文章目录
-
- 告警的选型
-
- 告警需求
-
- 告警的对接
- 告警的收敛
- 告警的可用性
- 告警的选型
-
- 备选方案
- 方案对比
- Alertmanager的实现
-
- 对接
- 收敛
-
- 分组的支持
- 告警的抑制
- 静默
- 告警的延时
- 配置
- 可用性
- Alertmanager的实践
-
- 架构
- 调度层级
- SRE
-
- 第一点建议
- 第二点建议
告警的选型
大多数告警通过监控系统发出,有部分告警可以通过服务直接发出,所以我们希望支持多样的告警源。对于多样告警目标,不同公司可能用的办公软件都不一样,有的公司用微信进行通讯,有的公司通过钉钉进行接收消息,而客户希望我们把告警发到他们聊天工具中去。不同人员的需求也不同,运维人员习惯通过短信接收告警,大BOSS更喜欢用邮件接收告警,所以我们告警对接需要解决的第二个问题是多样的告警目标。
告警的收敛
接下来看告警可用性需要解决什么样的问题。前面我们说过我们不希望背锅,所以我们必须要实现告警系统的高可用。
关于第二个隔离的故障域,有的监控系统和告警系统绑定在一起,如果监控系统挂掉,告警系统同样挂掉,所以我们希望监控系统和告警系统是分开部署的。
下面我们将针对这三个方面的需求,来进行方案选型。
告警的选型
备选方案
我们从市面上调研了一些监控系统,其中比较流行的是Prometheus、Open-falcon、Zabbix。根据自身需求对这三个监控系统进行对比,首先我们进行对接方面的对比。这三个系统它们都可以支持多通道的告警源,同时可以支持多通道的告警目标,所以在这个需求上面,这三个方案都是满足的。
第三个需求方面的支持。首先是Zabbix,监控系统和告警系统绑定在一起,所以它的故障域很大。Open-falcon和Prometheus,其监控系统和告警系统都可以单独的部署,所以它的故障域相对来说要小,但是Open-falcon所有的组件都支持高可用,除了它的告警系统以外,这一点是比较遗憾的。
然后我们还考量了一些其他的方面:
Alertmanager的实现
下面为大家介绍告警系统Alertmanager的实现。
在介绍实现的时候,首先介绍一下它的架构。然后针对我们前面提到的三点需求对接、收敛和可用性来介绍它的实现,中间可能会穿插一点它的配置。
**其次,中间的流程,**Alertmanager收到告警之后会将告警进行分组,每一个分组都会有进行抑制和静默过程,下面还会进行去重,所以它的收敛方式非常的丰富。
对接方面的需求,首先对接需要接收不同的告警源发送的告警。比如我们用监控系统Prometheus,也有可能我们自己的服务也会发送 警。同时客户希望将不同的告警发往不同的接收者,所以我们在对Alertmanager收敛之后,把告警发到不同的接收者上面去。
接下来我们看一下Alertmanager关于收敛的支持,Alertmanager收敛提供四种方式:
-
分组
-
抑制
-
静默
-
延时
分组的支持
假设有一台主机挂掉了,上面运行着MySQL的服务,这个时候主机挂掉和MySQL挂掉的两条告警到达Alertmanager的顺序可能不一样,运维人员接收的告警顺序也可能不一样。如果先收到MySQL服务挂掉的告警,排查问题的思路可能就往别的方向走了,但是实际上这不是最根本的原因,所以我们可以通过抑制,将主机挂掉的告警把这主机上面MySQL服务挂掉告警抑制掉,最后只收到主机挂掉的告警。这样能够把冗余信息消除掉,最后得到故障发生最本质的原因。
这是一个具体的例子,这个例子和上面讲的是类似的。假设MySQL服务器A上面运行着MySQL服务,当这台服务器突然宕机时候,这两条告警都会出来,但是你配置一条抑制规则,抑制掉MySQL的告警,最后收到服务器挂掉的告警。
静默
假设系统发生故障产生告警,每分钟发送一条告警消息,这样的告警信息十分令人崩溃。Alertmanager提供第一个参数是repeat interval,可以将重复的告警以更大频率发送,但是只有这个参数会带来两个的问题。第一个问题是告警不能及时收到。假设当前发送一条告警,下一次告警在一个小时之后,但在这一个小时之内系统产生了一条告警,这时告警无法被及时发出去。所以alertmanager提供了第二个参数group inteval,让 警能够及时的发送出去。
另一个问题,当故障发生时,告警条件一个个被满足,到达Alertmanager的顺序也分先后,所以在最开始的时候可能收到多个消息。Alertmanager提供了第三个参数叫做group wait,在一个分组收到第一条 警消息之后,通过等到group wait,把故障最开始发生时候产生告警收敛掉,最后作为一条消息发送出来。
配置
这一小节将介绍Alertmanager高可用的实现方式。在Prometheus项目的官方介绍中,Alertmanager是单独部署的,每一个Alertmanager它都单独接收来自Prometheus的告警,然后单独的将告警进行收敛,最后发送出去。但是会有一个问题,不同的Alertmanager实例可能会发送相同的告警。所以在每一个Alertmanager发送告警之前,它通过Gossip协议去其他实例获取当前已经有哪些告警发送出去,如果当前想发送的告警已经发送出去了,就不会再发送,从而避免多个Alertmanager发送同一个告警的问题。
Alertmanager的实践
下面我给大家介绍一下我们的实践经验,首先我会给大家介绍我们的架构,然后是我们的调度层级,最后我们会介绍一些关于SRE的问题。
-
架 构
-
调度层级
-
SRE
架构
接下来看我们调度层级,我们使用的是经典的error kernel模型,比如我们的MySQL实例,上面是监控客户端,监控客户端定期去MySQL实例采集数据。再上面是我们监控管理端,监控管理端定期从监控客户端拉取数据,从而进行规则判定。如果它发送告警,会往上一层Alertmanager发送。
我们并没有采用Alertmanager本身提供的高可用实现方式。因为在我们选型的时候,这个组件还处于活跃的开发状态,当时它的高可用并不是那么的可靠,所以我们把Alertmanager和Consul联合在一起,它实现了Raft协议,我们通过Raft一致性协议来保证Alertmanager高可用。
同时我们也实现了反向告警的机制。通常运维人员收到一条告警时候,系统一定出现一个故障,运维人员需要采取动作。但是运维人员收到反向告警不需要采取什么措施。因为收到一条反向告警,意味着整个集群正常工作,如果整个集群都不能正常工作反向告警是发不出来的。
SRE
接下来我们讲一讲SRE。SRE是谷歌的站点可靠性工程,它对监控系统提出了两点建议。
我们下一个实践的经验是发送notice级别的告警,这一点也没有遵循它的建议。因为按照它的建议不需要运维人员介入的告警不需要发送给运维人员。但是我们需要知道系统发生了这样一种状况,并且知道发生状况的原因是什么,所以我们增加了notice级别的告警。
/p>
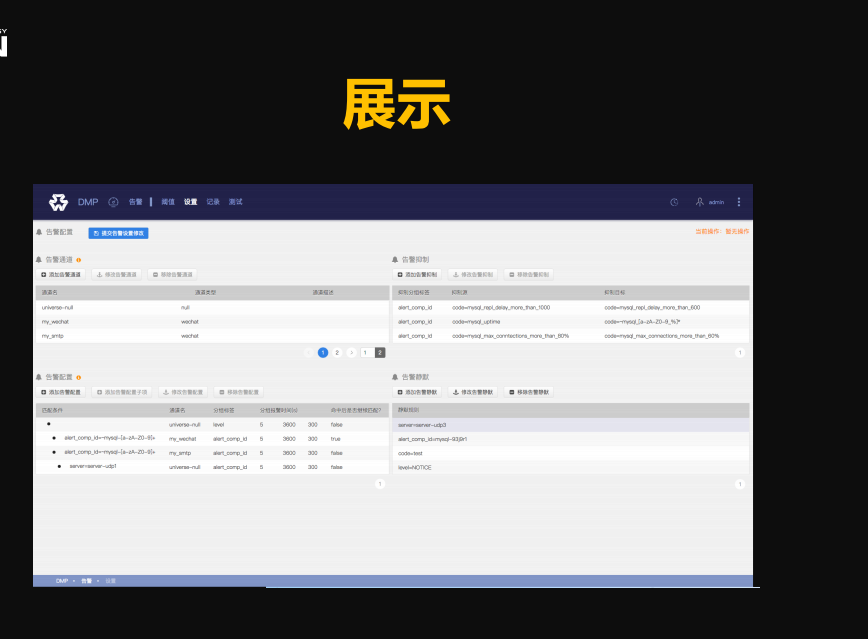
下面是我们的告警展示,这是我们自己的实践。

文章知识点与官方知识档案匹配,可进一步学习相关知识云原生入门技能树首页概览8665 人正在系统学习中
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!