Hadoop 详细解析
-
- 1.2 大数据面临的问题
- 1.3 大数据的特点
-
- 1)数据量大
- 2)数据时效性
- 3)数据多样性
-
- (1)数据存储类型多样性
- (2)数据分析类型多样性
- 4)数据价值
- 1.4 应用场景
-
- 1)个人推荐
- 2)风控
- 3)成本预测
- 4)气候预测
- 5)人工智能
- 1.6分布式
- 二、Hadoop
-
- 2.1 Hadoop生态系统
- 2.2 大数据分析方案
- 三、HDFS
-
- 3.1 安装(伪集群)
-
- 1)准备虚拟机
- 2)安装JDK 8JDK8
- 3)配置Java环境变量
- 4)配置主机名与IP的映射关系
- 5)关闭防火墙
-
- 6)ssh免密登陆
- 7)解压Hadoop
- 8)配置Hadoop环境变量
- 9)配置 etc/hadoop/core-site.xml
- 11)格式化namenode
- 12)启动hdfs
- 进入web界面
- 3.2 HDFS Shell 相关操作
- 3.3 Java API 操作HDFS
- (2)Windows 配置Hadoop环境
- (3)权限不足解决方案
- 1)配置 hdfs-site.xml
- (3)相关操作
- 3.4 HDFS Architecture
- 1)什么是Block块
- (1)为什么块的大小为128MB/li>
- (2)Block块的大小能否随意设置/li>
- (3)HDFS为什么不适合存储小文件
- 2)Rack Awareness 机架感知
- 3)NameNode 和 SecondaryNameNode 的 关系 (重点)
- 4)检查点
- 5)Safemode
- 6)DataNode工作机制
一。概述
## 1.1 大数据概念
大数据是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力来适应海量、高增长率和多样化的信息资产。
1.2 大数据面临的问题
:单机存储有限,需要使用集群(多台机器)存储数据;硬件上必须有足够的存储容量,软件上有对应的容灾机制。
:单机算力有限,也需要使用集群进行计算(需要在合理的时间内将数据变废为宝)
1.3 大数据的特点
4V Volume 数据量大 Velocity 时效性 Variety 多样性 Value 价值大
1)数据量大
B-KB-MB-GB-TB-PB-EB-ZB…
各种个人云存储解决方案:百度 盘、腾讯微云、115、lanzou、诚通、OneDriver、GoogleDriver 等
大数据产生于21世纪的互联 时代,日益进步的科技和日益增长的物质文化需求,导致了数据的大爆炸;
淘宝、支付宝、微信、QQ、抖音这些App是目前国内顶尖的流量,使用人数及其的庞大,每天可以产生极多的数据量。
2)数据时效性
双十一、618
大数据是在短时间内迅速产生(产生的时效性非常高),分析的时效性就必须因场景而异,需要在合理的时间内分析出有价值的数据。
3)数据多样性
(1)数据存储类型多样性
结构化的数据:表格、文本、SQL等
非结构化数据:视频、音频、图片
(2)数据分析类型多样性
地理位置:来自北京、中国、上海
设备信息:来自PC、手机、平板、手表、手环、眼镜
个人喜好:美女、面膜、ctrl、 数码、篮球、足球
交 络:A可能认识B 、C ,B就可能认识C
电话 码:110,11086
络身份证:设备MAC+电话+IP+地区
4)数据价值
警察叔叔:只关注的是否哪里违规
AI研究:犯罪预测、下棋、无人驾驶
所以在海量数据中有用的数据最为关键、这是分析数据的第一步,也就是对数据进行降噪处理(数据清洗|数据预处理)
1.4 应用场景
1)个人推荐
根据用户喜好,推荐相关资源
千人一面、千人千面、一人千面
2)风控
大数据实时流处理,根据用户行为模型进行支撑,判断该行为是否正常
3)成本预测
4)气候预测
5)人工智能
1.6分布式
为了解决大数据存储和计算的问题,需要使用一定数量的机器,硬件设施必须足够,那软件解决方案怎么办/p>
如何使用软件去解决存储和分析的问题/p>
二、Hadoop
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EB9OwHCR-1573560679737)(assets/622762d0f703918f3c528de35c3d269759eec41c.jpg)]
Hadoop由 Apache Software Foundation 公司于 2005 年秋天作为Lucene的子项目Nutch的一部分正式引入。它受到最先由 Google Lab 开发的 Map/Reduce 和 Google File System(GFS) 的启发。
2006 年 3 月份,Map/Reduce 和 Nutch Distributed File System (NDFS) 分别被纳入称为 Hadoop 的项目中。
Hadoop 是最受欢迎的在 Internet 上对搜索关键字进行内容分类的工具,但它也可以解决许多要求极大伸缩性的问题。例如,如果您要 grep 一个 10TB 的巨型文件,会出现什么情况传统的系统上,这将需要很长的时间。但是 Hadoop 在设计时就考虑到这些问题,采用并行执行机制,因此能大大提高效率。
:Hadoop Distributed File System 作为Hadoop 生态体系中数据的存储的软件解决方案
:Hadoop中分布式计算框架(只需要实现少量的代码,就可以开发一个分布式的应用程序),对海量数据并行分析和计算
3.3 Java API 操作HDFS
(1) 依赖
(2)Windows 配置Hadoop环境
- 解压hadoop到指定的目录
- 拷贝hadoop.dll和winutils.exe到hadoop/bin 目录下
- 配置Hadoop环境变量
- 配置主机名和IP的映射关系
(3)权限不足解决方案
org.apache.hadoop.security.AccessControlException: Permission denied: user=Administrator, access=WRITE, inode=”/baizhi”:root:supergroup:drwxr-xr-x
1)配置 hdfs-site.xml
3.4 HDFS Architecture
HDFS为主从架构,HDFS中有一个主的NameNode,管理系统命名空间和管理客户端对文件的访问,其中还有DataNode负责和NameNode进行协调工作,DataNode负责数据的存储,在存储数据(文件)的过程中一个文件会被分成一个块或者多个块,在NameNode中存储了一些数据(存储的数据是块到DataNode的映射关系),datanode还根据NameNode的指令创建删除复制块。
(1)为什么块的大小为128MB/h2>
在Hadoop1.x 块大小默认为64MB,在Hadoop2.x 默认为128MB
工业限制:一般来说机械硬盘的读取速度100MB左右
软件优化:通常认为最佳状态为寻址时间为传输时间的100分之一
(2)Block块的大小能否随意设置/h2>
不能,如果BlockSize过大,可能导致多余存储空间浪费,导致存取时间过长 如果BlockSize过小,会导致寻址时间过长,同样造成效率低下。
(3)HDFS为什么不适合存储小文件
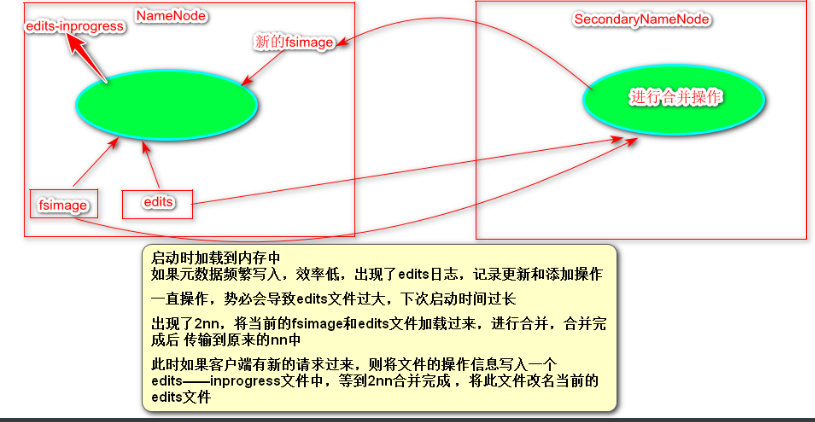
3)NameNode 和 SecondaryNameNode 的 关系 (重点)
fsimage文件:元数据信息的备份,会被加载到内存中
edits文件:Edits文件帮助记录增加和更新操作,提高效率
namenode在启动时会加载fsimage和edits的文件,所以在第一次启动的时候需要格式化namenode
当用户上传文件的时候或者进行其他操作的时候,操作记录会写入edits文件中,这样edits和fsimage文件加起来的元数据永远是最新的。
如果此时用户一直进行操作的话,edits文件会越来越大,这就导致了在下次启动的时候启动速度过慢。
为了解决这个问题,出现了SecondaryNameNode ,将当前的NameNode的edits和fsimage文件拷贝到自己的节点上,进行合并操作,在合并完成后,将新的fsimage文件传输到原来的namenode中,此时namanode再去加载最新的fsimage。
新的问题:在SecondaryNameNode 进行拷贝操作的时候,如果有客户端读写请求过来,势必要追加相应的操作记录到edits文件中,但是此时正在进行拷贝操作,改变则代表会造成数据紊乱,怎么办办法是:会有一个新的叫做edits-inprogress的文件被创建,新的操作将写入此文件中,等待SecondaryNameNode合并完成,将edits-inprogress文件改名成为当前的edits文件。

4)检查点
namenode使用fsimage和edits文件保存元数据,2nn会定期的下载主的(Active)namenode的fsimage文件和edits 文件,并在本地进行合并。
合并的时机就称之为检查点
检查点有两种触发机制:
(1) 默认一个小时进行合并
(2) 操作数量达到100W次进行合并
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!