什么是大数据
大数据能做什么
Hadoop起源
Hadoop组件
Hadoop搭建
一、什么是大数据
大数据(big data),IT行业术语,是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。 —-百度百科
二、大数据能做什么
-
洛杉矶警察局和加利福尼亚大学合作利用大数据预测犯罪的发生。
-
Google流感趋势(Google Flu Trends)利用搜索关键词预测禽流感的散布。
-
梅西百货的实时定价机制。根据需求和库存的情况,该公司基于SAS的系统对多达7300万种货品进行实时调价。
-
医疗行业早就遇到了海量数据和非结构化数据的挑战,而近年来很多国家都在积极推进医疗信息化发展,这使得很多医疗机构有资金来做大数据分析。
-
新的处理模式包括但不限于:大规模并行处理数据库,数据挖掘,分布式文件系统,分布式数据库,云计算平台,可扩展存储系统等。
—-百度百科
三、Hadoop起源
3.1 Hadoop是什么
是一种分析和处理海量数据的开源软件平台,提供一个分布式基础框架,由java开发。
3.2 Hadoop特点
高可靠性、高扩展性、高效性、高容错性、低成本。
3.3 Hadoop由来
2003年google发表了几篇论文:GFS、MapReduce、BigTable。
是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。运行在硬件上,提供容错功能。
是针对分布式并行计算的一套编程模型。由Map和Reduce组成,Map是映射,把指令分发到多个worker上去;reduce是规约,把Map的worker计算的结果合并。
存储结构化数据。建立在GFS,Scheduler, Lock Service和MapReduce之上的。每个table都是一个多维的稀疏图
Yahoo根据论文用java将其实现,并命名为Hadoop。(HDFS+MapReduce+Hbase)
四 Hadoop生态系统
-
JobTracker:Master节点(只有一个),管理所有作业;作业/任务的监控、错误处理;将作业分解成一系列任务,并分派给TaskTracker。
-
TaskTracker:Slave节点(可多个),运行Map Task和Reduce Task;并与JobTracker交互,汇 任务状态
-
Map Task:解析每条数据记录,传递给用户编写的map()并执行,将输出结果写入本地磁盘(若为map-only作业,直接写入HDFS)。
-
Reduce Task:从Map Task的执行结果中,远程读取输入数据,对数据进行排序,将数据安装分组传递给用户编写的reduce函数执行。
5.3 Yarn集群资源管理系统
Yarn的核心思想:将JobTracker和TaskTacker进行分离,由以下组件构成:
| 组件 | 描述 |
|---|---|
| ResourceManager | 一个全局资源管理器 |
| NodeManager | 每个节点(RM)代理 |
| ApplicationMaster | 代表每个应用,每个有多个Container在NodeManager上运行 |
5.3.1 结构图
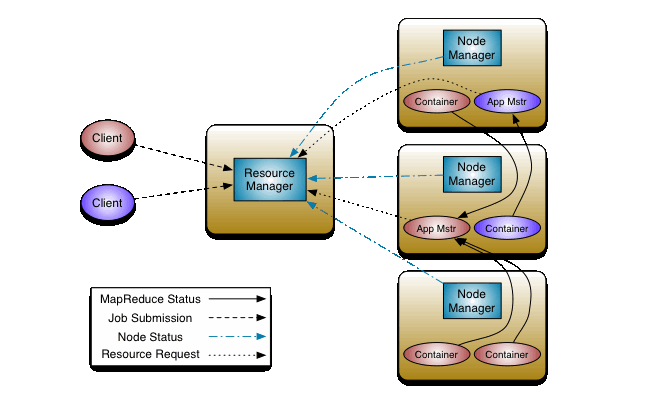

5.3.2 角色和概念
- ResourceManager:处理客户端请求;启动/监控ApplicationMaster;监控NodeManager;资源分配和调度。
- NodeManager:单节点上的资源管理;处理来自ResourceManager的命令;处理来自ApplicationMaster的命令
- ApplicationMaster:数据切分;为应用程序申请资源、并分配给内部任务;任务监控与容错。
- Container:对任务运行环境的抽象,封装了CPU、内存等;多维资源以及环境变量、启动命令等任务运行相关的信息资源分配与调度
- Client: 用户于Yarn交互的客户端程序;提交应用程序、监控应用程序状态,杀死应用程序等。
六、Hadoop搭建
6.1 单节点
6.2 伪分布式
6.3 完全分布式
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!