告警数据挖掘的方向及痛点
为了保证软件服务质量和用户体验、减少经济损失,故障智能分析至关重要,主要聚焦在三个方向:
下面,我针对痛点问题进行具体讲解:
01
告警定级策略不合理,影响故障发现时效性
举个实际案例,曾有金融客户在早上10点45分通过用户电话 障发现故障,但在10点45分之前就已有一些与故障相关的告警,比如说响应时间上升到500ms。不过由于人工设置的阈值导致告警级别不够高,并没有引起工程师的注意。
需要注意的是,服务故障和告警风暴产生时,应用架构有很多组件,且每个组件都有自己的监控数据,会产生相应的告警。同时,硬件拓扑和软件会发生复杂依赖关系,导致这些告警和故障之间会不断传导。
以上是学术界的情况,但是工业界也没有用告警数据做故障预测的有效方案。
首先,我们常常听到,大家会基于专家知识和运维经验,去总结事件预测的规则。比如当线上的告警满足规则,就认为要发生相应的事件。不过,基于规则的预测方法,在实际中经常会出现误 、漏 。我们分析其原因在于:维护和制定规则需要足够的运维经验,且耗费时间;不同工程师制定规则的偏好不一样,很难有统一的标准;服务系统总是会经历不停的迭代变更,固定的规则很难适应动态的环境。
其次,基于频繁项集挖掘去做探索,我们认为经常一起出现的告警会有一些征兆表现,而实际落地尝试中,金融行业工程师反馈这类方法覆盖面比较小。由于告警数据的复杂性和告警内容中混杂的参数,大多数事件都没有对应的频繁项告警,所以这类方法在金融数据中心可用性并不高。
关于告警数据挖掘的三篇论文研究成果
我们在INFOCOM 2020 、ICSE SEIP 2020、ESEC/FSE 2020发表了三篇论文(如下图),对应解决故障发现、故障诊断和故障预测的痛点问题。
当然,这也有明显的不足,简单的手工规则的定级方式不能满足线上服务系统的动态性与复杂性,手工定制和维护大量的规则耗时、耗力。
同时,我们也遇到了告警种类非常多,系统变更会引入新类型的告警,不同工程师制定规则的偏好不一致、很难有统一的规则等问题。这要求我们通过数据挖掘和数据驱动的方式,来做到基于系统自适应的告警动态定级的算法,来帮助及时的故障发现。
在此过程中,我们同样遇到了一些挑战(如图):
整体流程方面,将告警数据和指标数据分别进行预处理和数据筛选,用告警模板提取相应的特征,指标也提取相应的特征,生成特征向量后,再从工单中进行标注提取,建立排序模型,完成离线训练。在线数据同样会进行特征提取和特征向量的建立,经过排序模型后给出结果,直接反馈给工程师,去看哪一个更严重。
告警所在的业务也有各种各样的黄金指标,特别是相应的业务指标。对此,我们提取了所在应用系统的关键业务指标,比如交易量、响应时间、成功率等。这里主要采用两种方式:一、对它们做异常检测,将异常分数作为评分;二、进行多指标异常检测,安全模拟一个实体的健康分数,作为特征融入模型。
在线数据同样经过特征工程,经过排序的过程,生成排序结果。比如,当abcde告警同时到达时,我们能够给出ranking结果,让管理员更清晰知道从哪个告警入手。
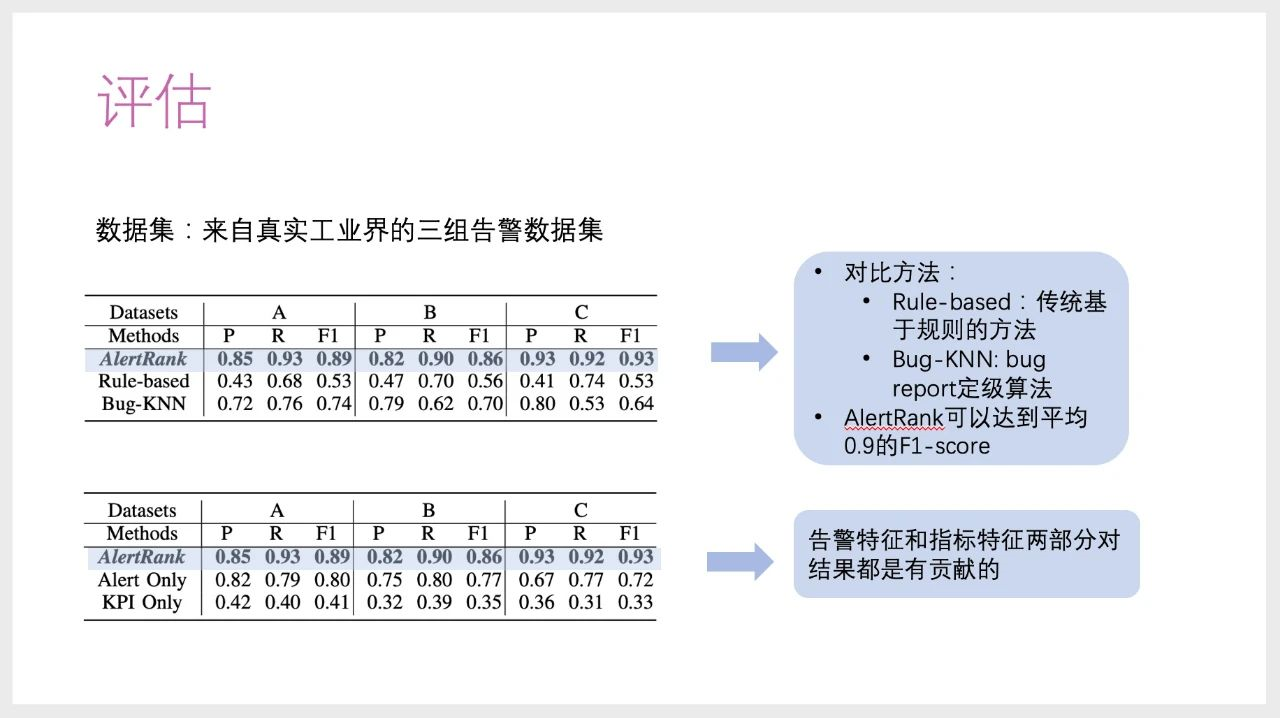

最后介绍一下评估规则,我们使用三组工业界真实的告警数据来评估,用AlertRank方法去对比传统基于规则的方法和BUG 告定级算法BUG-KNN。结果表明, AlertRank方法可以达到平均90%的F1 -SCORE,是整体最优的方法。同时,我们评估了多特征融合方式的作用,分别看了告警特征和指标特征对结果的贡献,发现它们对模型起到正向作用。
以上是发表在INFOCOM 2020顶会上的论文,我们提出的“自适应的告警动态定级”方法已应用于工业实践中,赋能金融客户切实解决运维难题。
下一期精彩继续,将分享在ICSE SEIP 2020、ESEC/FSE 2020发表的两篇论文,介绍“告警风暴摘要”和“基于告警的事件预测”的核心思想,敬请关注。
文章知识点与官方知识档案匹配,可进一步学习相关知识算法技能树首页概览34187 人正在系统学习中
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!