·本次作业的要求
1. 统计文件的字符数(只需要统计Ascii码,汉字不用考虑,换行符不用考虑,’ ’不用考虑)(ascii码大小在[32,126]之间)
2. 统计文件的单词总数
3. 统计文件的总行数(任何字符构成的行,都需要统计)(不要只看换行符的数量,要小心最后一行没有换行符的情形)(空行算一行)
4. 统计文件中各单词的出现次数,对给定文件夹及其递归子文件夹下的所有文件进行统计
6. 统计两个单词(词组)在一起的频率,输出频率最高的前10个。
注意:
a) 空格,水平制表符,换行符,均算字符
b) 单词的定义:至少以4个英文字母开头,跟上字母数字符 ,单词以分隔符分割,不区分大小写。
英文字母:A-Z,a-z
字母数字符 :A-Z,a-z,0-9
分割符:空格,非字母数字符
例如:”file123”是一个单词,”123file”不是一个单词。file,File和FILE是同一个单词。
如果两个单词只有最后的数字结尾不同,则认为是同一个单词,例如,windows,windows95和windows7是同一个单词,iPhone4和IPhone5是同一个单词,但是,windows和windows32a是不同的单词,因为他们不是仅有数字结尾不同。输出按字典顺序,例如,windows95,windows98和windows2000同时出现时,输出windows2000。单词长度只需要考虑[4, 1024],超出此范围的不用统计。
c)词组的定义:windows95 good, windows2000 good123,可以算是同一种词组。按照词典顺序输出。三词相同的情形,比如good123 good456 good789,根据定义,则是 good123 good123 这个词组出现了两次。
good123 good456 good789这种情况,由于这三个单词与good123都是同一个词,最终统计结果是good123 good123这个词组出现了2次。
两个单词分属两行,也可以直接组成一个词组。统计词组,只看顺序上,是否相邻。
d) 输入文件名以命令行参数传入。需要遍历整个文件夹时,则要输入文件夹的路径。
e) 输出文件result.txt
characters: number
words: number
lines: number
<word>: number
<word>为文件中真实出现的单词大小写格式,例如,如果文件中只出现了File和file,程序不应当输出FILE,且<word>按字典顺序(基于ASCII)排列,上例中程序应该输出File: 2
f) 根据命令行参数判断是否为目录
g) 将所有文件中的词汇,进行统计,最终只输出一个整体的词频统计结果。
评分标准
1. 统计文件的字符数(1分)
2. 统计文件的单词总数(1分)
3. 统计文件的总行数(1分)
4. 统计文件中各单词的出现次数(1分)
5. 对给定文件夹及其递归子文件夹下的所有文件进行统计(2分)
6. 统计两个单词(词组)在一起的频率,输出频率最高的前10个(2分)
以上六个结果输出错误则对应子任务得-1分,全部输出正确则按运行时间确定排名(用时按升序前30%得满分8分,30%-70%得7.5分,后30%得7分)。
7. 博客撰写(代码实现过程,性能分析、优化 告等)(2分)
8. 在Linux系统下,进行性能分析,过程写到blog中(附加题,2分)
·编写过程
一开始的基本思路是,使用fgetc函数读取每一个字符,并且判断是否在36,127之间,同时判断换行符,这样就可以统计出字符数和行数。单词统计方法,因为要求是至少前四个字符是字母,所以扫描到四个连续字母开始记录,并往后扫描,设置后缀计数变量flag,遇到数字就++,遇到字母就归零,遇到空格就停止扫描
每次扫到单词时都遍历整个链表(效率极低),如果已存在就次数++,不存在就创建新结点,词组的储存和单词类似,将这个方法在理论上是可行的,但是因为文本过于巨大,时间复杂度过高,无法跑出结果。
在这种数据结构下采取的优化方法是,将单词的头四个字母进行分类,创建四维数组
再次进行单词分类,以单词的长度为标准,奇数和偶数分开存,
再次优化,宏定义一个常量speed
speed为5时,运行时间为
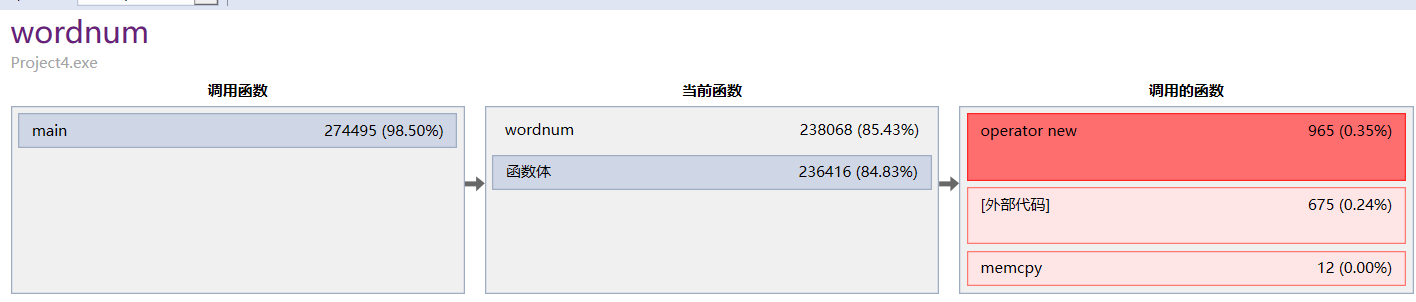

从vs的统计结果上来看,统计单词函数占用了绝大多数的cpu使用率,也是最耗费时间的部分,改变speed的值会使此函数占用率下降。
·时间分配
| 项目 | 计划用时(分钟) | 实际用时(分钟) |
| 计划项目 | 60 | 120 |
| 开发 | 1440 | |
| ·需求分析 | 60 | 60 |
| ·项目构思 | 60 | 120 |
| ·生成设计文档 | 120 | 60 |
| ·具体设计 | 120 | 60 |
| ·具体编码 | 600 | 900 |
| ·代码除错 | 300 | 600 |
| 告 | 60 | 60 |
| ·项目 告与总结 | 60 | 60 |
| 总计 | 1560 | 2160 |
·项目总结与经验教训
通过这次作业我认识到了提前计划好数据结构的重要性,因为这次使用的数据机构比较简单,导致程序运行起来速度很慢,而且优化效果不好。
在代码的编写和除错方面,我认识到了要学好文件操作,要熟练掌握命令行参数的使用方法。
写代码要细心,比如本人因为数组越界问题浪费了大量时间,还有因为忘记写fclose函数导致文件指针越界,导致读了一些文件之后后面的文件就无法读取。
还有我认识到了提前构思重要性,不要低估任务量,提前想好代码的实现方法会使后面的工作顺利得多。
相关资源:下拉通刷词软件v3.1.zip-其它代码类资源-CSDN文库
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!