云计算与大数据概论(1) 云计算,大数据是什么
-
- 云计算的应用场景
- 云计算概念
-
-
- 云计算简史
- 云计算定义
- 云计算基本特征
-
- 大数据应用场景
- 大数据概念
-
-
- 大数据简史
- 大数据定义
- 大数据基础特征
-
- 两者之间的关系
云计算的应用场景
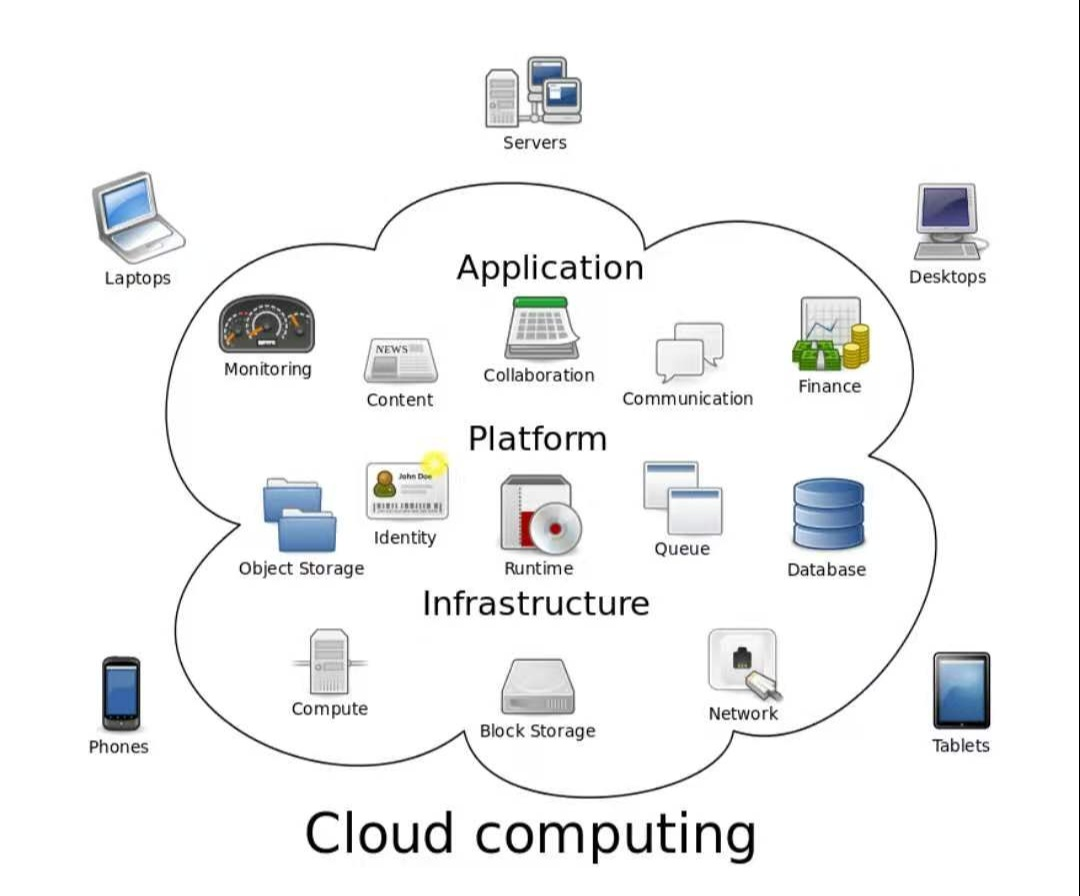

云计算概念
云计算有如此的魅力,那么下面我们将探究它的发展史:
云计算简史
1969年,ARPANET[1]项目的首席科学家 Leonard Kleinrock 表示:
“现在,计算机 络还处于初期阶段,但是随着 络的进步和复杂化,我们将可能看到’计算机应用’的扩展.……”
从 20 世纪 90年代中期开始,普通大众已经开始以各种形式使用基于Internet 的计算机应用,比如∶搜索引擎(Yahoo!、Google)、电子邮件(Hotmail、Gmail)、开放的发布平台(MySpace、Facebook、YouTube),以及其他类型的 交媒体(Twitter、LinkedIn)。虽然这些服务是以用户为中心的,但是它们普及并且验证了形成现代云计算基础的核心概念。
关于云计算,我们应当了解其定义,以更好的熟悉和掌握它:
云计算定义
Forrester Research 公司将云计算定义为∶
“.…一种标准化的IT 性能(服务、软件或者基础设施),以按使用付费和自助服务方式,通过 Internet 技术进行交付。”
该定义被业界广泛接受,它是由美国国家标准与技术研究院(NIST)制定的。早在 2009 年,NIST就公布了其对云计算的原始定义,随后在 2011年9月,根据进一步评审和企业意见,发布了修订版定义∶
“云计算是一种模型,可以实现随时随地、便捷地、按需地从可配置计算资源共享池中获取所需的资源(例如, 络、服务器、存储、应用程序及服务),资源可以快速供给和释放,使管理的工作量和服务提供者的介入降低至最少。这种云模型由五个基本特征、三种服务模型和四种部署模型构成。”
在《云计算概念技术与架构》一书中,有如下定义:
云计算是分布式计算的一种特殊形式,它引入效用模型来远程供给可扩展和可测量的资源。
在维基百科对云计算的最新[2]定义为:、
云计算(英语:cloud computing),也被意译为 络计算,是一种基于互联 的计算方式,通过这种方式,共享的软硬件资源和信息可以按需求提供给计算机各种终端和其他设备,使用服务商提供的电脑基建作计算和资源。
Google对云计算的定义:
将所有的计算和应用放置在“云”中,终端设备不需要安装任何软件,通过互联 来分享程序和服务。
某家互联 数据中心[3]对云计算的定义:云计算是一种新型的IT技术发展,部署及发布模式,能够通过互联 实时提供产品,服务,解决方案。
NIST[4]对云计算的定义是:
云计算是一种无处不在,便捷的,通过互联 访问的一个可定制的IT资源(IT资源包括 络,服务器,储存,应用软件和服务)共享池,是一种按使用量付费的模式。它能够通过最少量的管理与服务供应商的互动实现计算资源的迅速供给和释放。
云计算基本特征
互联 上汇聚的计算资源、存储资源、数据资源和应用资源正随着互联 规模的扩大而不断增加,互联 正在从传统意义的通信平台转化为泛在、智能的计算平台。
与计算机系统这样的传统计算平台比较,互联 上还没有形成类似计算机操作系统的服务环境,以支持互联 资源的有效管理和综合利用。
在传统计算机中已成熟的操作系统技术,已不再能适用于互联 环境,其根本原因在于:互联 资源的自主控制、自治对等、异构多尺度互联 上汇聚的计算资源、存储资源、数据资源和应用资源正随着互联 规模的扩大而不断增加,互联 正在从传统意义的通信平台转化为泛在、智能的计算平台。
为了适应互联 资源的基本特性,形成承接互联 资源和互联 应用的一体化服务环境,面向互联 计算的虚拟计算环境(Internet-based Virtual Computing Environment,iVCE)的研究工作,使用户能够方便、有效地共享和利用开放 络上的资源。等基本特性,与传统计算机系统的资源特性存在本质上的不同。为了适应互联 资源的基本特性,形成承接互联 资源和互联 应用的一体化服务环境,面向互联 计算的虚拟计算环境(Internet-based Virtual Computing Environment,iVCE)的研究工作,使用户能够方便、有效地共享和利用开放 络上的资源。
互联 上的云计算服务特征和自然界的云、水循环具有一定的相似性,因此,云是一个相当贴切的比喻。根据美国国家标准和技术研究院的定义,云计算服务应该具备以下几条特征[5]:
1.
随需应变自助服务。
2.
随时随地用任何 络设备访问。
3.
多人共享资源池。
4.
快速重新部署灵活度。
5.
可被监控与量测的服务。
一般认为还有如下特征:
1.
基于虚拟化技术快速部署资源或获得服务。
2.
减少用户终端的处理负担。
3.
降低了用户对于IT专业知识的依赖。
大数据应用场景
交通领域
无人驾驶就是在人的驾驶过程中实时采集车辆周边数据和驾驶控制信息,然后通过机器学习,获得周边信息与驾驶方式的对应关系(自动驾驶模型),然后将这个模型应用到无人驾驶的车辆上。通过物理传感器获取周边车辆信息,应用模型,就能达到自动驾驶的效果。
金融-分控
大数据在金融领域应用比较成熟的是大数据风控,如何识别高风险用户据大量的历史数据,通过大数据的模型计算,得出用户的特征和风控模型。当新用户发起资金操作时,很好的预测用户的风险指数。
医疗健康
其中图像识别也是机器学习最成熟的一个方面,在医疗行业,可以通过对大量的图片数据进行学习训练,从而更加客观的识别出医疗影像的病例特征,更准确的识别病原。
教育
一些教育平台通过人工智能的外语老师进行教学,一些新闻播 也利用人工智能的主持人去播放内容。
大数据概念
大数据简史
如今,在讨论大数据的时候,人们通常会把沃尔玛“啤酒与尿布”的故事与谷歌“预测流感”的故事作为案例一起分析,就好像这两个故事发生的时间大体相似。实际情况是,当沃尔玛有意识地利用销售数据预测顾客的购买动机及行为时,谷歌公司还没有成立。作为大数据应用的知名商业案例,“啤酒与尿布”的故事可以追溯到20世纪90年代。当时,沃尔玛超市管理人员分析其销售数据时,发现了一个难以理解的现象:在日常的生活中,“啤酒”与“尿布”这两件商品看上去风马牛不相及,但是经常会一起出现在美国消费者的同一个购物篮中。这个独特的销售现象引起了沃尔玛管理人员的关注。经过一系列的后续调查证实,“啤酒+尿布”的现象往往发生在年轻的父亲身上。当然,这个现象源于美国独特的文化。在有婴儿的美国家庭中,通常都是由母亲在家中照看婴儿,去超市购买尿布一般由年轻的父亲负责。年轻的父亲在购买尿布的同时,往往会顺便为自己购买一些啤酒。沃尔玛的管理人员发现该现象后,立即着手把啤酒与尿布摆放在相同的区域,让年轻的美国父亲非常方便地找到尿布和啤酒这两件商品,并让其较快地完成购物。这样一个小小的陈列细节让沃尔玛获得了满意的商品销售收入。
2008年——走向正统
2008年对“大数据”而言算得上是一个分水岭,因为国际知名杂志《自然》推出专刊,对其做了介绍。3年后,美国的《科学》杂志也做了同样的事情。它们从互联 技术、互联 经济学、超级计算、环境科学、生物医药等多个方面介绍了海量数据所带来的技术挑战,自此,“大数据”一发不可收拾,成为学界研究的热点。鉴于《自然》、《科学》等杂志在国际学术圈中的权威及影响,推出专刊介绍大数据,无异于为其作了背书。如果说,大数据在此之前只是商人、学者零散的激情,那么此后则成为了整个 会的共鸣。
2012年——新的时代
2012年,有两本书在国内市场上异常火爆,一本是著名信息管理专家、科技作家涂子沛的《大数据》,另外一本是著名数据科学家维克托·迈尔-舍恩伯格的《大数据时代》。当然,有关大数据的作品还有很多,但这两本书最有代表性,因为他们用通俗易懂的语言,形式多样的案例对大数据做了一次既具有科普性又不失趣味性的解读。特别是维克托·迈尔-舍恩伯格,从理论的层面预言大数据将导致人类思维、商业以及管理领域的变革。以思维为例,之前人们以“因果”作为拓展新知,产生洞见的固有逻辑,但大数据的出现将“相关关系”上升到思维的高度。基于此,有学者甚至发出“理论的终结”之类的感叹。不管上述分析正确与否,大数据作为一个时代的标签已经成型。这一判断非常容易得到确认,因为现代 会所有的设备和系统,如果没有数据的参与,就无法智能。云计算也好,人工智能也罢,从根本上讲,都是靠数据驱动的。19世纪、20世纪有很多标签,但不妨碍我们称其为“石油时代”。同理,21世纪还存在着诸多可能,但不妨碍我们称其为“大数据时代”。
文2:[9]
熟知大数据发展历史,才能更好理解其产生的缘由。再去学习技术知识,定会明朗很多,同时更深入技术的本质。
大数据史可以从两个方面来讲:
技术产生史和发展史
一、大数据技术产生史
首先看一下我们要介绍的大数据技术栈包含什么:
Hadoop; MapReduce; NoSQL; Spark; Flink; Hive…
这个都属于大数据的技术栈,初看起来,杂乱无章。对于初学者更甚,无从下手,更不知道哪些是重点,哪些是辅助技术。
所以,我们先把这些技术的产生搞清楚,以及他们能应用什么场景。这样你就做到心里有数,剩下的就是各个击破,自己慢慢学习。
起源于Google
大家都知道最早搜索引擎是Google.其功能是提供互联 用户的信息的检索功能。那搜索引擎具体都干了哪些事呢/p>
其实很简单的两件事:
一是数据采集,也就是 页的爬取;
二是数据搜索,也就是索引的构建;
数据采集离不开存储,索引的构建也需要大量计算,所以存储容器和计算能力贯穿搜索引擎的整个更迭过程。
在2004年前后,Google发表了三篇重要的论文,俗称“三驾马车”:
Google File System(GFS), MapReduce,BigTable
在互联 早期,互联 产品用户规模都不是很大,很少的人会关注分布式解决方案,都在单体机器上寻找解决方案,也就是在硬件上下功夫;
而Google在当时的互联 界,不管是用户规模还是所产生数据量都是TOP级别的。所以,对分布式和集群等方式,解决存储方式研究较早,同时也采用横向拓展的思路,去研发系统。
Hadoop的产生
最早关注 Google 大数据论文的是一个程序员,也不陌生,Lucene项目的创始人 Doug Cutting。他看到论文后,颇为激动,程序员,动手能力当然很强,很快就依据论文的原理实现了类似 GFS 和 MapReduce的功能框架。注意是类似哦。
到了2006年,DC 开发的类似MapReduce功能的大数据技术,被独立出来,单独开发运维。这个也就是不就后被命名为 Hadoop 的产品。 该体系里面包含,大家熟知的分布式文件系统 HDFS 以及大数据计算引擎 MapReduce。
Yahoo 优化改编
当 Hadoop 发布之后,另一个当时的搜素引擎巨头 Yahoo 很快就使用了起来;
到了2007年,国内的百度也开始使用了 Hadoop 进行大数据存储与计算了。
又过了一年,2008年,Hadoop 正式成为 Apache 的顶级项目,自此,Hadoop 彻底火了起来,也被更多的人熟知。
当然任何系统都不可能是完美的,也不可能是通用的,并非适用于每个公司。 Yahho 使用了 MapReduce 进行大数据计算时,觉得开发太繁琐,于是他们自己便开发了一个新的系统–Pig。
Pig是一个基于 Hadoop 类 SQL 语句的脚本语言。经过编译后,直接生成 MapReduce 程序,在 Hadoop系统上运行。所以 Yahho 也是在Hadoop 基础上进行了 编程上的优化使用。
Facebook 的数据分析 Hive
Yahho 的 Pig 是一种类似于 SQL 语句的脚本语言,相比于直接编写 MapReduce 简单许多。但是使用者还是要学习这种新的脚本语言。
又一家巨头公司出现了 Facebook 为了数据分析也开发一种新的分析工具,叫做 Hive 的东西,hHive 能直接使用SQL语句进行大数据计算,这样,只要是具有数据库关系型语言的开发人员就能直接使用大数据平台。大大的降低了使用的门槛,又将大数据技术推进了一步。
至此,大数据主要的技术栈基本形成。包括 HDFS、MapReduce、Pig、Hive.
责任单一 Yarn
此时,MapReduce 一个资源调度框架,又是一个执行引擎。为了责任单一化,将这两种功能进行了分离,Yarn 项目启动了。
2012年, Yarn 成为了独立的项目,开始运营,被各大数据厂商的产品支持,成为了主流的资源管理调度系统。
效率还是效率 Spark
同年,UC 伯克利 AMP 实验室的一位博士,在使用 MapReduce 进行大数据实验计算时,发现性能非常差,不能满足其计算需求。
为了改进这种效率低下的工作方式,于是开发出了一个性能优越的替代产品,叫做 Spark 。由于Spark 性能卓著,一经推出,就受到了业界的认可,开始全面替代 MapReduce。
批处理计算和流式计算
大数据计算根据分析数据的方式不同,有两个类别。一种叫做批处理计算,比如 MapReduce、Spark 这种,针对的是某个时间段的数据进行计算(比如“天”“小时”的单位)。
这种计算由于数据量大,需要花费几十分钟甚至更长。同时这种计算的数据是非在线实时获取的数据,也就是历史积累的数据,也就是离线数据,这种计算又被称为“离线计算”。
离线计算针对的是历史数据,相对的就有针对的实时数据进行计算,也就是系统接收到数据就进行计算,这种计算叫做“流式计算”。
由于处理的数据是实时在线产生的,又被称为“实时计算”。
流式计算技术 Storm、Flink、 Spark Streaming
怎么理解流式计算呢简单的,把批处理计算的时间单元缩小到数据产生的间隔就是了。“流式计算”具有代表性的框架,比如:Storm、Flink、 Spark Streaming。
特别说一点,Flink 就牛了一些,既支持流式计算又支持批处理计算。
非关系型数据库
在2011年 左右 NoSQL 非常火爆,其中 HBase 是从Hadoop中分拆出去的,也就是底层还是HFDS 技术。所以 NoSQL 系统在大数据环境下,提供海量数据的存储和访问功能,也算是大数据技术栈一员。
数据分析,数据挖掘,机器学习
有了大数据这个底层的技术基础,更广的应用也就能实现了。大数据平台,继承了数据分析和数据挖掘技术,以及在大数据基础上,更高级的机器学习技术。
数据分析主要是数据专员的工作,一般不需要开发能力,会使用简单的 SQL 基本上够用了。一些公司的运营人员,也要求具有数据分析的能力。数据分析主要是利用上面提到的 Hive、Spark SQL 等 数据库脚本语言;
有了大数据的存储和计算能力,就能进行数据挖掘和机器学习。当然也有成熟的框架,比如Mahout、Google 的 TersorFlow等框架。
最后,有了基础的存储功能,大数据批处理,流失处理计算能力,之上的大数据分析,以及更高级的挖掘和机器学习。至此一个大数据平台就构成了。
二、大数据应用发展史
大数据技术不断的更迭,同样的,在技术之上的应用,也经历了一个发展过程。
从最早的 Google公司,解决搜索引擎业务,到目前最火的AI技术。大数据应用越来越广泛。
Google 搜索引擎时代
在Google 之前,一直是 Yahho 在搜索引擎领域领先。从 Google 发布三篇大数据论文开始,Google 扭转了局面。
通过HDFS 对海量数据的存储,运用 MapReduce 技术高效的计算 页内容,提高用户的检索能力,正是这些大数据技术的发展,让 Google 傲立搜索引擎之巅。
后续的人工智能,无人驾驶技术 Google 也一直推动行业发展。
数据仓储、大数据分析时代
稍具规模的公司,都会有数据专员这种角色,不管是给老板提供数据,还是为产品人员提供数据支持。原来的工作方式,以传统的关系型数据库为主,跑一些 SQL 语句出 表数据。
简单来说,数据人员利用 Hive 可以在 Hadoop 上进行 SQL 操作,实现数据统计与分析。
大数据挖掘时代
“买尿不湿的人通常也会买啤酒” 这个梗又要抬出来了。也许这个最能体会数据挖掘的作用。
帮助用户发现自己都不知道需要的需求,帮助电商平台推荐最适合用户的产品,更好销售自己的产品,帮助 交平台根据用户的画像更好的挖掘出最优关联性 交关系。
机器学习时代
有了大数据技术,可以把历史数据收集起来,统计其中的规律,进而预测正在发生的事情,这就是机器学习。AlohaGo 战胜世界冠军为起点,机器学习迎来了一波高潮,小米的小爱同学,天猫盒子,等语音聊天也将机器学习推广到了寻常百姓家。
AI(人工智能) 时代
将全部的数据,通过机器学习得到统计规律,进而模拟人的行为,是机器能像人类一样的思考,这就是人工智能。以AI为主题的电影电视也层出不穷,还有人会担心,人工智能的发展会超过人来的智能。
大数据产生的原因:
随着计算机技术全面融入 会生活的,信息爆炸已经积累到了一个开始引发技术创新和商业变革的阶段。二十一世纪是信息技术大发展的时代,互联 、物联 、车联 、gps、医学影像、安全监控、金融、电信等众多领域都在疯狂产生的大量的数据,这些数据不仅使世界充斥着比以往更多的信息,而且由这些数据产生出大数据这个众人皆知的概念。
大数据技术的产生,首先源于互联 企业对于日益增长的 络数据分析的需求。
20世纪80年代的典型代表是雅虎的分类目录搜索数据库
20世纪90年代的典型代表是谷歌,它开始运用算法分析用户搜索信息,以满足用户的实需求。
21世纪的典型代表是Facebook,它不仅满足用户的实际需求,而且创造需求。
因为此时web2.0出现,使人们从信息的被动接受者变成主动造者。
大数据定义
百度给出的定义:是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
《云计算与大数据技术应用》一书中,对大数据的定义:
大数据是现有数据库管理软件和传统数据处理应用方法很难处理的大型复杂的数据集,大数据技术的范畴包括大数据的采集,储存,搜索,共享,传输,分析和可视化。
大数据基础特征
大数据四个基本属性(4V特性):
1、数据量大(规模性)(Volume)
2、要求快速响应(高速性)(Velocity)
3、数据多样性(多样性)(Variety)
4、价值密度低(价值)(value)
完整特征:
1、容量(Volume):数据的大小决定所考虑的数据的价bai值和潜在的信息。
2、种类(Variety):数据类型的多样性。
3、速度(Velocity):指获得数据的速度。
4、可变性(Variability):妨碍了处理和有效地管理数据的过程。
5、真实性(Veracity):数据的质量。
7、价值(value):合理运用大数据,以低成本创造高价值。
两者之间的关系
大数据与云计算两者之间的关系:[11]
从商业的角度,云计算和大数据是现在企业走向数字化运营的两个核心。
- 云计算统一企业 IT 架构、业务架构和数据架构,不仅以集约化的方式承载业务,也收集业务数据。
- 云计算为大数据存储、快速处理和分析挖掘提供基础能力。
- 大数据处理能力可以作为云计算服务提供,丰富云计算平台的能力。
- 大数据分析可以产生预测能力、商业洞察,可以指导云平台建设(例如所谓的 AIOps,当然目前还有待提高)
[0]转自:https://www.zhihu.com/question/19877274
[1]APRANET:Advanced Research Project Agency Network,APRANET,为Internet 的前身
[2]最新:时间为2020年11月21日11:21:08
[3] Internet Data Center,简称IDC:是指一种拥有完善的设备(包括高速互联 接入带宽、高性能局域 络、安全可靠的机房环境等)、专业化的管理、完善的应用的服务平台。在这个平台基础上,IDC服务商为客户提供互联 基础平台服务(服务器托管、虚拟主机、邮件缓存、虚拟邮件等)以及各种增值服务(场地的租用服务、域名系统服务、负载均衡系统、数据库系统、数据备份服务等)
[4] 美国国家标准与技术研究院(National Institute of Standards and Technology,NIST)直属美国商务部,从事物理、生物和工程方面的基础和应用研究,以及测量技术和测试方法方面的研究,提供标准、标准参考数据及有关服务,在国际上享有很高的声誉。
[5]内容来自维基百科[7]
[8]来自百家 :https://baijiahao.baidu.com/sd=1636247330938128653&wfr=spider&for=pc
[9]来自知乎:https://zhuanlan.zhihu.com/p/57475298
[10]来自360:http://www.360doc.com/content/18/0319/17/52420492_738478905.shtml
[11]来自知乎:https://www.zhihu.com/question/31912565
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!