一、架构原理
1.1 基本架构
客户端要访问HBase中的数据,只需要知道Zookeeper集群的连接信息,访问步骤如下:
- 客户端将从Zookeeper(/hbase/meta-region-server)获得 hbase:meta 表存储在哪个RegionServer,缓存该位置信息
- 查询该RegionServer上的 hbase:meta 表数据,查找要操作的 rowkey所在的Region存储在哪个RegionServer中,缓存该位置信息
- 在具体的RegionServer上根据rowkey检索该Region数据
可以看到,客户端操作数据过程并不需要HMaster的参与,通过Zookeeper间接访问RegionServer来操作数据。
第一次请求将会产生3次RPC,之后使用相同的rowkey时客户端将直接使用缓存下来的位置信息,直接访问RegionServer,直至缓存失效(Region失效、迁移等原因)。
通过Zookeeper的读写流程如下:
- Rowkey格式:tableName,regionStartKey,regionId
- 第一个region的regionStartKey为空
- 示例:ns1:testTable,xxxxreigonid
- 只有一个列族info,包含三个列:
- regioninfo:RegionInfo的proto序列化格式,包含regionId,tableName,startKey,endKey,offline,split,replicaId等信息
- server:RegionServer对应的server:port
- serverstartcode:RegionServer的启动时间戳
简单总结Zookeeper在HBase集群中的作用如下:
- 对于服务端,是实现集群协调与控制的重要依赖。
- 对于客户端,是查询与操作数据必不可少的一部分。
HMaster
BlockCache
BlockCache为RegionServer中的 读缓存,一个RegionServer共用一个BlockCache。
RegionServer处理客户端读请求的过程:
BlockCache有两种实现方式,有不同的应用场景,各有优劣:
-
On-Heap的LRUBlockCache
- 优点:直接中Java堆内内存获取,响应速度快
- 缺陷:容易受GC影响,响应延迟不稳定,特别是在堆内存巨大的情况下
- 适用于:写多读少型、小内存等场景
-
Off-Heap的BucketCache
- 优点:无GC影响,延迟稳定
- 缺陷:从堆外内存获取数据,性能略差于堆内内存
- 适用于:读多写少型、大内存等场景
我们将在「性能优化」一节中具体讨论如何判断应该使用哪种内存模式。
WAL
全称 Write Ahead Log ,是 RegionServer 中的预写日志。
所有写入数据默认情况下都会先写入WAL中,以保证RegionServer宕机重启之后可以通过WAL来恢复数据,一个RegionServer中共用一个WAL。
RegionServer的写流程如下:
WAL会通过 日志滚动 的操作定期对日志文件进行清理(已写入HFile中的数据可以清除),对应HDFS上的存储路径为 /hbase/WALs/${HRegionServer_Name} 。
Region
一个Table由一个或者多个Region组成,一个Region中可以看成是Table按行切分且有序的数据块,每个Region都有自身的StartKey、EndKey。
一个Region由一个或者多个Store组成,每个Store存储该Table对应Region中一个列簇的数据,相同列簇的列存储在同一个Store中。
同一个Table的Region会分布在集群中不同的RegionServer上以实现读写请求的负载均衡。故,一个RegionServer中将会存储来自不同Table的N多个Region。
Store、Region与Table的关系可以表述如下:多个Store(列簇)组成Region,多个Region(行数据块)组成完整的Table。
其中,Store由Memstore(内存)、StoreFile(磁盘)两部分组成。
在RegionServer中,Memstore可以看成指定Table、Region、Store的写缓存(正如BlockCache小节中所述,Memstore还承载了一些读缓存的功能),以RowKey、Column Family、Column、Timestamp进行排序。如下图所示:
ROW:基于 Rowkey 创建的Bloom Filter
ROWCOL:基于 Rowkey+Column 创建的Bloom Filter
两者的区别仅仅是:是否使用列信息作为Bloom Filter的条件。
使用ROWCOL时,可以让指定列的查询更快,因为其通过Rowkey与列信息来过滤不存在数据的HFile,但是相应的,产生的Bloom Filter数据会更加庞大。
而只通过Rowkey进行检索的查询,即使指定了ROWCOL也不会有其他效果,因为没有携带列信息。
通过Bloom Filter(如果有的话)快速定位到当前的Rowkey数据存储于哪个HFile之后(或者不存在直接返回),通过HFile携带的 Data Block Index 等元数据信息可快速定位到具体的数据块起始位置,读取并返回(加载到缓存中)。
这就是Bloom Filter在HBase检索数据的应用场景:
- 高效判断key是否存在
- 高效定位key所在的HFile
当然,如果没有指定创建Bloom Filter,RegionServer将会花费比较多的力气一个个检索HFile来判断数据是否存在。
1.4 HFile存储格式
通过Bloom Filter快速定位到需要检索的数据所在的HFile之后的操作自然是从HFile中读出数据并返回。
据我们所知,HFile是HDFS上的文件(或大或小都有可能),现在HBase面临的一个问题就是如何在HFile中 快速检索获得指定数据/p>
HBase随机查询的高性能很大程度上取决于底层HFile的存储格式,所以这个问题可以转化为 HFile的存储格式该如何设计,才能满足HBase 快速检索 的需求。
生成一个HFile
Memstore内存中的数据在刷写到磁盘时,将会进行以下操作:
- 会先现在内存中创建 空的Data Block数据块 包含 预留的Header空间。而后,将Memstore中的KVs一个个顺序写满该Block(一般默认大小为64KB)。
- 如果指定了压缩或者加密算法,Block数据写满之后将会对整个数据区做相应的压缩或者加密处理。
- 随后在预留的Header区写入该Block的元数据信息,如 压缩前后大小、上一个block的offset、checksum 等。
- 内存中的准备工作完成之后,通过HFile Writer输出流将数据写入到HDFS中,形成磁盘中的Data Block。
- 为输出的Data Block生成一条索引数据,包括 {startkey、offset、size} 信息,该索引数据会被暂时记录在内存中的Block Index Chunk中。
至此,已经完成了第一个Data Block的写入工作,Memstore中的 KVs 数据将会按照这个过程不断进行 写入内存中的Data Block -> 输出到HDFS -> 生成索引数据保存到内存中的Block Index Chunk 流程。
值得一提的是,如果启用了Bloom Filter,那么 Bloom Filter Data(位图数据) 与 Bloom元数据(哈希函数与个数等) 将会和 KVs 数据一样被处理:写入内存中的Block -> 输出到HDFS Bloom Data Block -> 生成索引数据保存到相对应的内存区域中。
由此我们可以知道,HFile写入过程中,Data Block 和 Bloom Data Block 是交叉存在的。
随着输出的Data Block越来越多,内存中的索引数据Block Index Chunk也会越来越大。
达到一定大小之后(默认128KB)将会经过类似Data Block的输出流程写入到HDFS中,形成 Leaf Index Block (和Data Block一样,Leaf Index Block也有对应的Header区保留该Block的元数据信息)。
同样的,也会生成一条该 Leaf Index Block 对应的索引记录,保存在内存中的 Root Block Index Chunk。
Root Index -> Leaf Data Block -> Data Block 的索引关系类似 B+树 的结构。得益于多层索引,HBase可以在不读取整个文件的情况下查找数据。
随着内存中最后一个 Data Block、Leaf Index Block 写入到HDFS,形成 HFile 的 Scanned Block Section。
Root Block Index Chunk 也会从内存中写入HDFS,形成 HFile 的 Load-On-Open Section 的一部分。
至此,一个完整的HFile已经生成,如下图所示:
1.5 HFile Compaction
Bloom Filter解决了如何在大量的HFile中快速定位数据所在的HFile文件,虽然有了Bloom Filter的帮助大大提升了检索效率,但是对于RegionServer来说 要检索的HFile数量并没有减少。
为了再次提高HFile的检索效率,同时避免大量小文件的产生造成性能低下,RegionServer会通过 Compaction机制 对HFile进行合并操作。
常见的Compaction触发方式有:
- Memstore Flush检测条件执行
- RegionServer定期检查执行
- 用户手动触发执行
Minor Compaction
Minor Compaction 只执行简单的文件合并操作,选取较小的HFiles,将其中的数据顺序写入新的HFile后,替换老的HFiles。
但是如何在众多HFiles中选择本次Minor Compaction要合并的文件却有不少讲究:
- 首先排除掉文件大小 大于 hbase.hstore.compaction.max.size 值的HFile
- 将HFiles按照 文件年龄排序(older to younger),并从older file开始选择
- 如果该文件大小 小于 hbase.hstore.compaction.min 则加入Minor Compaction中
- 如果该文件大小 小于 后续hbase.hstore.compaction.max 个HFile大小之和 * hbase.hstore.compaction.ratio,则将该文件加入Minor Compaction中
- 扫描过程中,如果需要合并的HFile文件数 达到 hbase.hstore.compaction.max(默认为10) 则开始合并过程
- 扫描结束后,如果需要合并的HFile的文件数 大于 hbase.hstore.compaction.min(默认为3) 则开始合并过程
- 通过 hbase.offpeak.start.hour、hbase.offpeak.end.hour 设置高峰、非高峰时期,使 hbase.hstore.compaction.ratio的值在不同时期灵活变化(高峰值1.2、非高峰值5)
可以看到,Minor Compaction不会合并过大的HFile,合并的HFile数量也有严格的限制,以避免产生太大的IO操作,Minor Compaction经常在Memstore Flush后触发,但不会对线上读写请求造成太大延迟影响。
Compaction的优缺点
HBase通过Compaction机制使底层HFile文件数保持在一个稳定的范围,减少一次读请求产生的IO次数、文件Seek次数,确保HFiles文件检索效率,从而实现高效处理线上请求。
如果没有Compaction机制,随着Memstore刷写的数据越来越多,HFile文件数量将会持续上涨,一次读请求生产的IO操作、Seek文件的次数将会越来越多,反馈到线上就是读请求延迟越来越大。
然而,在Compaction执行过程中,不可避免的仍然会对线上造成影响。
- 对于Major Compaction来说,合并过程将会占用大量带宽、IO资源,此时线上的读延迟将会增大。
- 对于Minor Compaction来说,如果Memstore写入的数据量太多,刷写越来越频繁超出了HFile合并的速度
- 即使不停地在合并,但是HFile文件仍然越来越多,读延迟也会越来越大
- HBase通过 hbase.hstore.blockingStoreFiles(默认7) 来控制Store中的HFile数量
- 超过配置值时,将会堵塞Memstore Flush阻塞flush操作 ,阻塞超时时间为 hbase.hstore.blockingWaitTime
- 阻塞Memstore Flush操作将会使Memstore的内存占用率越来越高,可能导致完全无法写入
简而言之,Compaction机制保证了HBase的读请求一直保持低延迟状态,但付出的代价是Compaction执行期间大量的读延迟毛刺和一定的写阻塞(写入量巨大的情况下)。
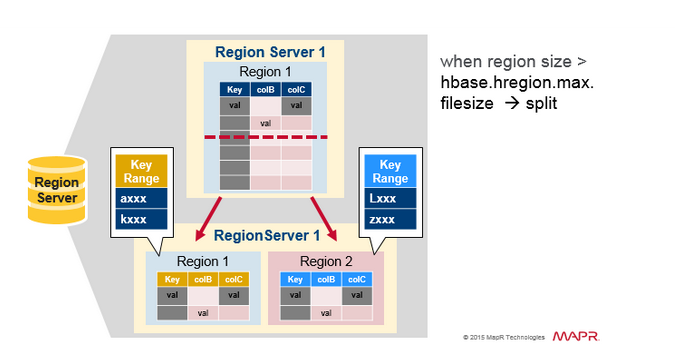
1.6 Region Split
HBase通过 LSM-Tree架构提供了高性能的随机写,通过缓存、Bloom Filter、HFile与Compaction等机制提供了高性能的随机读。
至此,HBase已经具备了作为一个高性能读写数据库的基本条件。如果HBase仅仅到此为止的话,那么其也只是个在架构上和传统数据库有所区别的数据库而已,作为一个高性能读写的分布式数据库来说,其拥有近乎可以无限扩展的特性。
支持HBase进行自动扩展、负载均衡的是Region Split机制。
Split策略与触发条件
在HBase中,提供了多种Split策略,不同的策略触发条件各不相同。
- RegionServer在Zookeeper上的 /hbase/region-in-transition 节点中标记该Region状态为SPLITTING。
- HMaster监听到Zookeeper节点发生变化,在内存中修改此Region状态为RIT。
- 在该Region的存储路径下创建临时文件夹 .split
- 父Region close,flush所有数据到磁盘中,停止所有写入请求。
- 在父Region的 .split文件夹中生成两个子Region文件夹,并写入reference文件
- reference是一个特殊的文件,体现在其文件名与文件内容上
- 文件内容:[splitkey]切分点rowkey,[toptrue/false,true为top上半部分,false为bottom下半部分
- 根据reference文件名,可以快速找到对应的父Region、其中的HFile文件、HFile切分点,从而确认该子Region的数据范围
- 数据范围确认完毕之后进行正常的数据检索流程(此时仍然检索父Region的数据)
- 将子Region的目录拷贝到HBase根目录下,形成新的Region
- 父Regin通知修改 hbase:meta 表后下线,不再提供服务
- 此时并没有删除父Region数据,仅在表中标记split列、offline列为true,并记录两个子region
- 两个子Region上线服务
- 通知 hbase:meta 表标记两个子Region正式提供服务
rollback阶段
如果execute阶段出现异常,则执行rollback操作,保证Region切分整个过程是具备事务性、原子性的,要么切分成功、要么回到未切分的状态。
region切分是一个复杂的过程,涉及到父region切分、子region生成、region下线与上线、zk状态修改、元数据状态修改、master内存状态修改 等多个子步骤,回滚程序会根据当前进展到哪个子阶段清理对应的垃圾数据。
为了实现事务性,HBase设计了使用**状态机(SplitTransaction类)**来保存切分过程中的每个子步骤状态。这样一来一旦出现异常,系统可以根据当前所处的状态决定是否回滚,以及如何回滚。
但是目前实现中,中间状态是存储在内存中,因此一旦在切分过程中RegionServer宕机或者关闭,重启之后将无法恢复到切分前的状态。即Region切分处于中间状态的情况,也就是RIT。
由于Region切分的子阶段很多,不同阶段解决RIT的处理方式也不一样,需要通过hbck工具进行具体查看并分析解决方案。
好消息是HBase2.0之后提出了新的分布式事务框架Procedure V2,将会使用HLog存储事务中间状态,从而保证事务处理中宕机重启后可以进行回滚或者继续处理,从而减少RIT问题产生。
父Region清理
从以上过程中我们可以看到,Region的切分过程并不会父Region的数据到子Region中,只是在子Region中创建了reference文件,故Region切分过程是很快的。
只有进行Major Compaction时才会真正(顺便)将数据切分到子Region中,将HFile中的kv顺序读出、写入新的HFile文件。
RegionServer将会定期检查 hbase:meta 表中的split和offline为true的Region,对应的子Region是否存在reference文件,如果不存在则删除父Region数据。
负载均衡
Region切分完毕之后,RegionServer上将会存在更多的Region块,为了避免RegionServer热点,使请求负载均衡到集群各个节点上,HMaster将会把一个或者多个子Region移动到其他RegionServer上。
移动过程中,如果当前RegionServer繁忙,HMaster将只会修改Region的元数据信息至其他节点,而Region数据仍然保留在当前节点中,直至下一次Major Compaction时进行数据移动。

至此,我们已经揭开了HBase架构与原理的大部分神秘面纱,在后续做集群规划、性能优化与实际应用中,为什么这么调整以及为什么这么操作 都将一一映射到HBase的实现原理上。
如果你希望了解HBase的更多细节,可以参考《HBase权威指南》。
二、集群部署
经过冗长的理论初步了解过HBase架构与工作原理之后,搭建HBase集群是使用HBase的第一个步骤。
需要注意的是,HBase集群一旦部署使用,再想对其作出调整需要付出惨痛代价(线上环境中),所以如何部署HBase集群是使用的第一个关键步骤。
2.1 集群物理架构
硬件混合型+软件混合型集群
硬件混合型 指的是该集群机器配置参差不齐,混搭结构。
软件混合型 指的是该集群部署了一套类似CDH全家桶套餐。
如以下的集群状况:
- 集群规模:30
- 部署服务:HBase、Spark、Hive、Impala、Kafka、Zookeeper、Flume、HDFS、Yarn等
- 硬件情况:内存、CPU、磁盘等参差不齐,有高配有低配,混搭结构
这个集群不管是规模、还是服务部署方式相信都是很多都有公司的「标准」配置。
那么这样的集群有什么问题呢/p>
如果仅仅HBase是一个非「线上」的系统,或者充当一个历史冷数据存储的大数据库,这样的集群其实一点问题也没有,因为对其没有任何苛刻的性能要求。
但是如果希望HBase作为一个线上能够承载海量并发、实时响应的系统,这个集群随着使用时间的增加很快就会崩溃。
从 硬件混合型 来说,一直以来Hadoop都是以宣称能够用低廉、老旧的机器撑起一片天。
这确实是Hadoop的一个大优势,然而前提是作为离线系统使用。
离线系统的定义,即跑批的系统,如:Spark、Hive、MapReduce等,没有很强的时
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!