发布一企业技术架构图,供大家参考。
1、核心是两库一线
1.1 接口总线
所有算法功能抽象成接口,其中大部分接口的方法都是泛型方法,是为了解决某一大类问题的
1.2 代码库
代码库包含现接口总线中接口的各种实现
1.3 应用库
提供用户的界面或者提供给外部的服务
是通过容器配置调用算法库中的代码来实现的各种应用
二、应用关系图
ENode是一个.NET平台下,纯C#开发的,基于DDD,CQRS,ES,EDA,In-Memory架构风格的,可以帮助开发者开发高并发、高吞吐、可伸缩、可扩展的应用程序的一个应用开发框架。
- 开源项目地址:https://github.com/tangxuehua/enode
- QQ交流群 :185916873
晚上把公司应用的架构结合之前研究的东西梳理了下,整理了一张架构规划图,贴在这里备份
下面是个人理解的做架构的几个要点:
1、系统安全
这是首要考虑的,以这张图为例, 络划分为3个区:
a) DMZ区可以直接公 访问,也可以 与App Core区互通,但不能直接与DB Core区互通 (通常这里放置 反向代理Web服务器)
b) App Core区能与DMZ区、DB Core区互通,但是无法直接从公 访问 (通常这里放置 应用服务器、中间件服务器之类)
c) DB Core区仅与App Core区互通 (通常这里放置 核心数据库)
2、尽量消除单点故障
上图中,除了“硬件负载均衡”节点外,其它节点都可以部署成集群(DB有点特殊,传统RDBMS要实现分布式/集群还是比较困难的,要看具体采用的数据库产品,并非所有数据库都能方便的做Sharding),Jboss本身可以通过Domain模式+mod_cluster实现集群、Redis通过Master/Slave以Sentinel方式可以实现HA、IBM MQ本身就支持集群、FTP Server配合底层储存阵列也可以做到HA、Nginx静态资源服务器自不必说
3、成本
尽量采用开源成熟产品,jboss、redis、nginx、apache、mysql、rabbit MQ都是很好的选择。硬件负载均衡通常成本不低,但是效果明显,如果实在没钱,域名解析采用DNS轮询策略,也能达到类似效果,只不过可靠性略差。
4、Database问题
常规企业应用中,传统关系型数据仍然是主流,但是no-sql经过这几年发展,技术也日渐成熟了,一些非关键数据可以适当采用no-sql数据库,比如:系统日志、 文历史记录这类相对比较独立,而且增长迅速的数据,可以考虑存储到no-sql db甚至HDFS、TFS等分布式开源文件系统中。
如果系统数据量级达到单机RDBMS的上限,尽早考虑Sharding方案,目前mysql在这方面比较成熟,其它数据库就不好说了。
5、性能
web server、app server这些一般都可以通过集群实现横向扩张,满足性能日常增长的需求。最大的障碍还是DB,如果规模真达到了DB的上限,还是考虑换分布式DB或者迁移到“云”上吧。
HBase 系统架构图
HRegionServer管理一些列HRegion对象; 每个HRegion对应Table中一个Region,HRegion由多个HStore组成; 每个HStore对应Table中一个Column Family的存储; Column Family就是一个集中的存储单元,故将具有相同IO特性的Column放在一个Column Family会更高效
HStore: HBase存储的核心。由MemStore和StoreFile组成。 MemStore是Sorted Memory Buffer。用户写入数据的流程:
图片解释: HFile文件不定长,长度固定的块只有两个:Trailer和FileInfo Trailer中指针指向其他数据块的起始点 File Info中记录了文件的一些Meta信息,例如:AVG_KEY_LEN, AVG_VALUE_LEN, LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY等 Data Index和Meta Index块记录了每个Data块和Meta块的起始点 Data Block是HBase I/O的基本单元,为了提高效率,HRegionServer中有基于LRU的Block Cache机制 每个Data块的大小可以在创建一个Table的时候通过参数指定,大 的Block有利于顺序Scan,小 Block利于随机查询 每个Data块除了开头的Magic以外就是一个个KeyValue对拼接而成, Magic内容就是一些随机数字,目的是防止数据损坏
HFile里面的每个KeyValue对就是一个简单的byte数组。这个byte数组里面包含了很多项,并且有固定的结构。
HLog文件就是一个普通的Hadoop Sequence File,Sequence File 的Key是HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和region名字外,同时还包括 sequence number和timestamp,timestamp是“写入时间”,sequence number的起始值为0,或者是最近一次存入文件系统中sequence number。 HLog Sequece File的Value是HBase的KeyValue对象,即对应HFile中的KeyValue
结束语:这篇文章是我专门在 上弄下来的,算是hbase部分的终极篇吧,我的服务端的源码系列也要基于这个顺序来开展。
一.三层架构图
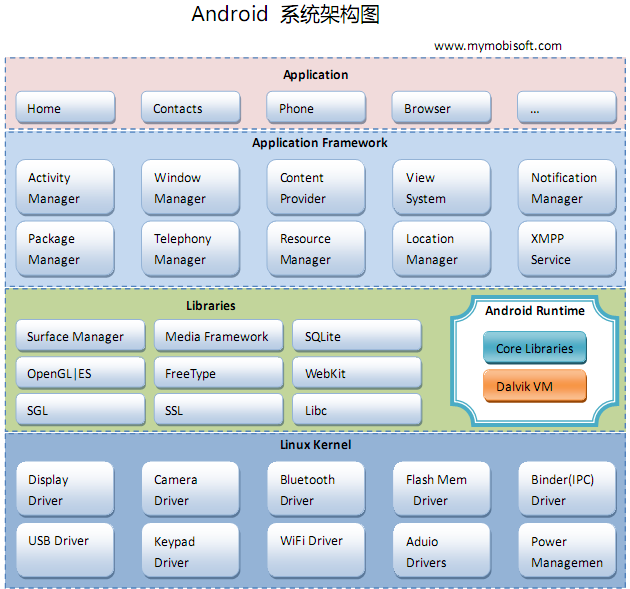

从上图中可以看出,Android系统架构为四层结构,从上层到下层分别是应用程序层、应用程序框架层、系统运行库层以及Linux内核层,分别介绍如下:
1)应用程序层
Android平台不仅仅是操作系统,也包含了许多应用程序,诸如SMS短信客户端程序、电话拨 程序、图片浏览器、Web浏览器等应用程序。这些应用程序都是 用Java语言编写的,并且这些应用程序都是可以被开发人员开发的其他应用程序所替换,这点不同于其他手机操作系统固化在系统内部的系统软件,更加灵活和个 性化。
2)应用程序框架层
应用程序框架层是我们从事Android开发的基础,很多核心应用程序也是通过这一层来实现其核心功能的,该层简化了组件的重用,开发人员可以直接使用其提 供的组件来进行快速的应用程序开发,也可以通过继承而实现个性化的拓展。
a) Activity Manager(活动管理器)
管理各个应用程序生命周期以及通常的导航回退功能
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!