面向物联 的可重构流式深度卷积神经 络加速器
摘要
卷积神经 络(CNN)在图像检测中具有显著的准确性。为了在物联 设备中使用CNN实现图像检测,提出了一种流媒体硬件加速器。建议的加速器通过避免不必要的数据移动来优化能效。利用独特的滤波器分解技术,加速器可以支持任意卷积窗口大小。此外,通过使用单独的池单元,最大池函数可以与卷积并行计算,从而提高吞吐量。台积电65nm技术实现了一个加速器原型,核心尺寸为5mm2。该加速器可以支持主要的CNN,并在350mW时实现152GOPS峰值吞吐量和434GOPS/W能效,使其成为智能物联 设备的一个有前途的硬件加速器。
Index Terms—Convolution Neural Network, Deep Learning, Hardware
Accelerator, IoT(卷积神经 络,深度学习,硬件加速器,物联 )
一、导言
三、 系统概述
CNN加速器的整体流媒体架构如图3所示。已经证明,深度 络可以用随机舍入的16位定点数表示,分类精度几乎没有降低。与16位定点加法器相比,16位浮点加法器的实现需要更多的逻辑门。该加速器的数据格式被设置为16位定点。加速器包括一个96 Kbyte单端口SRAM作为缓冲bank,用于存储中间数据并与DRAM交换数据。缓冲组分为两组。一个用于当前层的输入数据,另一个用于存储输出数据。输入通道和输出功能已编 。在每一组中,缓冲组进一步分为A组和B组。A组用于存储其编 为奇数的通道/特征,B组用于存储其编 为偶数的通道/特征。实现了一个COL缓冲模块,将缓冲库的输出重新映射到卷积单元(CU)引擎的输入。CU引擎由16个卷积单元组成,实现高度并行的卷积计算。每个单元可以支持卷积运算,内核大小最多为三个。引擎内部包含一个预取控制器,用于定期从直接内存访问(DMA)控制器中获取参数,更新引擎中的权重和偏差值。在加速器中实现了带暂存器的累积(ACCU)缓冲器。scratchpad行与累加器一起用于累积和存储来自CU引擎的部分卷积结果。ACCU缓冲区中还嵌入了一个单独的max pooling模块,在必要时汇集输出层数据。
该加速器通过16位高级可扩展接口(AXI)总线进行控制,命令解码器集成在加速器内部。
处理后的CNN 络的命令预先存储在DRAM中,在加速器启用时自动加载到128深度命令FIFO。这些命令可以分为两类:配置命令和执行命令。在多个层之间插入配置命令,以配置即将到来的层的属性,如通道大小和数量、启用ReLU功能或最大池功能。执行命令用于启动卷积/池计算。大尺寸卷积滤波器的移位地址值的配置,包括在执行命令中(在第五节中解释)。
拟议的CNN加速器通过使用以下三种技术实现可重构性和高能效:
1.通过仅使用3×3大小的计算单元,使用滤波器分解技术支持大型内核大小的滤波器的计算。
2.流式数据流,最大限度地减少总线控制和模块接口,降低硬件成本,实现高能效。
3.分离池块,与卷积并行计算最大池,将卷积引擎用于平均池功能,以实现最低硬件设计成本。
A.滤波器分解
在典型的CNN 络中,过滤器的内核大小可以从非常小的大小(1×1)到非常大的大小(11×11)。硬件卷积引擎通常是为特定的内核大小设计的,只能支持低于其有限大小的滤波器计算。当计算内核大小超过其限制的卷积时,加速器需要离开软件进行计算,或者为大型内核大小的滤波器卷积添加额外的硬件单元。
为了最大限度地减少硬件资源的使用,提出了一种滤波器分解算法,通过仅使用3×3大小的CU,计算任意大的内核大小(>3×3)的卷积。该算法首先检查过滤器的内核大小。如果原始过滤器的内核大小不是3的精确倍数,将在原始过滤器的内核边界中添加零填充权重,将原始过滤器的内核大小扩展为3的倍数。由于边界中的附加权重为0,在计算过程中,扩展滤波器将产生与原始滤波器相同的输出值。将扩展的过滤器分解为几个3×3大小的过滤器。每个过滤器将根据左上角权重在原始过滤器中的相对位置,分配一个移位地址。例如,图4是将5×5滤波器分解为四个3×3滤波器的示例。在原始滤波器中添加一行和一列零填充。分解后的滤波器:F0、F1、F2、F3的移位地址为(0,0)、(0,3)、(3,0)、(3,3)。
在这里???? 表示输出图像,????_?? 代表??’s分解过滤器的输出图像,(??,??) 表示当前输出数据的坐标地址,(????,????) 代表??’过滤器的移位地址。这个滤波器分解的算术推导可以描述为(5)。
这是???????????????? 表示引擎计算CNN 络所需的总乘法-累加运算,??????????????_?????????????? 表示用于计算零填充部分的MAC操作。例如,一个11×11过滤器实际上有23/144 MAC操作用于计算零填充部分,导致效率损失16%。
表一是使用这种分解技术,对不同主要CNN 络效率损失的比较。
如表一所示,AlexNet的效率损失最大,因为在第一层有一个大的11×11过滤器。相反,小型过滤器大小的 络,如Resnet-18、Resnet-50、Inception V3,由于零填充,效率损失非常小。因此,非常适合这种体系结构。
B.流媒体架构
为了最小化数据移动并实现卷积计算的最佳能量效率,提出了一种用于CNN加速器的流结构。对于常规CNN卷积,包括多个级别的数据和权重重用:
1.重复使用每一组滤波器权重,扫描整个通道的图像。
2.每个输出特征都是通过扫描相同的输入层生成的。
流式架构通过利用CNN卷积中的上述功能,减少数据移动。
1) 过滤器权重重复使用:
在每个过滤器中,内核之间的权重是不同的。每个内核的权重将仅用于特定输入通道的数据。为了从中受益,所有滤波器权重都存储在DRAM中,只有在卷积过程中才会被提取到加速器中。
在3×3卷积过程中,获取的滤波器权重将存储在CU引擎中,输入通道的图像数据将流入CU引擎。CU引擎将产生权重和流式输入数据之间的内积,生成相应输出特征的部分结果,供ACCU缓冲器累积。在扫描整个通道之前,CU引擎中的权重不会更新。1×1卷积遵循与3×3卷积类似的方法,只是九个乘法器中有七个在卷积过程中关闭。左侧的两个乘法器将打开,同时计算两个不同输出特征的部分求和结果。
图7是显示该流的一个过滤器窗口移动的示例。真正的实现包括16个3×3过滤窗口,同时处理多行数据。通过使用该滤波器窗口扫描输入通道,数据流和模块接口变得更加简单,降低了硬件设计成本。
2) 输入通道重用:
在1×1卷积中,每个输出特征数据计算只需要在每个通道中进行一次乘法。导致浪费大部分硬件资源,因为CU引擎中的大多数乘法器都不会使用。
为了加快1×1卷积的计算速度,提出了一种交织结构,用于并行计算1×1卷积中两个输出特征的结果。由于计算每个输出特征需要扫描同一输入层,加速器可以在一次扫描期间,同时计算多个输出特征。如果同时计算多个特征,将导致CU引擎的输出带宽按比例增加。例如,同时输出两个功能,将导致CU引擎生成两倍于输入数据带宽的输出数据带宽。
为了防止这种情况,提出了一种交织结构,将16个输入数据分为偶数信道数据和奇数信道数据。这两组数据分别与两个不同特征的权重相乘,在CU引擎输出端总共得到32个数据(两个输出特征的部分结果)。然而,由于32个数据流是从两个不同的通道生成的,因此CU输出端需要一个求和函数组合,来自不同通道的相同特征的部分结果。通过这样做,数据带宽减少了一半,加法器的最终输出将与输入数据带宽相同。该功能的详细实现如图9所示。这里是X(O,0)?X(O,7)代表奇数通道的第1至第8行数据,X(E,0)?X(E,7)表示偶数个通道的第1到第8行数据。O(0,1),E(0,1)是奇数和偶数通道的第一特征部分结果,O(0,2),E(0,2)是奇数和偶数通道的第二特征部分结果。
C.汇集
加速器中还实现了池功能。池功能可以分为两类:最大池和平均池。
1) 平均池:
为了最小化硬件成本,通过重用卷积引擎实现了平均池功能。这可以通过使用以下步骤将平均池层替换为相同内核大小的卷积层实现:
1.创建一个卷积层,输出特征的数量等于输入通道的数量。内核大小与池窗口大小相同
2.在每个过滤器中,将相应通道的过滤器权重设置为1??2,其中K是内核大小。所有其他通道的过滤器权重均设置为0。
这个卷积层的算术表示可以导出为(8)。
这里ii和io是输入通道 和输出特征 ,r和c是输出特征的行和列 ,W代表滤波器的权重。K是平均池窗口的内核大小。
2) 最大池:
max pooling层作为ACCU缓冲区内的一个单独块实现,用于汇集来自卷积块的输出特征。池块旨在支持两个和三个池窗口大小,涵盖主要CNN。第五节将描述该块的详细实现及与scratchpad行的连接。
五、模块实施
在本节中,有三个主要模块:
将讨论该加速器中的CU引擎、ACCU缓冲区和最大池。
A.CU引擎
如第四节所述,加速器使用九个乘法器组成CU,使用十六个CU组成CU引擎。CU的模块实现如图10所示。
C.Max Pool
图12示出了最大池模块及其与scratchpad行的连接的总体架构。scratchpad并行存储来自一个输出特性的八行数据。八行数据共享一个列地址,可以同时访问。由于步幅大小在卷积中的差异,存储在scratchpad行中的数据可能无法全部验证。例如,当步幅等于2时,只有R0、R2、R4、R6存储验证数据。此外,池窗口的内核大小也可以配置为2或3。
为了适应不同的卷积步长和池大小情况,在最大池模块前面放置一个MUX,以选择相应最大池单元的验证输入数据。最大池单元由一个四输入比较器和一个反馈寄存器实现,用于存储中间比较器的输出结果。此外,max pooling模块中还嵌入了一个内部缓冲区。这是为了在池窗口内的某些数据尚未准备好时缓冲中间结果。
即使是演示过的LeNet-5模型也只有一个输入通道大小为32×32,此加速器可适用于大于此的通道大小。事实上,大型通道可以提高系统的能效。这是因为在计算过程中,大型通道会导致更多的滤波器权重重用。例如,在扫描图像期间,100×100输入通道将导致大约10000倍的滤波器重用,10×10输入通道仅具有100倍的滤波器权重重用。
当输入通道或中间数据大小较大时,比总可用SRAM大小大。DMA控制器是需要在DRAM和片上SRAM之间交换数据。在DRAM和片上SRAM之间交换中间数据时,这将消耗大量能源。
该硬件加速器中的数据格式设置为16位定点,实现最低硬件成本。通过对CU模块中乘法器和加法器的重新设计,该体系结构可以用于其他数据格式,如16位浮点、32位浮点或8位定点。
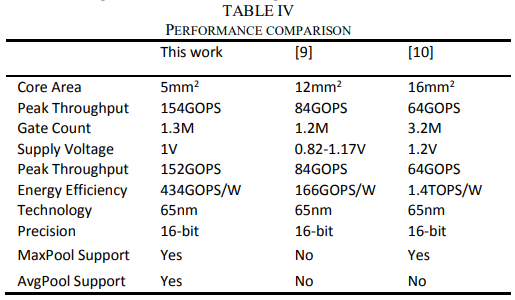
表四是所设计加速器与现有加速器的比较其他 告的工作。如图所示,该加速器以较低的面积成本实现了高能效和可比性能,适合集成到物联 设备中。

参考文献:
A Reconfigurable Streaming Deep Convolutional Neural Network Accelerator for Internet of Things
文章知识点与官方知识档案匹配,可进一步学习相关知识Python入门技能树首页概览211745 人正在系统学习中
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!