数据结构与算法
常见排序
内存管理与GC
- Python有一个私有堆空间来保存所有的对象和数据结构。作为开发者,我们无法访问它,是解释器在管理它。但是有了核心API后,我们可以访问一些工具。Python内存管理器控制内存分配。另外,内置垃圾回收器会回收使用所有的未使用内存,所以使其适用于堆空间。
- 内存管理机制:引用计数、垃圾回收、内存池。
- 引用计数:引用计数是一种非常高效的内存管理手段, 当一个 Python 对象被引用时其引用计数增加1, 当其不再被一个变量引用时则计数减 1. 当引用计数等于0时对象被删除。
- GC:
- 引用计数引用计数也是一种垃圾收集机制,而且也是一种最直观,最简单的垃圾收集技术。当 Python 的某个对象的引用计数降为 0 时,说明没有任何引用指向该对象,该对象就成为要被回收的垃圾了。比如某个新建对象,它被分配给某个引用,对象的引用计数变为 1。如果引用被删除,对象的引用计数为 0,那么该对象就可以被垃圾回收。不过如果出现循环引用的话,引用计数机制就不再起有效的作用了
- 标记清除如果两个对象的引用计数都为 1,但是仅仅存在他们之间的循环引用,那么这两个对象都是需要被回收的,也就是说,它们的引用计数虽然表现为非 0,但实际上有效的引用计数为 0。所以先将循环引用摘掉,就会得出这两个对象的有效计数。
- 分代回收从前面“标记-清除”这样的垃圾收集机制来看,这种垃圾收集机制所带来的额外操作实际上与系统中总的内存块的数量是相关的,当需要回收的内存块越多时,垃圾检测带来的额外操作就越多,而垃圾回收带来的额外操作就越少;反之,当需回收的内存块越少时,垃圾检测就将比垃圾回收带来更少的额外操作。
- 内存池:
- Python 的内存机制呈现金字塔形状,-1,-2 层主要由操作系统进行操作;
- 第 0 层是 C 中的 malloc,free 等内存分配和释放函数进行操作;
- 第1 层和第 2 层是内存池,有 Python 的接口函数 PyMem_Malloc 函数实现,当对象小于 256K 时有该层直接分配内存;
- 第3层是最上层,也就是我们对 Python 对象的直接操作;Python 在运行期间会大量地执行 malloc 和 free 的操作,频繁地在用户态和核心态之间进行切换,这将严重影响 Python 的执行效率。为了加速Python 的执行效率,Python 引入了一个内存池机制,用于管理对小块内存的申请和释放。
- Python 内部默认的小块内存与大块内存的分界点定在 256 个字节,当申请的内存小于 256 字节时,PyObject_Malloc会在内存池中申请内存;当申请的内存大于 256 字节时,PyObject_Malloc 的行为将蜕化为 malloc 的行为。当然,通过修改 Python 源代码,我们可以改变这个默认值,从而改变 Python 的默认内存管理行为。
- 调优手段:
- 1.手动垃圾回收
- 2.调高垃圾回收阈值
- 3.避免循环引用(手动解循环引用和使用弱引用)
*args,**kwargs
- 当函数的参数前面有一个星 * 的时候表示这是一个可变的位置参数,两个星 表示这个是一个可变的关键词参数。一个星 把序列或者集合解包(unpack)成位置参数,两个星 把字典解包成关键词参数。
- 可迭代对象前放一个星 能解包该对象内的所有参数
- 两个星 能解包字典,将关键字与函数参数进行匹配
装饰器
- 装饰器本质上是一个高级Python函数,它可以让其它函数在不作任何变动的情况下增加额外功能,装饰器的返回值也是一个函数对象。它经常用于有切面需求的场景。比如:插入日志、性能测试、事务处理、缓存、权限校验等。有了装饰器我们就可以抽离出大量的与函数功能无关的雷同代码进行重用。
多线程
- 在Python多线程下,每个线程的执行方式:
1.获取GIL
2.执行代码直到sleep或者是python虚拟机将其挂起。
3.释放GIL - 经过GIL的处理,会增加执行的开销。这就意味着如果你先要提高代码执行效率,使用threading不是一个明智的选择,当然如果你的代码是IO密集型,多线程可以明显提高效率,相反如果你的代码是CPU密集型的这种情况下多线程大部分是鸡肋。
- 在我的爬虫项目中代码显然是是IO密集型的(每一个 页对应一个爬取模型的对象),同时使用threading模块的lock保证插入顺序的正常。
- ulimit -s 返回线程栈大小,默认是8192, 用内存大小除以线程栈大小就得到理论上的线程数
_thread.stack_size([size])
- 返回新建线程时使用的堆栈大小。可选参数 size 指定之后新建的线程的堆栈大小,而且一定要是0(根据平台或者默认配置)或者最小是32,768(32KiB)的一个正整数。如果size没有指定,默认是0。如果不支持改变线程堆栈大小,会抛出 RuntimeError 错误。如果指定的堆栈大小不合法,会抛出 ValueError 错误并且不会修改堆栈大小。32KiB是当前最小的能保证解释器足够堆栈空间的堆栈大小。需要注意的是部分平台对于堆栈大小会有特定的限制,例如要求大于32KiB的堆栈大小或者需要根据系统内存页面的整数倍进行分配 – 应当查阅平台文档有关详细信息(4KiB页面比较普遍,在没有更具体信息的情况下,建议的方法是使用4096的倍数作为堆栈大小)
- 可用性: Windows,具有 POSIX 线程的系统。
线程安全
Python线程安全
- 线程不安全:我们的操作不是原子操作,才会导致的线程不安全。
- 比如counter+=1,对于这样的操作其实写作number=number+1,也就是包含取值,运算,赋值三步 ;这样就导致多个线程同时读取时,有可能读取到同一个 number 值,读取两次,却只加了一次,最终导致自增的次数小于预期。
- 原子操作
- 原子操作(atomic operation),指不会被线程调度机制打断的操作,这种操作一旦开始,就一直运行到结束,中间不会切换到其他线程。它有点类似数据库中的 事务。
- 实现人工原子操作
- 在多线程下,我们并不能保证我们的代码都具有原子性,因此如何让我们的代码变得具有 “原子性” ,就是一件很重要的事。
- 方法也很简单,就是当你在访问一个多线程间共享的资源时,加锁可以实现类似原子操作的效果,一个代码要嘛不执行,执行了的话就要执行完毕,才能接受线程的调度。
- 因此,我们使用加锁的方法,对例子一进行一些修改,使其具备原子性。
- 为什么 Queue 是线程安全的
- 其根本原因就是 Queue 实现了锁原语,因此他能像第三节那样实现人工原子操作。
GIL和线程安全
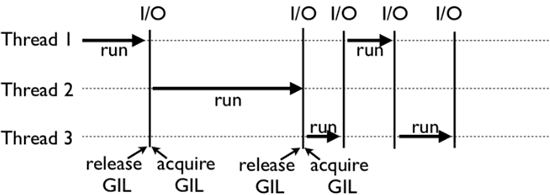

- Python GIL底层实现原理
- 上面这张图,就是 GIL 在 Python 程序的工作示例。其中,Thread 1、2、3 轮流执行,每一个线程在开始执行时,都会锁住 GIL,以阻止别的线程执行;同样的,每一个线程执行完一段后,会释放 GIL,以允许别的线程开始利用资源。
- 为什么 Python 线程会去主动释放 GIL 呢果仅仅要求 Python 线程在开始执行时锁住 GIL,且永远不去释放 GIL,那别的线程就都没有运行的机会。CPython 中还有另一个机制,叫做间隔式检查(check_interval), CPython 解释器会去轮询检查线程 GIL 的锁住情况,每隔一段时间,Python 解释器就会强制当前线程去释放 GIL,这样别的线程才能有执行的机会。
- 注意,不同版本的 Python,其间隔式检查的实现方式并不一样。早期的 Python 是 100 个刻度(大致对应了 1000 个字节码);而 Python 3 以后,间隔时间大致为 15 毫秒。当然,我们不必细究具体多久会强制释放 GIL,读者只需要明白,CPython 解释器会在一个“合理”的时间范围内释放 GIL 就可以了。
- Python GIL不能绝对保证线程安全
- 注意,有了 GIL,并不意味着 Python 程序员就不用去考虑线程安全了,因为即便 GIL 仅允许一个 Python 线程执行,但别忘了 Python 还有 check interval 这样的抢占机制。所以这就是上面提到的原语/锁机制所解决的问题。
os和sys模块
- os模板提供了一种方便的使用操作系统函数的方法
- sys模板可供访问由解释器使用或维护的变量和与解释器交互的函数
lambda表达式
- lambda表达式通常是当你需要使用一个函数,但是又不想费脑袋去命名一个函数的时候使用,也就是通常所说的匿名函数。
- 和c++内联函数的区别:内联函数是预编译的,lambda只是匿名函数
拷贝
- Python中对象之间的赋值是按引用传递的,如果要拷贝对象需要使用标准模板中的copy
- copy.copy:浅拷贝,只拷贝父对象,不拷贝父对象的子对象。
- copy.deepcopy:深拷贝,拷贝父对象和子对象。
- 如 [obj1,obj2] 若为浅拷贝,则拷贝的list对象是新建的,但是其中的obj1和obj2却还是指向原来的对象
dict:映射、字典、散列表
- dict采用了哈希表,最低能在 O(1)时间内完成搜索。
- 同样的java的HashMap也是采用了哈希表实现,不同是dict在发生哈希冲突的时候采用了开放寻址法,而HashMap采用了链接法。
- 鉴于Python没有内置case语句,使用字典实现也是不错的选择。
- MappingProxyType创建只读字典视图
迭代器,生成器
- 迭代器:
- 迭代器是一个可以记住遍历的位置的对象。
- 迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
- 迭代器有两个基本的方法:iter() 和 next()。
- 在 Python 中,使用了 yield 的函数被称为生成器(generator)。
- 跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
- 在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行next() 方法时从当前位置继续运行。
- 调用一个生成器函数,返回的是一个迭代器对象。
词法闭包
- 函数中的内部函数可以捕捉并且携带父函数的某些状态
- 闭包在程序流不在闭包范围内的情况下,记住封闭作用域内的值
代码部分
lambda表达式运用
- 排序列表中的字典,排序依据是某个键对应的值
装饰器实现一个函数缓存
- functools
- lru_cache实现LRU缓存
- functools.wraps,wraps本身也是一个装饰器,它能把原函数的元信息拷贝到装饰器里面的 func 函数中,这使得装饰器里面的 func 函数也有和原函数 foo 一样的元信息了。
- 使用warps保存元数据,更细致的实现
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!