本篇文档,带大家用Python做一下词频统计
本章需要用到Python的jieba模块
jieba模块是一个经典的用于中文分词的模块
首先呢 我们需要读取文章的内容,并用jieba库的lcut进行分词
然后 我们去统计人名的出现次数
这里需要分析什么词语是人名,我们去创建一个文档,当做字典存储人名信息
人名还会有其他的表示,我们将它转化成一样的名字
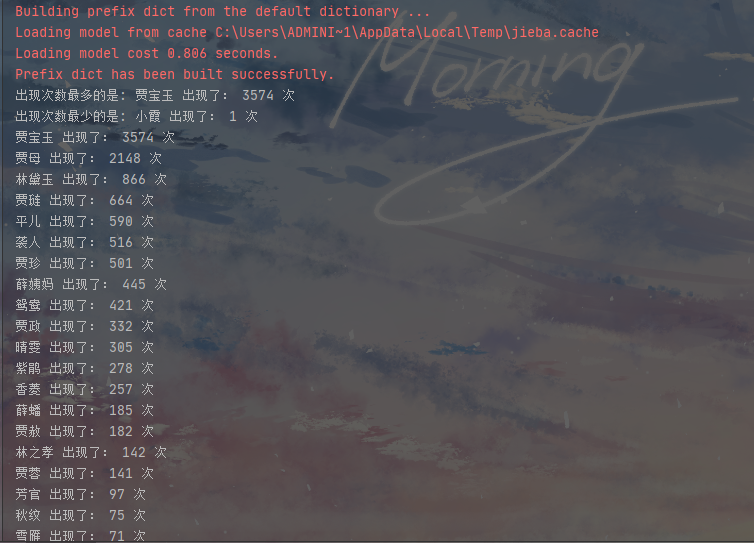
最后我们将数据排序整理一下
完整代码如下:
效果图如下:

Python问题解答私信我
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!