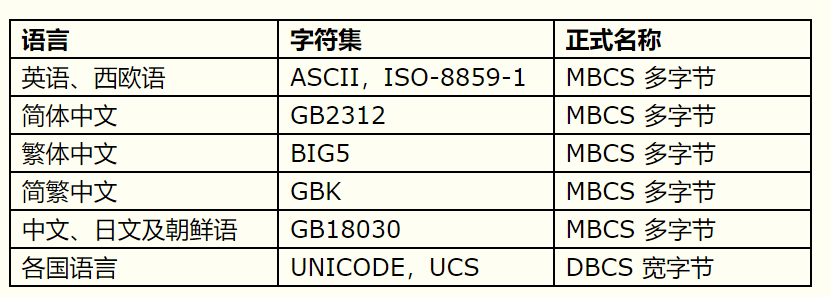
在软件的编码和实现中,我们可能会碰到个 一个比较头疼的问题--编码,不同字符间的编码和解码,你确定了解各种字符的编码吗个朋友问到了我这 个问题,我虽然能回答一两个出来,但是感觉已经有点模糊,混乱了,在 上搜了搜,在书上翻了翻,总结一下吧。首先按照字符编码的历程来看:
1. ASCII
我们需要了解的最早编码是ASCII码。它用7个二进制位来表示,由于那个时期生产的大多数计算机使用8位大小的字节,因此用户不仅可以存放所有 可能的ASCII字符,而且有整整一位空余下来。如果你技艺高超,可以将该位用做自己离奇的目的:WordStar中那个发暗的灯泡实际上设置这个高位, 以指示一个单词中的最后一个字母,同时这也宣示了WordStar只能用于英语文本。
由于字节有多达8位的空间,因此许多人在想:“呀!我们 可以把128255之间的编码用做个人的应用目的。”问题在于,同时产生这种想法的人相当多,而且在128255之间的各个位置上应该存放什么这一问 题上,真是仁者见仁智者见智。事实上,只要人们开始在美国以外的地方购买计算机,那么各种各样的不同OEM字符集都会进入规划设计行列,并且各人都会根据 自己的需要使用高位的128个字符。如此一来,甚至在同语种的文档之间就不容易实现互换。 ASCII可被扩展,最优秀的扩展方案是ISO 8859-1,通常称之为Latin-1。Latin-1包括了足够的附加字符集来写基本的西欧语言。
最后,这个人人参与的OEM终于以ANSI标准的形式形成文件。在ANSI标准中,每个人都认同如何使用低端的128个编码,这与ASCII相当一致。不过,根据所在国籍的不同,处理编码128以上的字符有许多不同的方式。这些不同的系统称为代码页。
同时,甚至更为令人头疼的事情正在逐步上演,亚洲国家的字符表有成千上万个字符,这样的字符表是用8位二进制无法表示的。该问题的解决通常有赖于称为DBCS(double byte character set,双字节字符集)的繁杂字符系统。
不过,仍然需要指出一点,多数人还是姑且认为一个字节就是一个字符,以及一个字符就是8个二进制位,并且只要确保不将字符串从一台计算机移植到另一台计 算机,或者说一种以上的语言,那么这几乎总是可以凑合。当然,只要一进入Internet,从一台计算机向另一台计算机移植字符串就成为家常便饭了,而各 种复杂状况也随之呈现出来。令人欣慰的是,Unicode随即问世了。
作用:表语英语及西欧语言。
位数:ASCII是用7位表示的,能表示128个字符;其扩展使用8位表示,表示256个字符。
范围:ASCII从00到7F,扩展从00到FF。
2.iso8859-1
基础的表示单位一致,所以很多时候,仍 旧使用iso8859-1编码来表示。而且在很多协议上,默认使用该编码。比如,虽然”中文”两个字不存在iso8859-1编码,以gb2312编码为 例,应该是”d6d0 cec4″两个字符,使用iso8859-1编码的时候则将它拆开为4个字节来表示:“d6 d0 ce c4”(事实上,在进行存储的时候,也是以字节为单位处理的)。而如果是UTF编码,则是6个字节”e4 b8 ad e6 96 87″。很明显,这种表示方法还需要以另一种编码为基础。
作用:扩展ASCII,表示西欧、希腊语等。
位数:8位,
范围:从00到FF,兼容ASCII字符集。
3. GB码字符集
全称是GB2312-80《信息交换用汉字编码字符集基本集》,1980年发布,是中文信息处理的国家标准,在大陆及海外使用简体中文的地区(如新加坡 等)是强制使用的唯一中文编码。P-Windows3.2和苹果OS就是以GB2312为基本汉字编码, Windows 95/98则以GBK为基本汉字编码、但兼容支持GB2312。
双字节编码
范围:A1A1~FEFE
A1-A9:符 区,包含682个符
B0-F7:汉字区,包含6763个汉字
4.GB2312字符集
GB2312(1980年)一共收录了7445个字符,包括6763个汉字和682个其它符 。汉字区的内码范围高字节从B0-F7,低字节从 A1-FE,占用的码位是72*94=6768。其中有5个空位是D7FA-D7FE。GB2312-80中共收录了7545个字符,用两个字节编码一个 字符。每个字符最高位为0。GB2312-80编码简称国标码。
GB2312支持的汉字太少。1995年的汉字扩展规范GBK1.0收录了21886个符 ,它分为汉字区和图形符 区。汉字区包括21003个字符。
作用:国家简体中文字符集,兼容ASCII。
位数:使用2个字节表示,能表示7445个符 ,包括6763个汉字,几乎覆盖所有高频率汉字。
范围:高字节从A1到F7, 低字节从A1到FE。将高字节和低字节分别加上0XA0即可得到编码。
5. GB12345-90字符集
1990年制定了繁体字的编码标准GB12345-90《信息交换用汉字编码字符集第一辅助集》,目的在于规范必须使用繁体字的各种场合,以及古籍整理 等。该标准共收录6866个汉字(比GB2312多103个字,其它厂商的字库大多不包括这些字),纯繁体的字大概有2200余个。
双字节编码
范围:A1A1~FEFE
A1-A9:符 区,增加竖排符
B0-F9:汉字区,包含6866个汉字
6.GBK字符集
GBK编码(Chinese Internal Code Specification)是中国大陆制订的、等同于UCS的新的中文编码扩展国家标准。gbk编码能够用来同时表示繁体字和简体字,而gb2312只 能表示简体字,gbk是兼容gb2312编码的。GBK工作小组于1995年10月,同年12月完成GBK规范。该编码标准兼容GB2312,共收录汉字 21003个、符 883个,并提供1894个造字码位,简、繁体字融于一库。Windows95/98简体中文版的字库表层编码就采用的是GBK,通过 GBK与UCS之间一一对应的码表与底层字库联系。
英文名:Chinese Internal Code Specification
中文名:汉字内码扩展规范1.0版
双字节编码,GB2312-80的扩充,在码位上和GB2312-80兼容
范围:8140~FEFE(剔除xx7F)共23940个码位
包含21003个汉字,包含了ISO/IEC 10646-1中的全部中日韩汉字
作用:它是GB2312的扩展,加入对繁体字的支持,兼容GB2312。
位数:使用2个字节表示,可表示21886个字符。
范围:高字节从81到FE,低字节从40到FE。
7. BIG5字符集
是目前台湾、香港地区普遍使用的一种繁体汉字的编码标准,包括440个符 ,一级汉字5401个、二级汉字7652个,共计13060个汉字。BIG5又 称大五码或五大码,1984年由台湾财团法人信息工业策进会和五间软件公司宏碁 (Acer)、神通 (MiTAC)、佳佳、零壹 (Zero One)、大众 (FIC)创立,故称大五码。Big5码的产生,是因为当时台湾不同厂商各自推出不同的编码,如倚天码、IBM PS55、王安码等,彼此不能兼容;另一方面,台湾政府当时尚未推出官方的汉字编码,而中国大陆的GB2312编码亦未有收录繁体中文字。
Big5字符集共收录13,053个中文字,该字符集在中国台湾使用。耐人寻味的是该字符集重复地收录了两个相同的字:“兀”(0xA461及0xC94A)、“嗀”(0xDCD1及0xDDFC)。
Big5码使用了双字节储存方法,以两个字节来编码一个字。第一个字节称为“高位字节”,第二个字节称为“低位字节”。高位字节的编码范围0xA1-0xF9,低位字节的编码范围0x40-0x7E及0xA1-0xFE。
尽管Big5码内包含一万多个字符,但是没有考虑 会上流通的人名、地名用字、方言用字、化学及生物科等用字,没有包含日文平假名及片假字母。
例如台湾视“着”为“著”的异体字,故没有收录“着”字。康熙字典中的一些部首用字(如“亠”、“疒”、“辵”、“癶”等)、常见的人名用字(如“堃”、“煊”、“栢”、“喆”等) 也没有收录到Big5之中。
8.GB18030字符集
作用:它解决了中文、日文、朝鲜语等的编码,兼容GBK。
位数:它采用变字节表示(1 ASCII,2,4字节)。可表示27484个文字。
范围:1字节从00到7F; 2字节高字节从81到FE,低字节从40到7E和80到FE;4字节第一三字节从81到FE,第二四字节从30到39。
9.通用字符集(UCS)字符集
作用:国际标准 ISO 10646 定义了通用字符集 (Universal Character Set)。它是与UNICODE同类的组织,UCS-2和UNICODE兼容。
位数:它有UCS-2和UCS-4两种格式,分别是2字节和4字节。
范围:目前,UCS-4只是在UCS-2前面加了0x0000。
10.Unicode字符集
UTF-8
注意,虽然说utf是为了使用更少的空间而使用的,但那只是相对于unicode编码来说,如果已经知道是汉字,则使用GB2312/GBK无疑是 最节省的。不过另一方面,值得说明的是,虽然utf编码对汉字使用3个字节,但即使对于汉字 页,utf编码也会比unicode编码节省,因为 页中包 含了很多的英文字符。
UTF8编码后的大小是不一定,例如一个英文字母”a” 和 一个汉字 “好”,编码后占用的空间大小就不样了,前者是一个字节,后者是三个字节!编码的方法是从低位到高位。黄色为标志位其它着色为了显示其,编码后的位置。
UTF-16
由于0x00在c语言及操作系统文件名等中有特殊意义,故很多情况下需要UTF-8编码保存文本,去掉这个0x00。举例如下:
UTF-16: 0x0080 = 0000 0000 1000 0000
UTF-8: 0xC280 = 1100 0010 1000 0000
UTF-32
UTF-7
作用:为世界650种语言进行统一编码,兼容ISO-8859-1。
位数:UNICODE字符集有多个编码方式,分别是UTF-8,UTF-16和UTF-32。
很多人以为UTF-8等和Unicode都是字符集或都是编码方式,其实这是误区。
MIME 编码
Base64
为什么要使用Base64/strong>
在设计这个编码的时候,我想设计人员最主要考虑了3个问题:
1.是否加密br> 2.加密算法复杂程度和效率
3.如何处理传输/p>
基 于这个目的加密算法的复杂程度和效率也就不能太大和太低。和上一个理由类似,MIME协议等用于发送Email的协议解决的是如何收发Email,而并不 是如何安全的收发Email。因此算法的复杂程度要小,效率要高,否则因为发送Email而大量占用资源,路就有点走歪了。
基于以上的一些主要原因产生了Base64编码。
QP(Quote-Printable)

声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!