博主最近转战语音增强研究,刚学习了最基础也是最成熟的方法——谱减法,最早是boll提出的《Suppression of acousic noise in speech using spectral subtraction》。http://blog.csdn.net/leixiaohua1020/article/details/47276353 链接中的这边博客给我帮助很大,比较详细,matlab源码也可以找到,对于刚入门音频处理的小白来讲,先从这边文献《Enhencement OF Speech Corrupted by Aconstic Noise》开始是不错的选择,要讲的源码也是对应这篇文献的。
一、原理
顾名思义,谱减法,就是用带噪信 的频谱减去噪声信 的频谱。谱减法基于一个简单的假设:假设语音中的噪声只有加性噪声,只要将带噪语音谱减去噪声谱,就可以得到纯净语音,这么做的前提是噪声信 是平稳的或者缓慢变化的。提出这个假设就是基于短时谱(25ms),就是频谱在短时间内是平稳不变的。
早期文献中的方法较为简单粗暴,公式如下:
为了改善这种情况,许多人都对传统的谱减法进行了改进,今天主要说的是 Berouti的改进方法,上个世纪的论文了《Enhencement OF Speech Corrupted by Aconstic Noise》。该方法将上面的公式进行了如下修改:
也就是alpha的不能为一个固定值,需要根据每一个音频帧的信噪比大小来确定合适的值。计算alpha的公式如下,其中1/s为斜率,alpha0位期望的SNR为0时的值:
至于还有其他的参数,比如说frameSize, windowOverlap, DFT order等直接去看原文献就可以。
二 、实现
下面说一下算法的代码流程(matlab实现,分步代码,完整代码请参见文章开始的链接)
1.读入语音数据,matlab有现成的函数,waveread()和audioread()都可以,不过waveread()函数将来会被移除。分通道进行处理。
3.因为要对语音进行分帧处理,所以需要生成汉明窗hamming window,并且取前5帧估计噪声。
5.更新噪声的估计
7. 输出最终去噪后的语音
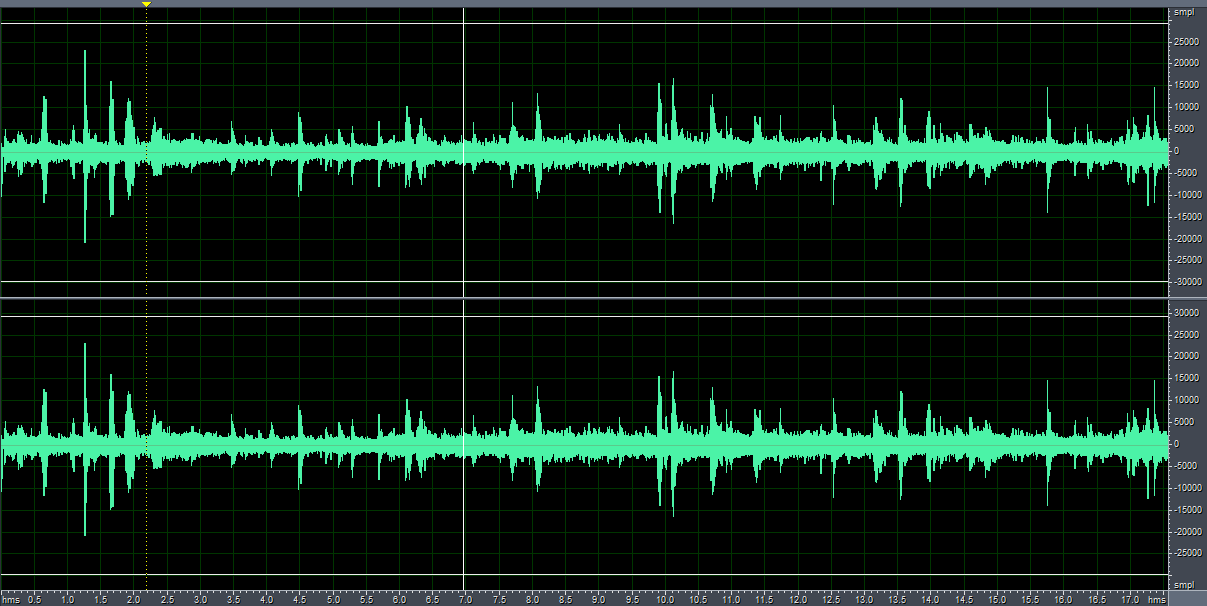
利用过减技术的谱减法去除噪音后的波形图,beta值不同,得到的宽带噪音和”音乐噪音“的比例也不同。
(1)beta=0.005,宽带噪音基本上被完全去除,但是“音乐噪声”很明显。
(3)beta=0.05,含有大量宽带噪音,去噪效果不明显,但是几乎没有”音乐噪音“

声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!