概述
作为实时计算的新贵,Flink受到越来越多公司的青睐,它强大的流批一体的处理能力可以很好地解决流处理和批处理需要构建实时和离线两套处理平台的问题,可以通过一套Flink处理完成,降低成本,Flink结合数据湖的处理方式可以满足我们实时数仓和离线数仓的需求,构建一套数据湖,存储多样化的数据,实现离线查询和实时查询的需求。目前数据湖方面有Hudi和Iceberg,Hudi属于相对成熟的数据湖方案,主要用于增量的数据处理,它跟spark结合比较紧密,Flink结合Hudi的方案目前应用不多。Iceberg属于数据湖的后起之秀,可以实现高性能的分析与可靠的数据管理,目前跟Flink集合方面相对较好。
环境搭建
环境:
hadoop 2.7.7
hive 2.3.6
Flink 1.11.3
iceberg 0.11.1
jdk 1.8
mac os
下载软件
Hadoop :https://archive.apache.org/dist/hadoop/core/hadoop-2.7.7/
Hive:https://archive.apache.org/dist/hive/hive-2.3.6/
Flink: https://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.13.0/flink-1.13.0-bin-scala_2.11.tgz
Iceberg:https://repo.maven.apache.org/maven2/org/apache/iceberg/iceberg-flink-runtime/0.11.1/
查看环境
安装配置
安装软件
解压hadoop压缩包:
解压hive压缩包:
重命名:
解压flink压缩包:
配置环境变量
打开配置文件(针对mac系统):
添加环境变量:
执行source:
验证是否配置完成:
如上显示标识,hadoop和hive环境变量配置OK,已经生效
配置Hadoop
进入hadoop目录:
配置hadoop-env.sh,配置如下一行
配置core-site.xml:
配置hdfs-site.xml:
格式化hdfs:
启动hadoop:
查看启动是否正常:
出现NameNode和DataNode表示已经正常启动
配置Hive
创建hdfs目录
配置Hive
Hive的元数据是用derby
配置hive-site.xml
配置hive-env.sh
创建Hive metastore
如果创建失败,请查看hive/scripts/metastore/upgrade/derby目录下hive-schema-2.3.0.derby.sql文件(Hvie 2.3.6我可以直接创建成功,2.3.4会创建失败)。
执行成功,会在bin目录下创建metastore_db目录,如果需要重新执行上面命令,请手动删除metastore_db,否则会 错。
启动hive metaservice:
检查启动是否成功:
看到9083正常监听,表示启动正常。
配置Flink
将iceberg-flink-runtime-0.11.1.jar和flink-sql-connector-hive-2.3.6_2.11-1.11.0.jar放入到flink的lib目录下,用来启动Flink sql client,进行iceberg操作,flink结合iceberg会有很多依赖包,也需要放到lib目录下,否则无法正常启动,不一一列举,参照下图:
执行命令:
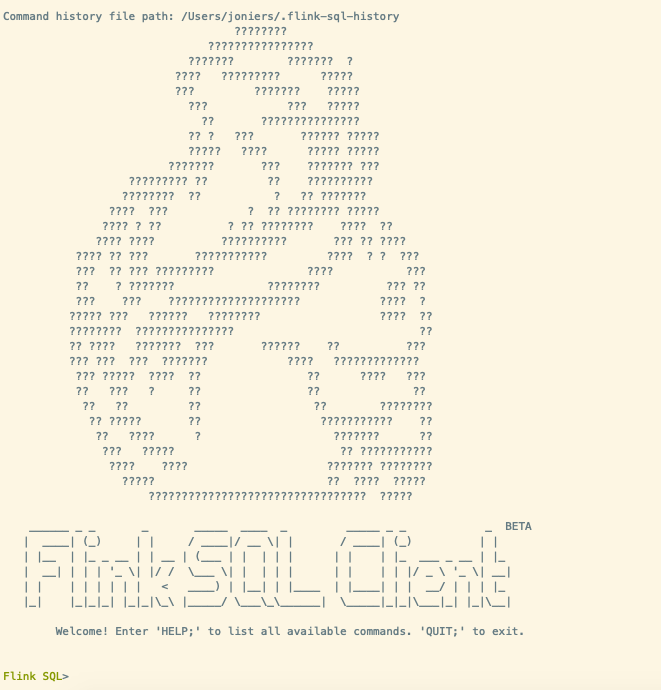

如图表示启动成功
创建和使用catalogs
创建hive_catalog,执行下面命令:
CREATE CATALOG hive_catalog WITH (
‘type’=‘iceberg’,
‘catalog-type’=‘hive’,
‘uri’=‘thrift://localhost:9083’,
‘clients’=‘5’,
‘property-version’=‘1’,
‘warehouse’=‘hdfs://localhost:9000/user/hive/warehouse’
);
这里针对命令简单面试一下,我们需要配置uri,也就是我们启动hive metaservice的地址,warehouse执行我们创建的hive存储路径
在Flink sql下执行上面命令,你会发现,你失败了,不要灰心,这很正常,iceberg官 有类似的问题描述,不过上面的解决方式不适用于我,一般是版本不匹配或者jdk不匹配导致, 错信息见下:
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!