【翻译】MOA – Massive Online Analysis, a Framework for Stream Classification and Clustering. MOA – 海量在线分析,一个流分类聚类框架
摘要 Abstract
? 海量在线分析(MOA)是一个软件环境,可以用于实现算法和运行实验,从不断演变的数据流中进行在线学习。MOA的设计是为了解决将最先进算法的实现扩展到真实世界数据集大小的挑战性问题。它包含了用于分类和聚类的离线在线集合,以及用于评估的工具。特别的,对于分类,它实现了boosting树算法、bagging树算法和Hoeffding树算法,所有在叶节点存在和不存在分类器的朴素贝叶斯算法。对于聚类算法,它实现了streamk++、CluStream、ClusTree、Den-Stream、D-Stream和CobWeb。研究人员可以通过MOA深入理解不同算法的工作原理以及不同算法存在的问题,实践者可以很容易地将几种算法应用于现实世界的数据集和设置并进行比较。MOA支持与WEKA(用于知识分析的Waikato环境)的双向交互,并在GNU GPL许可下发布。
1 介绍 Introduction
? 如今,来自移动应用、传感器应用、 络监控和流量管理的测量、web探索中的日志记录或点击流、制造流程、电话详细记录、电子邮件、博客、twitter帖子等的数据生成速度越来越快。事实上,所有产生的数据都可以被认为是流数据,或者是流数据的快照,因为这些数据是在一个时间间隔内获得的。
? 在数据流模型中,数据到达速度非常快,算法必须在非常严格的空间和时间限制下对数据进行处理。MOA就是一个可以用于处理大量的、无限的、不断演变的数据流的开源框架。
? 数据流环境与传统的批处理学习环境有不同的要求。最重要的是以下几点:
? 图2 : MOA图形用户界面
? 考虑到数据流在纯分布式的环境下被生成,MOA建模了一个概念漂移事件作为漂移之前和漂移之后概念的加权组合。在这个框架中,可以定义流中样本在漂移后属于新概念的概率。它使用sigmoid函数,作为一个优雅和实用的解决方案(Bifet et al., 2009a,b)。
? MOA包含文献中最常见的数据的生成器。MOA数据流可以使用生成器构建,读取ARFF文件,加入多个流,或过滤流。它们可以模拟可能无限的数据序列。下面的生成器是目前可用的:随机树生成器,海洋概念生成器,STAGGER概念生成器,旋转超平面,随机RBF生成器,LED生成器,波形生成器,和函数生成器。目前实现的分类器方法包括:朴素贝叶斯、决策树墩、Hoeffding树、Hoeffding选项树(Pfahringer et al., 2008)、Bagging、Boosting、使用ADWIN的Bagging以及使用自适应大小Hoeffding树的Bagging (Bifet et al., 2009b)。
? 在案例EvaluateInterleavedTestThenTrain中,任务生成了CSV文件,在WaveformGenerator数据上训练HoeffdingTree分类器,训练和测试总计1亿个样本,每100万个样本做测试,该案例被封装在下面这个命令行中:
? MOA易于使用和扩展。一个简单的方式来实现一个新的分类器就是继承moa.classifiers.AbstractClassifier,这个类会处理一些细节来减轻任务。
3 聚类 Clustering
MOA还包含了一个数据流聚类的实验框架,该框架允许在不同的自定义数据或真实数据上比较不同的方法,这使得研究人员可以很容易地运行和构建实验数据流基准。MOA流聚类的特点有:
- 用户生成不断变化数据流的数据生成器(包括新数据、合并等)(Spiliopoulou et al., 2006)
- 一系列可以扩展的流式聚类算法
- 流式聚类算法的评价方法
- 分析结果和比较不同设置参数的可视化工具
? 对于流聚类,我们添加了新的数据生成器,支持模拟聚类演化事件,如合并或消失的聚类(Spiliopoulou等人,2006)。目前MOA包含了几种流聚类方法,如StreamKM++ (Ackermann et al., 2010)、CluStream (Aggarwal et al., 2003)、ClusTree (P. et al., 2010)、Den-Stream (Cao et al., 2006)、D-Stream (Tu and Chen, 2009)和CobWeb (Fisher, 1987)。此外,MOA还包含了用于分析所生成的聚类模型的性能的方法,包括文献中常用的方法,以及用于比较和评价在线和离线部分的新的评价方法。MOA中可用的度量方法既可以评估样本的正确分配(Chen, 2009),也可以评估聚类结果的紧凑性。
? 除了提供一个评估框架之外,第二个关键目标是可拓展的基准测试套件,包括实现的算法集以及可用的数据反馈和评估措施。
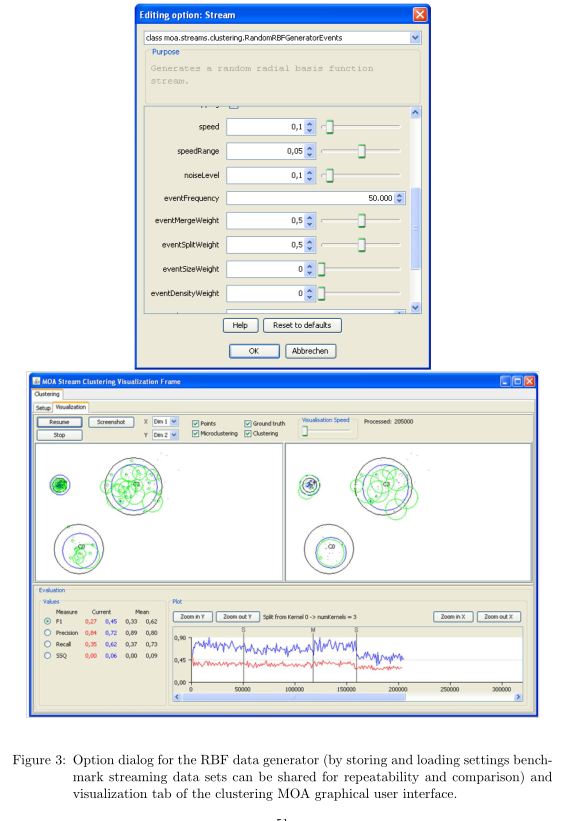
? 可视化组件允许可视化流和聚类结果,选择多维设置的维度,并行地比较不同设置参数的实验。图3是可视化选项卡的屏幕截图。这个屏幕截图中,在相同的流比较了两种不同设置参数的CluStream算法的效果(Aggarwal et al., 2003)(包括每50000个例子中的合并/拆分事件),选取5个测量值(CMD、F1、Precision、Recall和SSQ)进行在线评价。图形用户界面的上部提供了暂停和恢复流、调整可视化速度、选择x和y的尺寸以及要显示的组件(点、微观和宏观聚类和ground truth)的选项。GUI的下面部分显示的数字是两种设置的测量值(左边,包括平均值),并将当前选择的度量值显示为到达的示例的绘图(右边,本例中的F1度量)。对于给定的设置参数,在大约160000个样本时,可以看到拆分事件后性能的明显下降(在图中选择相应的垂直线时显示事件详细信息)。虽然这两种设置都适用,左边的设置(红色,100个微簇的CluStream)总是被右边的超过(蓝色,20个微簇的CluStream)。

4 站,教程和文档 Website, Tutorials, and Documentation
MOA是一种针对海量数据流的分类聚类系统,具有以下特点:
- 是可以用于实战、研究和教学的开源工具和框架。
- 有一系列可用于测试和比较文献的方法的算法的实现。
- 有可以用于存储、分享和重复的标准数据流,还可以设置不同的数据,有噪声选项,支持人造或真实数据集。
? MOA是用Java编写的。Java的主要优点是可移植性,应用程序可以在任何平台上使用适当的Java虚拟机运行,以及强大且开发良好的支持库。该语言的使用非常广泛,自动垃圾收集等特性有助于减少程序员的负担和错误。
? MOA可以在以下 站找到:http://moa.cs.waikato.ac.nz/。该 站包括教程、API参考、用户手册和关于挖掘数据流的手册。有几个如何使用该软件的例子。关于MOA到流聚类的扩展的其他材料可以在http://dme.rwth-aachen.de/moa-datastream/找到。
? 材料中还包含软件的使用视频,大多数重要的可能开发者需要拓展该框架时所需要的接口的截图和解释。
5 总结 Conclusions
我们的目标是构建一个实验性框架,用于在数据流上进行分类和聚类,类似于WEKA框架。我们的流学习框架提供了一套数据生成器、算法和评估措施。实践者可以通过比较现实场景中的几种算法并选择最佳的拟合解决方案。对于研究人员来说,我们的框架可以洞察不同方法的优缺点,并允许通过存储的、共享的和可重复的数据源设置创建基准流数据集。这些源代码是公开的,并且在GNU GPL许可下发布。尽管目前MOA的重点是分类和聚类,我们计划扩展框架,包括回归和频繁模式学习(Bifet, 2010)。
参考文献 References
Marcel R. Ackermann, Christiane Lammersen, Marcus M?rtens, Christoph Raupach, Chris-
tian Sohler, and Kamil Swierkot. StreamKM++: A clustering algorithm for data streams.
In SIAM ALENEX, 2010.
Charu C. Aggarwal, Jiawei Han, Jianyong Wang, and Philip S. Yu. A framework for
clustering evolving data streams. In VLDB, pages 81–92, 2003.
Albert Bifet. Adaptive Stream Mining: Pattern Learning and Mining from Evolving Data
Streams. IOS Press, 2010.
Albert Bifet, Geoff Holmes, Bernhard Pfahringer, and Ricard Gavaldà. Improving adap-
tive bagging methods for evolving data streams. In First Asian Conference on Machine
Learning, ACML 2009, 2009a.
Albert Bifet, Geoff Holmes, Bernhard Pfahringer, Richard Kirkby, and Ricard Gavaldà.
New ensemble methods for evolving data streams. In 15th ACM SIGKDD International
Conference on Knowledge Discovery and Data Mining, 2009b.
Feng Cao, Martin Ester, Weining Qian, and Aoying Zhou. Density-based clustering over an
evolving data stream with noise. In SDM, 2006.
J. Chen. Adapting the right measures for k-means clustering. In ACM KDD, pages 877–884,
2009.
Douglas H. Fisher. Knowledge acquisition via incremental conceptual clustering. Ma-
chine Learning, 2(2):139–172, 1987. ISSN 0885-6125. doi: http://dx.doi.org/10.1023/A:
1022852608280.
Jo? ao Gama, Raquel Sebasti? ao, and Pedro Pereira Rodrigues. Issues in evaluation of stream
learning algorithms. In 15th ACM SIGKDD International Conference on Knowledge
Discovery and Data Mining, 2009.
Richard Kirkby. Improving Hoeffding Trees. PhD thesis, University of Waikato, November
2007.
Kranen P., Assent I., Baldauf C., and Seidl T. The ClusTree: Indexing micro-clusters for
anytime stream mining. In Knowledge and Information Systems Journal (KAIS), 2010.
Bernhard Pfahringer, Geoff Holmes, and Richard Kirkby. Handling numeric attributes in
hoeffding trees. In PAKDD Pacific-Asia Conference on Knowledge Discovery and Data
Mining, pages 296–307, 2008.
M. Spiliopoulou, I. Ntoutsi, Y. Theodoridis, and R. Schult. MONIC: modeling and moni-
toring cluster transitions. In ACM KDD, pages 706–711, 2006.
Li Tu and Yixin Chen. Stream data clustering based on grid density and attraction. ACM
Trans. Knowl. Discov. Data, 3(3):1–27, 2009. ISSN 1556-4681. doi: http://doi.acm.org/
10.1145/1552303.1552305.
d on grid density and attraction. ACM
Trans. Knowl. Discov. Data, 3(3):1–27, 2009. ISSN 1556-4681. doi: http://doi.acm.org/
10.1145/1552303.1552305.
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!