, 7, 5, 110, 12, 307, 499, 9, 7, 97, 76, 25, 96, 7, 3016, 12, 15, 4215, 2, 588, 41, 27, 15, 11, 10, 2, 9, 8, 20, 49, 10, 20, 2, 28, 51, 6, 30, 3, 5, 9, 15, 5, 4, 6, 15, 6, 27, 19, 33, 38, 13, 7, 6, 7, 2763, 11, 3, 3, 1, 26, 11, 21, 12, 1, 3, 3, 1, 2, 9, 3, 6, 11, 18, 2, 4, 4, 1, 4, 16, 26, 8, 8, 4, 7, 1, 4, 2, 13, 12, 1, 2, 5, 6, 3, 16, 2, 2, 2, 4, 5, 13, 1, 6, 6, 3, 2, 14, 3, 1, 4, 7, 2, 1, 1, 2, 1, 1, 2, 14, 8, 17, 2, 2, 1, 5, 1, 1, 2, 8, 1, 1, 1, 2, 6, 2, 5, 2, 1, 1, 5, 1, 3, 2, 1, 3, 2, 1, 1, 1, 2, 1, 3]
187
Process finished with exit code 0
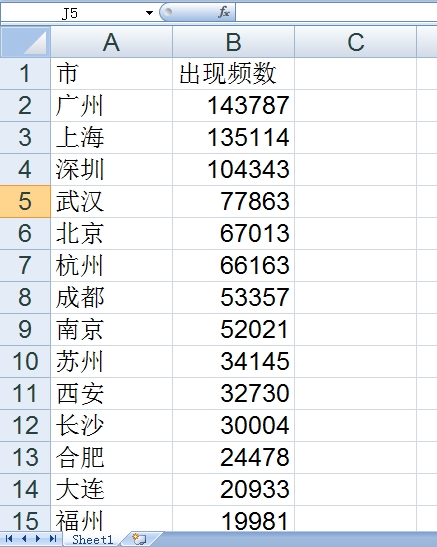
我们来看一下把所有数据都加进去最后得到的文件testClassifyArea.xls中的内容:

使用jieba提炼关键字词
jieba是优秀的中文分词第三方库,可以提供仲文分析技术,属于一种NLP(自然语言处理技术)。中文分词技术分为:规则分词、统计分词和很和分词。提供三种分词模式,可以利用一个中文词库,确定汉字之间的关联概率。汉字间概率大的组成词组,形成分词结果。除了分词,用户还可以添加自定
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!