广西人才 实习信息爬取与数据库存储实战 https://www.gxrc.com/
大家好,我是W
项目介绍:本项目为CrawlSpider结合MySQL、MongoDB爬取求职 站信息的项目,目标是将 站指定分类下的招聘信息(包括:职位名称、公司名称、薪资、工作地点、更新时间、招聘人数、学历要求、经验要求、公司性质、职位要求、公司介绍、公司规模、联系人、联系电话、email、联系地址)。本项目将涉及CrawlSpider模板、项目分析、xpath数据提取、爬虫中间件设置UA和IP、MySQL数据库操作、MongoDB数据库操作。
站分析
- 首先进入广西人才 首页**https://www.gxrc.com/,点击左侧菜单栏中的计算机/互联 /通信/电子 下的计算机软件开发类**分类查看URL。可以看到URL为https://s.gxrc.com/sJobhType=1&expend=1&PosType=5480。经过删删改改可以推测出实际有用的URL为https://s.gxrc.com/sJobsType=5480(代表gxrc 下的计算机软件开发类[type=5480])
- 接下来对搜索条件进行筛选,本次项目需要筛选的条件为{工作性质:毕业生职位,工作经验:1年内},经过选择并观察URL知道URL应为:https://s.gxrc.com/sJobsType=5480&workProperty=-1&workAge=1&page=1&pageSize=20。并且page为页码,pagesize为每页显示条数。
- 第三步打开F12,查看翻页结果。可以明显看到翻页的规则就是通过改变上面URL的page和pagesize得到的,所以在构建Rule的时候很容易编写。
创建CrawlSpider项目并编写Rule规则
-
创建CrawlSpider项目在https://blog.csdn.net/Alian_W/article/details/104102600
有,我就不多赘述。 -
编写Rule规则,通过F12查看可以知道每个页面的详情页规则是
-
因为招聘信息很多,为了不让爬虫跑出去爬出不符合条件的信息所以修改这是如果有细心地同学去试着打印response.text会发现爆出了错误,显然我们的allowed_domains写错了。仔细观察url会发现我们允许的url为,但是详情页没有s.,这就很尴尬。所以必须修改URL为
-
start_urls 改为
-
rules 定义
Xpath信息提取
-
试着打印一下请求出来的页面内容
在成功打印出来之后我们就可以对页面进行xpath提取了。
2. 先到Items.py定义字段
-
xpath提取数据(基本功不详细介绍了,也可以用css选择器,re表达式)
对spider里yield出来的item在pipeline中进行处理
MySQL存储
-
在settings文件中设置mysql数据库的参数
-
其中涉及python对mysql的操作,不了解的同学可以参考https://www.cnblogs.com/hanfanfan/p/10398244.html
MongoDB存储
-
在settings文件中设置mongodb数据库的参数
-
其中涉及python对mongodb的操作,不了解的同学可以参考https://www.cnblogs.com/cbowen/archive/2019/10/28/11755480.html
最后在settings里配置两个pipeline
注意:mysql不会自动建表,需要在本地数据库建好相应的表
到此整个广西人才 的爬虫已经结束了,大家可以根据自己感兴趣的条件自行修改rules就可以爬取全站信息。
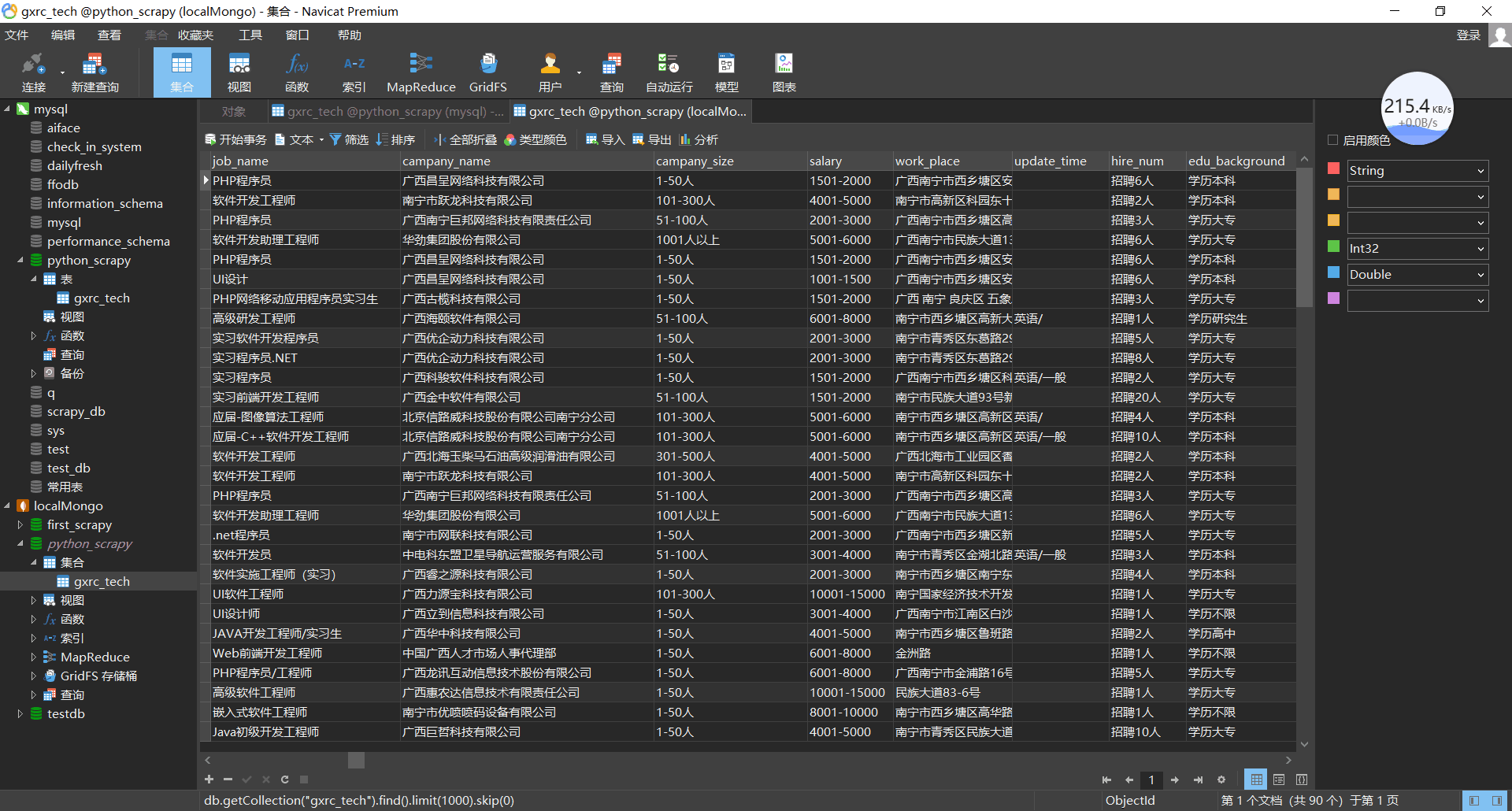
成果

GitHub链接
广西人才 实习信息爬取与数据库存储实战
文章知识点与官方知识档案匹配,可进一步学习相关知识Python入门技能树首页概览211375 人正在系统学习中
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!