一、共现分析概念及主要类型
|
类型 |
含义 |
首次提出者 |
对应论文 |
|
文献耦合 |
两篇或多篇文献同时引证一篇论 文 |
M.M.Kessler(1963) |
Kessler M M. Bibliographic coupling between scientific papers[J]. Journal of the Association for Information Science & Technology, 1963, 14(1):10-25. |
|
文献同被引 |
两篇或多篇文献被同一篇文献引用 |
Henry Small(1973) |
Smal lH.Co-citation in the scientific literature : A new measure of the relationship between two documents [J]. Journal of the American Society for Information Science , 1973,24(4):265-269. |
|
共词 |
词汇对同时出现在同一文献中 |
M.Callon、J.Law、A.Rip(1986) |
Callon M, Law J, Rip A. Mapping the Dynamics of Science and Technology[M]// Mapping the dynamics of science and technology :. The Macmillan Press, 1986:815. |
|
White、Griffith(1981) |
White H D, Griffith B C. Author cocitation: A literature measure of intellectual structure[J]. Journal of the Association for Information Science & Technology, 1981, 32(3):163-171. |
||
|
共链 |
两个 页同时被第3个 页链接或两个 页同时拥有指向第3个 页的链接 |
Ray Larson(1996) |
Larson R R. Bibliometrics of the World Wide Web: An Exploratory Analysis of the Intellectual Structure of Cyberspace.[C]// Asis Meeting. 1996:71-78. |
|
络共词 |
|
Kipp(2006) |
Kipp M E I, Campbell D G. Patterns and Inconsistencies in Collaborative Tagging Systems: An Examination of Tagging Practices[J]. Proceedings of the American Society for Information Science & Technology, 2006, 43(1):1–18. |
|
|
Leydestorff(2006) |
Leydesdorff L, Vaughan L. Co-occurrence matrices and their applications in information science: Extending ACA to the Web environment[M]. John Wiley & Sons, Inc. 2006. |
(1)确定分析的问题:热点问题、领域结构、发展过程及特点、领域之间的关系
|
不同类型的文献单元的选取 |
|
|
从全文中提取:需要借助于机器学习算法融合语言学信息抽取关键词,研究难度和代价较大,抽取高质量的关键词更是一个挑战,因此在实际研究中较少采用。 |
|
|
术语的规范化 |
泛用(含义相同,但表述相异):同义词、近义词、缩写词及中英混用 |
|
单义性:术语只依附于某一特定专业或学科范围,脱离其专业学科来笼统地使用术语,必然会造成对术语的曲解,如“文件” 在档案学中和信息技术学科中是两个不同的概念 |
|
|
术语表达的粒度:外延过宽,语义表达的过于空泛,无法解释文献具体的研究内容,甚至还会增加共词分析中共词矩阵的维数,给后续数据处理带来干扰,需要对术语进行细化 |
|
|
术语历时变化:术语概念内涵与外延会随着时间的推移发生动态性变迁,名称也随之发生变化,出现一个术语有多种含义或存在多种理解与解释的情况。对术语的使用,也要从历时性角度考证术语的词源,追溯术语的历史演变与动态性变迁,在不同的时期把握术语的不同概念。 |
|
|
新术语构造的理据和规范问题: 会与科学的不断发展,与 之同步会产生大量对新事物、新事件以及新现象定义的新术语。新术语的构建不能随意标引,必须规范化,依据一定的构造理据,尽可能选自其他受控词表或比较权威的参考书目,使之词性规范、概念明确,并符合科学性、通用性的需求。 |
|
|
术语表征差异化 |
传统共现分析假设术语的独立性,不考虑术语之间表达的差异性,而忽略关键词之间的权重差异必然导致最终的共词分析效果存在一定程度的失真。考虑文献的篇章语义结构以及术语“同量不同质”的现象,在一定程度上能够很好地改善共词分析的结果。从标引源差异、文献属性差异以及词重要性差异等不同角度进行加权共词分析方法是必要的、合理的。通过构建不同的映射模型,可以对概念之间的不同关系进行强化或衰减,从而展现出不同的研究目的。 |
其中,术语规范化方法主要有两种:
A. 基于受控词典或分类词表进行术语规范:可借助于词表对收集到的术语进行规范,或直接借助已规范的术语如主题词、叙词表进行共现分析。
B. 基于人工干预方式的规范处理:借助自我的经验制定相应的规则、方法来实现人工干预处理
(4)核心关键词选定
受工具、人力的限制以及结果分析和呈现的需要,研究者通常只选取部分关键词作为共词分析的对象。主要有两种方式选取:
一是指标筛选:例如根据词频高低、节点中心性[②]、h指数[③]、词共现强度[④]来遴选;
二是模型筛选:如词汇链[⑤]、核心-边缘结构模型[⑥]、K-core分解[⑦]等,将术语集合转化成 络模型实现术语的抽取。但由于在术语构建的 络中,上述指标与词频仍然线性相关,因而抽取的术语与高频词并无太大差异。
(5)词汇共现关系度量(术语之间的相似性计算并构建相关矩阵)
传统共现分析通常基于文献中关键词对的共现性来构建共词矩阵(一般不直接选用词对频率的绝对值作为量度指标,通常将共现频率其进行包容化处理,如包容指数法、临近指数法、相互包容系数法等)。基于词频共现频率的方法缺乏对词汇间语义关系和关系强度的解释,为此,学者借助RDF三元组对关联数据进行细粒度和语义关联化等方法来改善。
(6)共词分析中的统计方法
共现矩阵的计算是共词分析的重要一步,在此基础上采用不同的统计学方法,揭示共词中的信息,常用的统计分析方法有:聚类、关联规则、词频、突发伺监测、因子分析、贝叶斯分类等。
(7)对共词结果的可视化展示
类团关系图:将类团间关系的强弱以连接线的粗细表示,关系越强,连线越粗,通常只显示类团间的关系,不显示类团内成员之间的关系,相对比较简单。
战略坐标图[⑧]:以向心度(横坐标)和密度(纵坐标)为参数绘制成的二维坐标,用来表示某一研究领域内部联系情况和领域间相互影响的情况。其中,向心度表示领域间互相影响的强度,密度表示某一领域内部联系强度。
聚类谱系图[⑨],也称聚类树图,其用逐级连接的方式把距离相近的主题词或主题连接起来,直至并为一个大主题。
多维尺度图谱[⑩]:利用平面距离展示出词间亲疏关系,能够判断出某主题在学科领域中的位置。
会 络分析图谱[11]:通过节点-链接图直观、形象地反映词间联系的强弱,快速定位核心词和边缘词。
3、共词分析的主要类型
(1)共词聚类分析法
词对在同一篇文献出现的频率,反映词对间关系紧密的程度。对共词关系 络中的词与词之间的距离进行数学运算,将距离较近的主题词聚集起来,形成一个个概念相对独立的类团,使得类团内属性相似性最大,类团间属性相似性最小。
(2)共词关联分析法
关联规则是描述一个事物中物品同时出现的规律的知识模式,即通过量化的数据描述物品A的出现对物品B的出现有多大影响。例如在一篇有关某病的药物治疗文献中,对该文的标引时,除了有“病A/药物治疗”的主题词外,“药B/治疗应用”的主题词也很有可能同时存在,以表达药B有治疗某病A的功效。共词关联分析以此为原理,通过关联统计方法,揭示主题词间的依存关系。
(3)共词词频分析法
一种揭示或表达文献核心内容的关键主题词在某一研究领域文献中出现的频次高低来确定该领域研究热点和发展动向的文献计量法,通常将共现聚类和共词词频分析相互结合。
(5)突发词监测法
关注焦点词相对增长率突然增长的词,基于单个词的词频增长率变化更有可能涉及到领域局部热点的变化。
4、共词分析法的应用
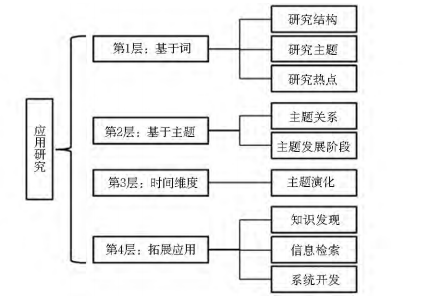

(1)基于词的应用研究:解释某一领域的研究主题,确定研究领域的知识结构、探索研究领域内的热点问题:方法主要是多元统计分析(因子分析、聚类分析、多维尺度分析)和 会 络分析等。
(2)基于主题的应用研究:揭示某一研究领域内研究主题之间的关系,进一步揭示研究主题所处的发展阶段,方法主要是战略坐标
(3)时间维度上的应用研究,即在第二层应用研究的基础上加上时间标签,考察某一研究领域内研究主题发展的历史脉络及其子领域的演进态势等;
(4)拓展应用研究:通过词间关系的数据挖掘来进行知识发现[12][13]、利用共词分析结果拓展检索领域[14]、进行系统开发[15]等。
[1] 傅柱, 王曰芬. 共词分析中术语收集阶段的若干问题研究[J]. 情 学 , 2016, 35(7):704-713.
[②] Choi J, Yi S, Lee K C. Analysis of keyword networks in MIS researchand implications for predicting knowledge evolution[J]. Information &Management, 2011, 48(8):371-381.
[③] 杨爱青, 马秀峰, 张风燕,等. g指数在共词分析主题词选取中的应用研究[J]. 情 杂志, 2012, 31(2):52-55.
[④] 李树青, 孙颖. 基于加权关键词共现时间元的个性化学术研究时序路径发现及其可视化呈现方法[J]. 情 学 , 2014, 33(1):55-67.
[⑤] 叶春蕾, 冷伏海. 基于词汇链的路线图关键词抽取方法研究[J]. 现代图书情 技术, 2013, 29(1):50-56.
[⑥] 叶鹰, 张力, 赵星,等. 用共关键词 络揭示领域知识结构的实验研究[J]. 情 学 , 2012, 31(12):1245-1251.
[⑦] Zhu W, Guan J. A bibliometric study of service innovation research:based on complex network analysis[M]. Springer-Verlag New York, Inc. 2013.
[⑧] Law J, Bauin S, Courtial J P, et al. Policy and the mapping ofscientific change: A co-word analysis of research into environmentalacidification[J]. Scientometrics, 1988, 14(3-4):251-264.
[⑨] 马费成, 望俊成, 陈金霞,等. 我国数字信息资源研究的热点领域:共词分析透视[J]. 情 理论与实践, 2007, 30(4):438-443.
[⑩] Tijssen R J W, Raan A F J V. Mapping co-word structures: Acomparison of multidimensional scaling and leximappe[J]. Scientometrics, 1989,15(3-4):283-295.
[11] 魏瑞斌. 国内知识图谱研究的可视化分析[J]. 图书情 工作, 2011, 55(8):126-130.
[12] Bhattacharya S, Kretschmer H, Meyer M. Characterizing intellectualspaces between science and technology[J]. Scientometrics, 2003, 58(2):369-390.
[13]刘志辉, 赵筱媛, 杨阳. 基于 络关系整合的竞争态势分析方法[J]. 图书情 工作, 2011, 55(20):64-67.
[14] Hui S C, Fong A C M. Document retrieval from a citation databaseusing conceptual clustering and co‐word analysis[J].Online Information Review, 2004, 28(1):22-32.
[15]肖伟, 魏庆琦. 学术论文共词分析系统的设计与实现[J]. 情 理论与实践, 2009, 32(3):102-105.
声明:本站部分文章及图片源自用户投稿,如本站任何资料有侵权请您尽早请联系jinwei@zod.com.cn进行处理,非常感谢!