图
图的存储、拓扑排序、最短路径、关键路径、最小生成树、二分图、最大流
30 | 图的表示:如何存储微博、微信等 交 络中的好友关系/h3>
另一种非线性表数据结构,图
我们就拿微信举例子吧。我们可以把每个用户看作一个顶点。如果两个用户之间互加好友,那就在两者之间建立一条边。所以,整个微信的好友关系就可以用一张图来表示。其中,每个用户有多少个好友,对应到图中,就叫作顶点的度(degree),就是跟顶点相连接的边的条数。
微博的 交关系跟微信还有点不一样,或者说更加复杂一点。微博允许单向关注,也就是说,用户 A 关注了用户 B,但用户 B 可以不关注用户 A。那我们如何用图来表示这种单向的 交关系呢/p>
对应到微博的例子,入度就表示有多少粉丝,出度就表示关注了多少人。
前面讲到了微信、微博、无向图、有向图,现在我们再来看另一种 交软件:QQ。
带权图(weighted graph)。在带权图中,每条边都有一个权重(weight),我们可以通过这个权重来表示 QQ 好友间的亲密度。
邻接矩阵存储方法
- 每个顶点对应一条链表,链表中存储的是与这个顶点相连接的其他顶点。
- 有向图的邻接表存储方式,每个顶点对应的链表里面,存储的是指向的顶点。
- 对于无向图来说,每个顶点的链表中存储的,是跟这个顶点有边相连的顶点。
邻接矩阵与邻接表
- 邻接矩阵存储起来比较浪费空间,但是使用起来比较节省时间。相反,邻接表存储起来比较节省空间,但是使用起来就比较耗时间。
- 链表的存储方式对缓存不友好。所以,比起邻接矩阵的存储方式,在邻接表中查询两个顶点之间的关系就没那么高效了。
改进升级版
在散列表那几节里,我讲到,在基于链表法解决冲突的散列表中,如果链过长,为了提高查找效率,我们可以将链表换成其他更加高效的数据结构,比如平衡二叉查找树等。我们刚刚也讲到,邻接表长得很像散列。所以,我们也可以将邻接表同散列表一样进行“改进升级”。
我们可以将邻接表中的链表改成平衡二叉查找树。实际开发中,我们可以选择用红黑树。这样,我们就可以更加快速地查找两个顶点之间是否存在边了。当然,这里的二叉查找树可以换成其他动态数据结构,比如跳表、散列表等。除此之外,我们还可以将链表改成有序动态数组,可以通过二分查找的方法来快速定位两个顶点之间否是存在边。
邻接矩阵存储方法的缺点是比较浪费空间,但是优点是查询效率高,而且方便矩阵运算。邻接表存储方法中每个顶点都对应一个链表,存储与其相连接的其他顶点。尽管邻接表的存储方式比较节省存储空间,但链表不方便查找,所以查询效率没有邻接矩阵存储方式高。针对这个问题,针对这个问题,邻接表还有改进升级版,即将链表换成更加高效的动态数据结构,比如平衡二叉查找树、跳表、散列表等。
如何存储微博、微信等 交 络中的好友关系/p>
数据结构是为算法服务的,所以具体选择哪种存储方法,与期望支持的操作有关系。针对微博用户关系,假设我们需要支持下面这样几个操作:
- 判断用户 A 是否关注了用户 B;
- 判断用户 A 是否是用户 B 的粉丝;
- 用户 A 关注用户 B;
- 用户 A 取消关注用户 B;
- 根据用户名称的首字母排序,分页获取用户的粉丝列表;
- 根据用户名称的首字母排序,分页获取用户的关注列表。
关于如何存储一个图,前面我们讲到两种主要的存储方法,邻接矩阵和邻接表。因为 交 络是一张稀疏图,使用邻接矩阵存储比较浪费存储空间。所以,这里我们采用邻接表来存储。
不过,用一个邻接表来存储这种有向图是不够的。我们去查找某个用户关注了哪些用户非常容易,但是如果要想知道某个用户都被哪些用户关注了,也就是用户的粉丝列表,是非常困难的。
基于此,我们需要一个逆邻接表。邻接表中存储了用户的关注关系,逆邻接表中存储的是用户的被关注关系。对应到图上,邻接表中,每个顶点的链表中,存储的是指向这个顶点的顶点。如果要查找某个用户关注了哪些用户,我们可以在邻接表中查找;如果要查找某个用户被哪些用户关注了,我们从逆邻接表中查找。
除此之外,我们还有另外一种解决思路,就是利用外部存储(比如硬盘),因为外部存储的存储空间要比内存会宽裕很多。数据库是我们经常用来持久化存储关系数据的,所以我这里介绍一种数据库的存储方式。
我用下面这张表来存储这样一个图。为了高效地支持前面定义的操作,我们可以在表上建立多个索引,比如第一列、第二列,给这两列都建立索引。
设有两个顶点集合 S 和 T,集合 S 中存放图中已找到最短路径的顶点,集合 T 存放图中剩余顶点。初始状态时,集合 S 中只包含源点 v0,然后不断从集合 T 中选取顶点 v0 路径长度最短的顶点 vu 并入到集合 S 中。集合 S 每并入一个新顶点 vu,都要修改顶点 v0 到集合 T 中顶点的最短路径长度值。不断重复此过程,直到集合 T 的顶点全部并入到 S 中为止。
时间复杂度就是 O(E*logV)。E 表示边的个数,V 表示顶点的个数
Dijkstra实际上可以看做动态规划
- 如何计算最优出行路线/li>
从理论上讲,用 Dijkstra 算法可以计算出两点之间的最短路径。但是,你有没有想过,对于一个超级大地图来说,岔路口、道路都非常多,对应到图这种数据结构上来说,就有非常多的顶点和边。如果为了计算两点之间的最短路径,在一个超级大图上动用 Dijkstra 算法,遍历所有的顶点和边,显然会非常耗时。那我们有没有什么优化的方法呢/p>
对于软件开发工程师来说,我们经常要根据问题的实际背景,对解决方案权衡取舍。类似出行路线这种工程上的问题,我们没有必要非得求出个绝对最优解。很多时候,为了兼顾执行效率,我们只需要计算出一个可行的次优解就可以了
- 对工程问题,求出可行的次优解
虽然地图很大,但是两点之间的最短路径或者说较好的出行路径,并不会很“发散”,只会出现在两点之间和两点附近的区块内。所以我们可以在整个大地图上,划出一个小的区块,这个小区块恰好可以覆盖住两个点,但又不会很大。我们只需要在这个小区块内部运行 Dijkstra 算法,这样就可以避免遍历整个大图,也就大大提高了执行效率。
不过你可能会说了,如果两点距离比较远,从北京海淀区某个地点,到上海黄浦区某个地点,那上面的这种处理方法,显然就不工作了,毕竟覆盖北京和上海的区块并不小。
对于这样两点之间距离较远的路线规划,我们可以把北京海淀区或者北京看作一个顶点,把上海黄浦区或者上海看作一个顶点,先规划大的出行路线。比如,如何从北京到上海,必须要经过某几个顶点,或者某几条干道,然后再细化每个阶段的小路线。
- 最少时间
前面讲最短路径的时候,每条边的权重是路的长度。在计算最少时间的时候,算法还是不变,我们只需要把边的权重,从路的长度变成经过这段路所需要的时间。不过,这个时间会根据拥堵情况时刻变化。如何计算车通过一段路的时间呢是一个蛮有意思的问题,你可以自己思考下。
- 最少红绿灯
每经过一条边,就要经过一个红绿灯。关于最少红绿灯的出行方案,实际上,我们只需要把每条边的权值改为 1 即可,算法还是不变,可以继续使用前面讲的 Dijkstra 算法。不过,边的权值为 1,也就相当于无权图了,我们还可以使用之前讲过的广度优先搜索算法。因为我们前面讲过,广度优先搜索算法计算出来的两点之间的路径,就是两点的最短路径。
不过,这里给出的所有方案都非常粗糙,只是为了给你展示,如何结合实际的场景,灵活地应用算法,让算法为我们所用,真实的地图软件的路径规划,要比这个复杂很多。而且,比起 Dijkstra 算法,地图软件用的更多的是类似 A 的启发式搜索算法*,不过也是在 Dijkstra 算法上的优化罢了,我们后面会讲到,这里暂且不展开。
翻译句子
我们有一个翻译系统,只能针对单个词来做翻译。如果要翻译一整个句子,我们需要将句子拆成一个一个的单词,再丢给翻译系统。针对每个单词,翻译系统会返回一组可选的翻译列表,并且针对每个翻译打一个分,表示这个翻译的可信程度。
当然,最简单的办法还是借助回溯算法,穷举所有的排列组合情况,然后选出得分最高的前 k 个翻译结果。但是,这样做的时间复杂度会比较高,是 O(m^n),其中,m 表示平均每个单词的可选翻译个数,n 表示一个句子中包含多少个单词。
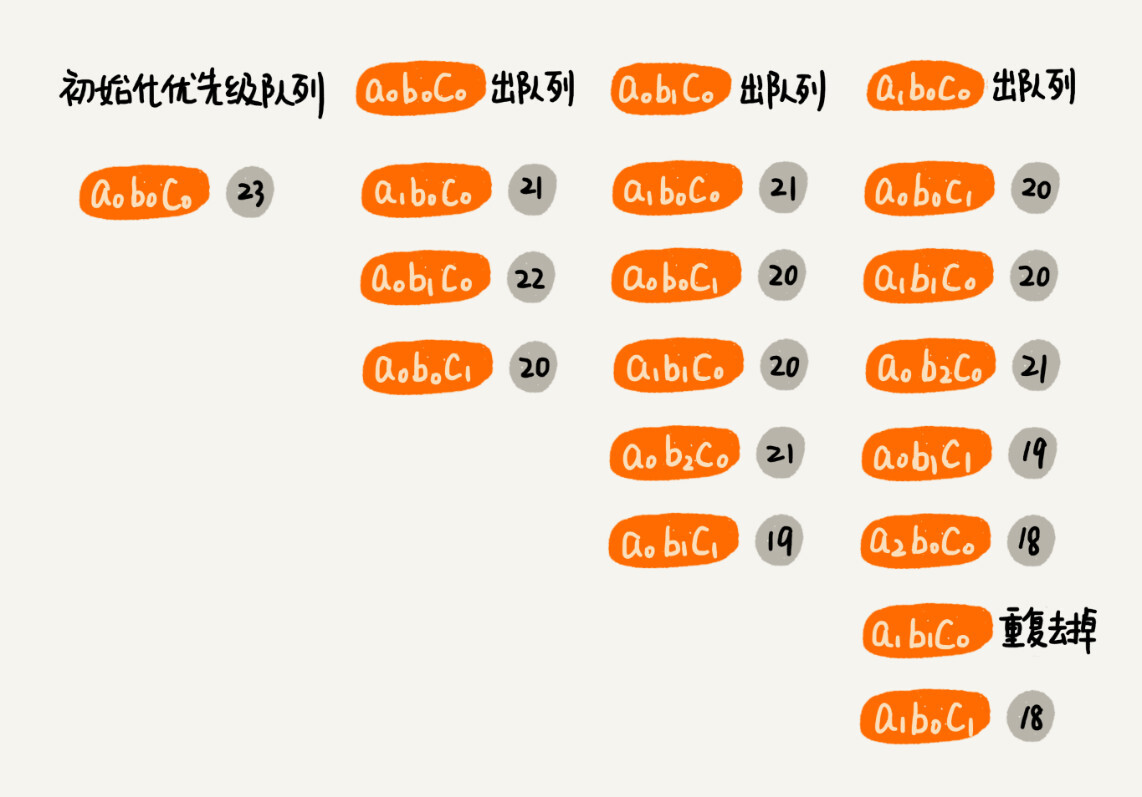
实际上,这个问题可以借助 Dijkstra 算法的核心思想,非常高效地解决。每个单词的可选翻译是按照分数从大到小排列的,所以 a0b0c0 肯定是得分最高组合结果。我们把 a0b0c0 及得分作为一个对象,放入到优先级队列中。
我们每次从优先级队列中取出一个得分最高的组合,并基于这个组合进行扩展。扩展的策略是每个单词的翻译分别替换成下一个单词的翻译。比如
a0b0c0 扩展后,会得到三个组合,a1b0c0 、a0b1c0 、a0b0c1 。我们把扩展之后的组合,加到优先级队列中。重复这个过程,直到获取到 k 个翻译组合或者队列为空。

时间复杂度:O(knlog(k*n)),n个单词,k个组合
思考
1、在计算最短时间的出行路线中,如何获得通过某条路的时间呢个题目很有意思,我之前面试的时候也被问到过,你可以思考看看。
答:获取通过某条路的时间:通过某条路的时间与①路长度②路况(是否平坦等)③拥堵情况④红绿灯个数等因素相关。获取这些因素后就可以建立一个回归模型(比如线性回归)来估算时间。其中①②④因素比较固定,容易获得。③是动态的,但也可以通过a.与交通部门合作获得路段拥堵情况;b.联合其他导航软件获得在该路段的在线人数;c.通过现在时间段正好在次路段的其他用户的真实情况等方式估算。
2、今天讲的出行路线问题,我假设的是开车出行,那如果是公交出行呢果混合地铁、公交、步行,又该如何规划路线呢/p>
答:混合公交、地铁和步行时:地铁时刻表是固定的,容易估算。公交虽然没那么准时,大致时间是可以估计的,步行时间受路拥堵状况小,基本与道路长度成正比,也容易估算。总之,感觉公交、地铁、步行,时间估算会比开车更容易,也更准确些。
文章知识点与官方知识档案匹配,可进一步学习相关知识算法技能树首页概览34503 人正在系统学习中
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!