sqoop用于 hadoop 与关系型数据库之间的数据传递,可以将数据库中的数据导入到hdfs等文件系统,也可以将hdfs 上的数据导入到数据库中。
准备sqoop 软件包 sqoop-1.4.7.bin__hadoop-2.6.0
http://archive.apache.org/dist/sqoop/1.4.7/
一、将sqoop 软件复制到 根目录下
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/home/hadoop/hadoop-2.7.7
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/home/hadoop/hadoop-2.7.7
四、加载驱动包,因为要跟数据库连接,要有相应的数据库的驱动,这里以mysql为例。
mysql-connector-java-5.1.46-bin.jar
https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.46.zip
hadoop-common-2.7.7.jar
hadoop的jar包,可以在hadoop安装包lib 文件下找。
六、HDFS 导出数据到mysql,需要导出的数据格式为:
9.2 Generating splits for a textual index column allowed only in case of “-Dorg.apache.sqoop.splitter.allow_text_splitter=true” property passed as a parameter
最后执行成功的时候我们可以看到,sqoop 数据迁移,其实用的也是mapreduce,出现这原因是yarn 资源管理给予的yarn.nodemanager.resource.memory-mb 内存不够大,默认是1536。
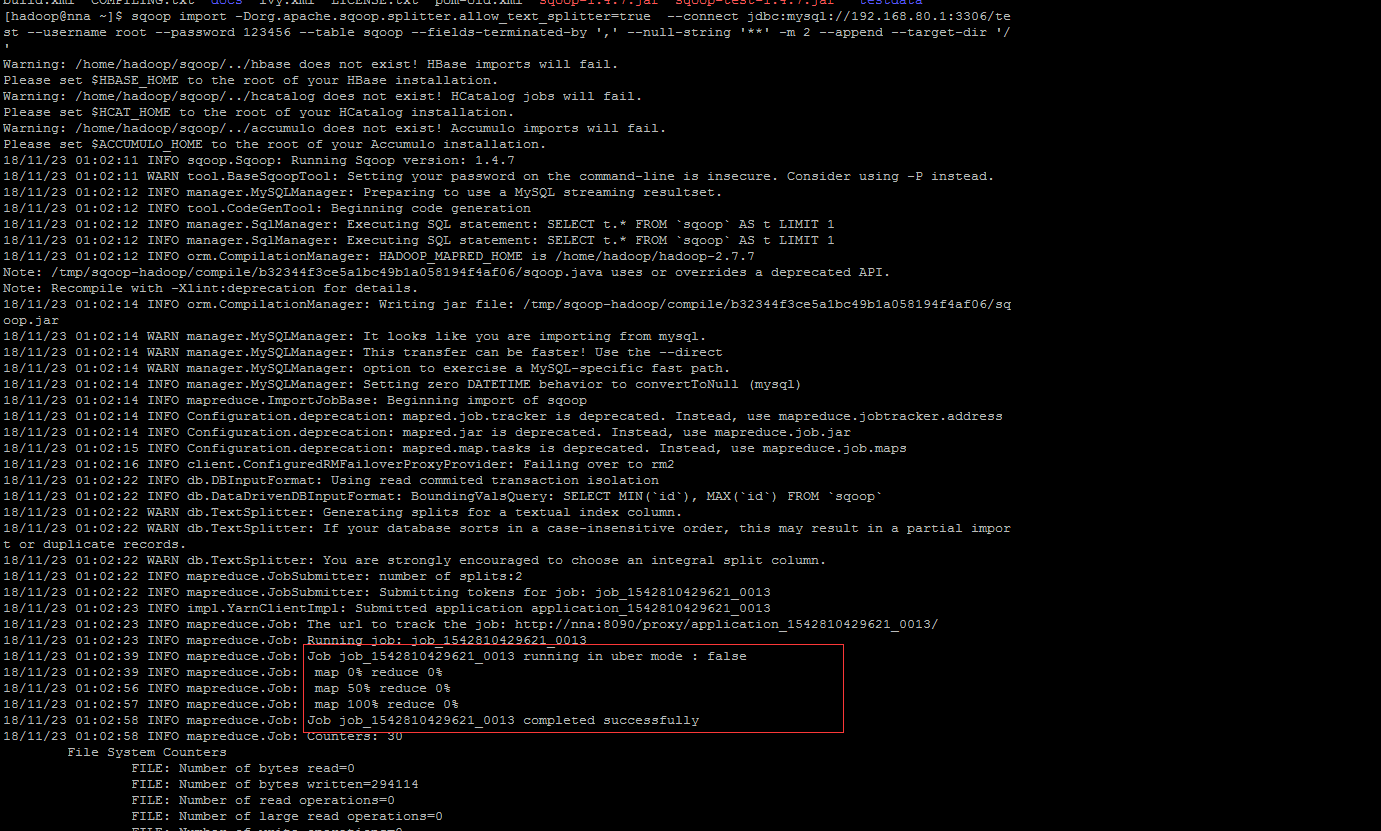

解决办法:在yarn-site.xml 追加下面两个属性:
文章知识点与官方知识档案匹配,可进一步学习相关知识云原生入门技能树首页概览8674 人正在系统学习中
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!