先简单介绍一下SysML会议,2018年新成立的一个聚焦在机器学习系统、软件、硬件等综合领域研究的一个学术会议。由一堆学术界和工业界大佬抱团组建。从18年发布的一篇Machine Learning System(机器学习系统)白皮书可以看到。
ModelBatch has two key components:
-
Shared preprocessing: Preprocessing performed on the CPU, and
shared among the different models. After preprocessing, processed
tensors are moved to the GPU asynchronously; this communication is
overlapped with compute using double buffering -
Parallel model training: Performed on the GPU on a per-model basis,
contains operations like convolutions, matrix multiplications, and
pooling. Kernels launched in parallel using CUDA streams
- 包括RNN类 络的并行
- 在不相同model训练场景下如何用该技术因为模型的结束时间会差很多,这个怎么调整呢想想应该是用异步启动,前面的model结束后可以新起model来补充GPU利用率)
- 分布式训练中能不能用modelbatch一个情况是,我们可以天然把通信藏在多个模型的训练计算中,通信虽然有delay,但是其他model还在跑计算,所以实际上并没有完全浪费。
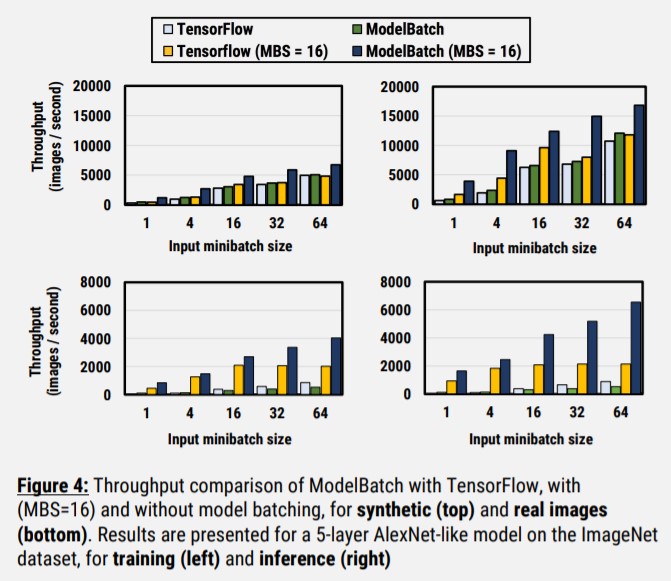

2、待补充。
参考资料
[1] 机器学习 + 系统 : 一个新的方向,https://zhuanlan.zhihu.com/p/61786615
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!