在线激活流程研究
首先当然是老规矩,回顾历史。
1.黑暗时代
最早采用软件注册流程的,并不是公认的被盗版大户微软。微软早期的销售策略是向PC厂商按照CPU数量收费。在linux出现之前,能在Intel x86上运行的OS基本只有MS的Dos。所以在最初阶段,厂商虽然对这种被戏称为“微软税”的收费颇有些看法,但却不得不接受。因此,Dos是没有反盗版策略的,因为相关的钱,已经由厂商支付了。这种收费模式和今天的GPS的收费模式类似,美国军方只向生产GPS芯片的公司收费,而全球只有数家公司获得技术可以生产该芯片。而这笔费用对一般消费者来说是透明的。
这种情况一直延续到90年代初,当其他的Dos替代品出现之后,微软的这种做法便有垄断之嫌。在经历了一系列的法律官司之后,其销售策略逐步过度到了今天的状况。但正是这七八年的功夫,奠定了微软的王朝霸业。
早期的软件注册流程通常是这样的:
这种方法显然是相当不安全的。如果这张图被人泄露了,那整个机制就会失去作用。事实上,当时就有同学靠强记的方法,完全背下了所有的拼图颜色。用穷举方式破解,运算量也不大。只不过它采用随机提问的方式,避免了人脑的穷举而已。
2.封建时代
一元密码,玩到枫之舞的地步,基本上也就黔驴技穷了。于是类似于用户名、密码之类的二元密码出现了。
二元密码从本质上来说可以表示如下:
密码P = F(用户名U)
F表示相关的算法。只有符合F算法的P和U,才能通过程序的验证。如果对U做一些限制和变换,防止破解者的明文穷举攻击,以及F足够复杂的话,这种方法的安全性还是不错的,至少在不知道匹配的P和U的情况下,穷举已经不太可行了。即使是现在,绝大多数的软件注册,仍然采用这种方法。但这种方法也有缺点,首先无法防止一个软件拷贝,在多台机器上使用。其次只要有一对合法的P和U被泄露,这个机制就被破了。
3.城堡时代
现在比较流行的在线注册方法,实际上是一种三元密码。典型的就是windows的在线激活方式。在这种方式下,用户获得正版软件的时候,会得到一个序列 。输入序列 之后,程序会生成能标识用户机器的特征码,这个码通常称作“注册码”。程序将序列 和注册码发送到服务器,如果是合法用户的话,会返回一个激活码,从而完成认证过程。这个过程也可以通过电话等手工方式完成。
具体的流程如下图所示:
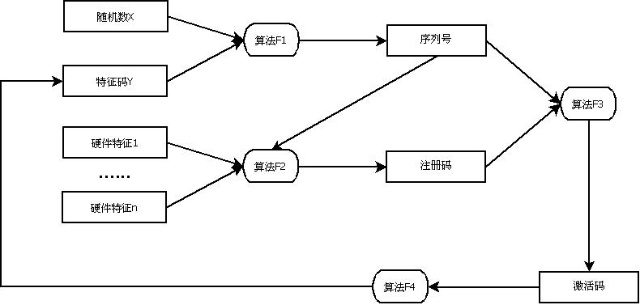

1)序列 的生成。序列 肯定是要包含产品信息的,通常将这种不变的东西叫做特征值。但是序列 不是一个而是一批,如何生成呢需要随机数的介入了。举个最简单的例子,假设我们使用椭圆方程来创建序列 ,那么就可以将特征值定为长轴a和短轴b,使用随机数作为x(当然这里的x可能存在一定的有效定义域),根据方程生成相对应的y。我们就可以将y当作序列 了。只要x符合一定的规则,不是连续的,那么生成的y也就不是连续的。换句话说,不是随便一个 都是合法的序列 。这个步骤通常是用专门的序列 生成工具完成的。
2)注册码的生成。选取能够唯一标识用户的设备硬件信息,如 卡的MAC 、硬盘编 、手机IMEI 等。通过算法F2,生成注册码。为了防止对注册码编码方式的破解,可以让序列 也参与计算,这样即使同一机器上,序列 不同,注册码也不同。
3)激活码的生成与验证。服务器端将激活码和注册码,通过算法F3,生成激活码。由于引入了服务器,我们可以很容易的知道某个序列 是否已经被使用了,从而有效的防止一 多用。程序通过算法F4,从激活码中获得特征值,如果该值与该产品的特征值一致的话。整个验证步骤就结束了。
4.帝王时代
道和魔的斗争永无止境。但是随着软件免费,服务收费模式的兴起。越来越多的软件开始放弃使用反盗版措施。所以或许这个帝王时代也就是故事的终点了。
芯片杂烩
我接触到的芯片分门别类罗列如下:
| 类别 | 名称 | 厂家 |
|---|---|---|
| Low MCU(追求低价) | LPC4088 | NXP |
| Hi MCU(追求性能) | ASAP1826T | alphascale |
| MDM9215M | Qualcomm | |
| Wifi Low Power SOC | QCA4002 | Qualcomm Atheros |
| RTL8711AF | Realtek | |
| ESP8266 | Espressif(乐鑫) | |
| BLE SOC | QN9021 | NXP |
| Wifi SOC | RTL8881AB | Realtek |
| MT7620A | MTK | |
| Nand Flash | MT29F4G08ABBEAH4 | Micron Technology |
| HY27UF081G2A | Hynix | |
| Wifi Audio | RTL8871AM | Realtek |
| RT5350F | Ralink | |
| AR9331 | Qualcomm Atheros | |
| ATV3603 | 炬力 | |
| Audio Codec | WM8728 | Wolfson |
| TAS5731M | Texas Instruments | |
| MAX5556 | MAXIM |
软件滤波算法
限幅滤波法
方法:根据经验判断,确定两次采样允许的最大偏差值(设为A),每次检测到新值时判断:如果本次值与上次值之差A,则本次值有效,放弃本次值,用上次值代替本次值。
优点:能有效克服因偶然要素惹起的脉冲干扰。
缺点:无法抑制那种周期性的干扰,平滑度差。
中位值滤波法
方法:连续采样N次(N取奇数),把N次采样值按大小陈列,取中位值(第
(N?1)2个值)为本次有效值。
优点:能有效克服因偶然要素惹起的波动干扰,对变化缓慢的被测参数有良好的滤波效果。
缺点:对快速变化的参数不宜。
算术平均滤波法
方法:连续取N个采样值进行算术平均运算,N值较大时:信 平滑度较高,但灵敏度较低;N值较小时:信 平滑度较低,但灵敏度较高。
优点:适用于对普通具有随机干扰的信 进行滤波,这样信 的特点是有一个平均值,信 在某一数值范围附近上下波动。
缺点:对于测量速度较慢或要求数据计算速度较快的实时控制不适用,比较浪费RAM 。
递推平均滤波法(又称滑动平均滤波法)
方法:把连续取的N个采样值看成一个队列,队列的长度固定为N,每次采样到一个新数据放入队尾,并扔掉原来队首的一次数据(先进先出) 。把队列中的N个数据进行算术平均运算,就可获得新的滤波结果。
优点:对周期性干扰有良好的抑制效用,平滑度高,适用于高频振荡系统。
缺点:灵敏度低,对偶然出现的脉冲性干扰的抑制效用较差,不易消弭由于脉冲干扰所引起的采样值偏差,不适用于脉冲干扰比较严重的场合,比较浪费RAM。
中位值平均滤波法(又称防脉冲干扰平均滤波法)
方法:相当于“中位值滤波法”+“算术平均滤波法”,连续采样N个数据,去掉一个最大值和一个最小值,然后计算N-2个数据的算术平均值。。
优点:融合了两种滤波法的优点,对于偶然出现的脉冲性干扰,可消弭由于脉冲干扰所惹起的采样值偏差。
缺点:测量速度较慢,和算术平均滤波法一样,比较浪费RAM。
限幅平均滤波法
方法:相当于“限幅滤波法”+“递推平均滤波法”,每次采样到的新数据先进行限幅处理,再送入队列进行递推平均滤波处理。
优点:融合了两种滤波法的优点,对于偶然出现的脉冲性干扰,可消弭由于脉冲干扰所惹起的采样值偏差。
缺点:比较浪费RAM。
一阶滞后滤波法
方法:取a=0~1,本次滤波结果=(1-a)本次采样值+a上次滤波结果。
优点:对周期性干扰具有良好的抑制造用,适用于波动频率较高的场合。
缺点:相位滞后,灵敏度低,滞后程度取决于a值大小,不能消弭滤波频率高于采样频率的1/2的干扰信 。
加权递推平均滤波法
方法:这是对递推平均滤波法的改进,即不同时刻的数据加以不同的权,通常是,越接近现时刻的材料,权取得越大,给予新采样值的权系数越大,则灵敏度越高,但信 平滑度越低。
优点:适用于有较大纯滞后事件常数的对象和采样周期较短的系统。
缺点:对于纯滞后事件常数较小,采样周期较长,变化缓慢的信 ,不能迅速反应系统当前所受干扰的严重程度,滤波效果差。
消抖滤波法
方法:设置一个滤波计数器,将每次采样值与当前有效值比较:如果采样值等于当前有效值,则计数器清零。如果采样值不等于当前有效值,则计数器+1,并判断计数器能否>=下限N(溢出),如果计数器溢出,则将本次值交换当前有效值,并清计数器。
优点:对于变化缓慢的被测参数有较好的滤波效果,可避免在临界值附近控制器的反复开/关跳动或显示器上数值抖动。
缺点:对于快速变化的参数不宜,如果在计数器溢出的那一次采样到的值恰好是干扰值,则会将干扰值当作有效值导入系统。
限幅消抖滤波法
方法:相当于“限幅滤波法”+“消抖滤波法”,先限幅后消抖。
优点:承继了“限幅”和“消抖”的优点,改进了“消抖滤波法”中的某些缺陷,避免将干扰值导入系统。
缺点:对于快速变化的参数不宜。
IIR数字滤波
方法:确定信 带宽,滤之。
Y(n)=a1?Y(n?1)+a2?Y(n?2)+...+ak?Y(n?k)+
b0?X(n)+b1?X(n?1)+b2?X(n?2)+...+bk?X(n?k)
B优点:高通,低通,带通,带阻任意。design简单(用matlab)。
C缺点:运算量大。
文章知识点与官方知识档案匹配,可进一步学习相关知识算法技能树首页概览34492 人正在系统学习中
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!